Refine search
Actions for selected content:
3404 results in Artificial Intelligence and Natural Language Processing
List of Tables
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp xv-xvi
-
- Chapter
- Export citation
15 - Implementing Encoder-Decoder Methods
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 229-245
-
- Chapter
- Export citation
Appendix B - Character Encodings: ASCII and Unicode
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 301-307
-
- Chapter
- Export citation
References
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 308-320
-
- Chapter
- Export citation
Index
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 321-326
-
- Chapter
- Export citation
5 - Feed-Forward Neural Networks
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 73-86
-
- Chapter
- Export citation
Preface
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp xvii-xviii
-
- Chapter
- Export citation
2 - The Perceptron
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 8-29
-
- Chapter
- Export citation
7 - Implementing Text Classification with Feed-Forward Networks
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 107-116
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 1-7
-
- Chapter
-
- You have access
- Export citation
14 - Encoder-Decoder Methods
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 216-228
-
- Chapter
- Export citation
12 - Contextualized Embeddings and Transformer Networks
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 178-193
-
- Chapter
- Export citation
10 - Recurrent Neural Networks
-
- Book:
- Deep Learning for Natural Language Processing
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024, pp 147-164
-
- Chapter
- Export citation

Deep Learning for Natural Language Processing
- A Gentle Introduction
-
- Published online:
- 01 February 2024
- Print publication:
- 08 February 2024
Anisotropic span embeddings and the negative impact of higher-order inference for coreference resolution: An empirical analysis
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 25 January 2024, pp. 1301-1322
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automated annotation of parallel bible corpora with cross-lingual semantic concordance
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 25 January 2024, pp. 1277-1300
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How do control tokens affect natural language generation tasks like text simplification
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 23 January 2024, pp. 915-942
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Emerging trends: When can users trust GPT, and when should they intervene?
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 16 January 2024, pp. 417-427
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lightweight transformers for clinical natural language processing
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 12 January 2024, pp. 887-914
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv: 1910.01108, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from
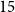 $15$ million to
$15$ million to 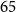 $65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
$65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
Actionable conversational quality indicators for improving task-oriented dialog systems
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 09 January 2024, pp. 1229-1254
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
