Refine search
Actions for selected content:
293 results
Subject–verb agreement by Turkish speakers of English: Differential cue-weighting in L1 and L2 and distinct mechanisms for comprehension and production
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 08 July 2026, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
I saw, I reported, I inferred: perception verb constructions as evidential strategies in French
-
- Journal:
- Journal of French Language Studies / Volume 36 / 2026
- Published online by Cambridge University Press:
- 07 July 2026, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 6 - Syntax: Basic Concepts
-
- Book:
- An Introduction to Chinese Linguistics
- Published online:
- 26 May 2026
- Print publication:
- 18 June 2026, pp 157-207
-
- Chapter
- Export citation
Chapter 7 - Syntax: Special Topics
-
- Book:
- An Introduction to Chinese Linguistics
- Published online:
- 26 May 2026
- Print publication:
- 18 June 2026, pp 208-248
-
- Chapter
- Export citation
1 - What Is Language?
-
- Book:
- Beyond Words
- Published online:
- 20 May 2026
- Print publication:
- 04 June 2026, pp 10-40
-
- Chapter
- Export citation
18 - The Contributions of Heritage Language Speakers to Second Language Acquisition
- from Part IV - Profiles of Bilinguals
-
-
- Book:
- The Cambridge Handbook of Second Language Acquisition
- Published online:
- 14 May 2026
- Print publication:
- 04 June 2026, pp 427-448
-
- Chapter
- Export citation
7 - Fitting Words Together: Phrase Structure and Meaning
-
- Book:
- Understanding Language through Humor
- Published online:
- 14 May 2026
- Print publication:
- 04 June 2026, pp 162-192
-
- Chapter
- Export citation
No hesitation at the choice point: verb–particle placement is cost-free in production
-
- Journal:
- Language and Cognition / Volume 18 / 2026
- Published online by Cambridge University Press:
- 15 May 2026, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - The Idea of American English
-
- Book:
- The Emergence and Development of American English
- Published online:
- 11 June 2026
- Print publication:
- 14 May 2026, pp 5-21
-
- Chapter
- Export citation
The syntax of quantifiers in Chuj
-
- Journal:
- Canadian Journal of Linguistics/Revue canadienne de linguistique , First View
- Published online by Cambridge University Press:
- 13 May 2026, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper provides a novel description and syntactic analysis of different types of quantifiers in Chuj, an underdocumented Mayan language. We focus on a subset of expressions that quantify over entities, and that have been noted to appear obligatorily in sentence-initial position. We argue that three types of quantifiers should be distinguished: (i) Predicative A-quantifiers, which occur sentence-initially because Chuj is a predicate-initial language; (ii) Focus D-quantifiers, which occur sentence-initially because they are lexically specified for an [A
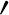 $'$] feature; and (iii) Basic D-quantifiers, which, lacking an [A
$'$] feature; and (iii) Basic D-quantifiers, which, lacking an [A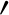 $'$] feature, have no effects on the syntactic position of their host arguments. We also sketch syntactic analyses of each type of quantifier.
$'$] feature, have no effects on the syntactic position of their host arguments. We also sketch syntactic analyses of each type of quantifier.
28 - Shared Mechanisms for the Processing of Rhythm in Music and Speech
- from Section 4 - Diversity of Rhythm from Oral Speech to Music
-
-
- Book:
- Rhythms of Speech and Language
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026, pp 511-532
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
16 - Phrasal Rhythmicity and the Sources of Temporal Intermittency in Speech
- from Section 3 - Rhythm in Prosody and at the Prosody–Syntax Interface
-
-
- Book:
- Rhythms of Speech and Language
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026, pp 274-295
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Against distributed deletion
-
- Journal:
- Journal of Linguistics , First View
- Published online by Cambridge University Press:
- 24 April 2026, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Linear A Syntax and Orthography
- from Part I: - Linguistic Analysis of Linear A
-
- Book:
- The Undeciphered Aegean Scripts
- Published online:
- 20 March 2026
- Print publication:
- 02 April 2026, pp 205-224
-
- Chapter
- Export citation
The syntax of Expletive Negation in English: the case of not-ACC-ing constructions
-
- Journal:
- English Language & Linguistics , First View
- Published online by Cambridge University Press:
- 30 March 2026, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Relative Clauses in Proto-Indo-European
- A Study in Syntactic Reconstruction
-
- Published online:
- 27 March 2026
- Print publication:
- 09 April 2026
-
- Book
-
- You have access
- Open access
- Export citation
11 - The Critical Role of Linguistics in Teacher Preparation
-
-
- Book:
- Linguistic Foundations for Second Language Teaching and Learning
- Published online:
- 07 February 2026
- Print publication:
- 05 March 2026, pp 214-228
-
- Chapter
- Export citation
2 - The Strengths of Functional-Typological Linguistics in L2 Perspective
-
-
- Book:
- Linguistic Foundations for Second Language Teaching and Learning
- Published online:
- 07 February 2026
- Print publication:
- 05 March 2026, pp 29-49
-
- Chapter
- Export citation
12 - Why Linguistics Matters to Second Language Teaching in K-12
-
-
- Book:
- Linguistic Foundations for Second Language Teaching and Learning
- Published online:
- 07 February 2026
- Print publication:
- 05 March 2026, pp 229-247
-
- Chapter
- Export citation
2 - What Is Linguistics?
-
- Book:
- Language and Social Issues
- Published online:
- 02 April 2026
- Print publication:
- 05 March 2026, pp 16-62
-
- Chapter
- Export citation
