Refine search
Actions for selected content:
48178 results in Computer Science
1 - Introduction
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp 1-4
-
- Chapter
- Export citation
10 - Three-dimensional data in SAC
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp 115-122
-
- Chapter
- Export citation
Analysis and feedback of erroneous Arabic verbs
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 2 / March 2015
- Published online by Cambridge University Press:
- 16 September 2013, pp. 271-323
-
- Article
- Export citation
On Independent Sets in Graphs with Given Minimum Degree
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 16 September 2013, pp. 874-884
-
- Article
- Export citation
Relational paraphrase acquisition from Wikipedia: The WRPA method and corpus†
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 16 September 2013, pp. 355-389
-
- Article
- Export citation
Random Colourings and Automorphism Breaking in Locally Finite Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 16 September 2013, pp. 885-909
-
- Article
- Export citation
Bibliography
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp 501-508
-
- Chapter
- Export citation
1 - Essentials of Information Theory
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp 1-143
-
- Chapter
- Export citation
Constructive Packings by Linear Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 12 September 2013, pp. 829-858
-
- Article
- Export citation
-
For k-graphs F0 and H, an F0-packing of H is a family
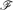 $\mathscr{F}$ of pairwise edge-disjoint copies of F0 in H. Let νF0(H) denote the maximum size |$\mathscr{F}$| of an F0-packing of H. Already in the case of graphs, computing νF0(H) is NP-hard for most fixed F0 (Dor and Tarsi [6]).
$\mathscr{F}$ of pairwise edge-disjoint copies of F0 in H. Let νF0(H) denote the maximum size |$\mathscr{F}$| of an F0-packing of H. Already in the case of graphs, computing νF0(H) is NP-hard for most fixed F0 (Dor and Tarsi [6]).In this paper, we consider the case when F0 is a fixed linear k-graph. We establish an algorithm which, for ζ > 0 and a given k-graph H, constructs in time polynomial in |V(H)| an F0-packing of H of size at least νF0(H) − ζ |V(H)|k. Our result extends one of Haxell and Rödl, who established the analogous algorithm for graphs.
Index
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp 509-514
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp i-iv
-
- Chapter
- Export citation
Preface
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp vii-xii
-
- Chapter
- Export citation
Contents
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp v-vi
-
- Chapter
- Export citation
Large Feedback Arc Sets, High Minimum Degree Subgraphs, and Long Cycles in Eulerian Digraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 12 September 2013, pp. 859-873
-
- Article
- Export citation
2 - Introduction to Coding Theory
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp 144-268
-
- Chapter
- Export citation
3 - Further Topics from Coding Theory
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp 269-365
-
- Chapter
- Export citation
4 - Further Topics from Information Theory
-
- Book:
- Information Theory and Coding by Example
- Published online:
- 05 June 2014
- Print publication:
- 12 September 2013, pp 366-500
-
- Chapter
- Export citation
Network analysis of narrative content in large corpora
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 11 September 2013, pp. 81-112
-
- Article
- Export citation
Commentary: Teach network science to teenagers
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 10 September 2013, pp. 226-247
-
- Article
- Export citation
Classifying Korean comparative sentences for comparison analysis
-
- Journal:
- Natural Language Engineering / Volume 20 / Issue 4 / October 2014
- Published online by Cambridge University Press:
- 09 September 2013, pp. 557-581
-
- Article
- Export citation
