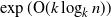Refine search
Actions for selected content:
2 results
Trace reconstruction of matrices and hypermatrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 10 March 2026, pp. 356-374
-
- Article
- Export citation
-
A trace of a sequence is generated by deleting each bit of the sequence independently with a fixed probability. The well-studied trace reconstruction problem asks how many traces are required to reconstruct an unknown binary sequence with high probability. In this paper, we study the multidimensional version of this problem for matrices and hypermatrices, where a trace is generated by deleting each row/column of the matrix or each slice of the hypermatrix independently with a constant probability. Previously, Krishnamurthy, Mazumdar, McGregor and Pal showed that
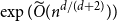 $\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown 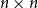 $n\times n$ matrix (for
$n\times n$ matrix (for 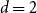 $d=2$) and any unknown
$d=2$) and any unknown 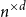 $n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around
$n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around 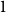 $1$, we improve this upper bound by showing that
$1$, we improve this upper bound by showing that 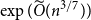 $\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown 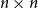 $n\times n$ matrix, and
$n\times n$ matrix, and 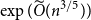 $\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown 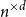 $n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from
$n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from  $1$ even as
$1$ even as  $d$ becomes very large.
$d$ becomes very large.
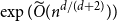
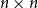
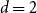
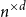
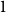
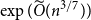
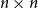
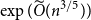
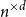
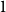
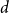
Tree trace reconstruction using subtraces
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 15 December 2022, pp. 629-641
- Print publication:
- June 2023
-
- Article
- Export citation
-
Tree trace reconstruction aims to learn the binary node labels of a tree, given independent samples of the tree passed through an appropriately defined deletion channel. In recent work, Davies, Rácz, and Rashtchian [10] used combinatorial methods to show that
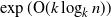 $\exp({\mathrm{O}} (k \log_{k} n))$ samples suffice to reconstruct a complete k-ary tree with n nodes with high probability. We provide an alternative proof of this result, which allows us to generalize it to a broader class of tree topologies and deletion models. In our proofs we introduce the notion of a subtrace, which enables us to connect with and generalize recent mean-based complex analytic algorithms for string trace reconstruction.
$\exp({\mathrm{O}} (k \log_{k} n))$ samples suffice to reconstruct a complete k-ary tree with n nodes with high probability. We provide an alternative proof of this result, which allows us to generalize it to a broader class of tree topologies and deletion models. In our proofs we introduce the notion of a subtrace, which enables us to connect with and generalize recent mean-based complex analytic algorithms for string trace reconstruction.