Refine search
Actions for selected content:
48172 results in Computer Science
BigYAP: Exo-compilation meets UDI
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 799-813
-
- Article
- Export citation
Disjunctive logic programs with existential quantification in rule heads
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 563-578
-
- Article
- Export citation
Fuzzy answer sets approximations
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 753-767
-
- Article
- Export citation
Finding optimal plans for multiple teams of robots through a mediator: A logic-based approach
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 831-846
-
- Article
- Export citation
Using sequential runtime distributions for the parallel speedup prediction of SAT local search
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 625-639
-
- Article
- Export citation
Detection and exploitation of functional dependencies for model generation
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 471-485
-
- Article
- Export citation
Lloyd-Topor completion and general stable models
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 503-515
-
- Article
- Export citation
SeaLion: An eclipse-based IDE for answer-set programming with advanced debugging support
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 657-673
-
- Article
- Export citation
A practical analysis of non-termination in large logic programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 705-719
-
- Article
- Export citation
-
A large body of work has been dedicated to termination analysis of logic programs but relatively little has been done to analyze non-termination. In our opinion, explaining non-termination is a much more important task because it can dramatically improve a user's ability to effectively debug large, complex logic programs without having to abide by punishing syntactic restrictions. Non-termination analysis examines program execution history when the program is suspected to not terminate and informs the programmer about the exact reasons for this behavior. In Liang and Kifer (2013), we studied the problem of non-termination in tabled logic engines with subgoal abstraction, such as XSB, and proposed a suite of algorithms for non-termination analysis, called Terminyzer. These algorithms analyze forest logging traces and output sequences of tabled subgoal calls that are the likely causes of non-terminating cycles. However, this feedback was hard to use in practice: the same subgoal could occur in multiple rule heads and in even more places in rule bodies, so Terminyzer left too much tedious, sometimes combinatorially large amount of work for the user to do manually.
Here we propose a new suite of algorithms, Terminyzer+, which closes this usability gap. Terminyzer+ can detect not only sequences of subgoals that cause non-termination, but, importantly, the exact rules where they occur and the rule sequences that get fired in a cyclic manner, thus causing non-termination. This makes Terminyzer+ suitable as a back-end for user-friendly graphical interfaces on top of Terminyzer+, which can greatly simplify the debugging process. Terminyzer+ back-ends exist for the SILK system as well as for the open-source
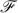 ${\cal F}$lora-2 system. A graphical interface has been developed for SILK and is currently underway for ${\cal F}$lora-2. We also report experimental studies, which confirm the effectiveness of Terminyzer+ on a host of large real-world knowledge bases. All tests used in this paper are available online.1
${\cal F}$lora-2 system. A graphical interface has been developed for SILK and is currently underway for ${\cal F}$lora-2. We also report experimental studies, which confirm the effectiveness of Terminyzer+ on a host of large real-world knowledge bases. All tests used in this paper are available online.1In addition, we make a step towards automatic remediation of non-terminating programs by proposing an algorithm that heuristically fixes some causes of misbehavior. Furthermore, unlike Terminyzer, Terminyzer+ does not require the underlying logic engine to support subgoal abstraction, although it can make use of it.
Compiling Input* FO(·) inductive definitions into tabled prolog rules for IDP3
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 691-704
-
- Article
- Export citation
A declarative extension of horn clauses, and its significance for datalog and its applications
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 609-623
-
- Article
- Export citation
PES volume 27 issue 4 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 4 / October 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Business process verification with constraint temporal answer set programming*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 13 / Issue 4-5 / July 2013
- Published online by Cambridge University Press:
- 25 September 2013, pp. 641-655
-
- Article
- Export citation
SET SIZE AND THE PART–WHOLE PRINCIPLE
-
- Journal:
- The Review of Symbolic Logic / Volume 6 / Issue 4 / December 2013
- Published online by Cambridge University Press:
- 20 September 2013, pp. 589-612
- Print publication:
- December 2013
-
- Article
- Export citation
Appendix B - Keyword in context for SAC command descriptions
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp 142-166
-
- Chapter
- Export citation
Concentration of Lipschitz Functionals of Determinantal and Other Strong Rayleigh Measures
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 September 2013, pp. 140-160
-
- Article
- Export citation
-
Let {X1 , . . , Xn} be a collection of binary-valued random variables and let f : {0, 1}n →
 $\mathbb{R}$ be a Lipschitz function. Under a negative dependence hypothesis known as the strong Rayleigh condition, we show that f −
$\mathbb{R}$ be a Lipschitz function. Under a negative dependence hypothesis known as the strong Rayleigh condition, we show that f −  ${\mathbb E}$f satisfies a concentration inequality. The class of strong Rayleigh measures includes determinantal measures, weighted uniform matroids and exclusion measures; some familiar examples from these classes are generalized negative binomials and spanning tree measures. For instance, any Lipschitz-1 function of the edges of a uniform spanning tree on vertex set V (e.g., the number of leaves) satisfies the Gaussian concentration inequalityWe also prove a continuous version for concentration of Lipschitz functionals of a determinantal point process.
${\mathbb E}$f satisfies a concentration inequality. The class of strong Rayleigh measures includes determinantal measures, weighted uniform matroids and exclusion measures; some familiar examples from these classes are generalized negative binomials and spanning tree measures. For instance, any Lipschitz-1 function of the edges of a uniform spanning tree on vertex set V (e.g., the number of leaves) satisfies the Gaussian concentration inequalityWe also prove a continuous version for concentration of Lipschitz functionals of a determinantal point process.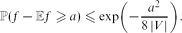 \begin{linenomath}$${{\mathbb P} (f - {\mathbb E} f \geq a) \leq \exp \biggl( - \frac{a^2}{8 \, |V|} \biggr) }.$$\end{linenomath}
\begin{linenomath}$${{\mathbb P} (f - {\mathbb E} f \geq a) \leq \exp \biggl( - \frac{a^2}{8 \, |V|} \biggr) }.$$\end{linenomath}


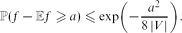
Acknowledgements
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp xi-xii
-
- Chapter
- Export citation
Index
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp 170-173
-
- Chapter
- Export citation
11 - Implementation of common processing methodologies using SAC
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp 123-134
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- The Seismic Analysis Code
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013, pp i-iv
-
- Chapter
- Export citation
