Refine search
Actions for selected content:
48202 results in Computer Science
Authorship analysis of aliases: Does topic influence accuracy?
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 4 / August 2015
- Published online by Cambridge University Press:
- 08 October 2013, pp. 497-518
-
- Article
- Export citation
Constructing Gröbner bases for Noetherian rings†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 08 October 2013, e240206
-
- Article
- Export citation
Unfolding for CHR programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 15 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 08 October 2013, pp. 264-311
-
- Article
- Export citation
Property-oriented semantics of structured specifications†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 24 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 08 October 2013, e240205
-
- Article
- Export citation
NWS volume 1 issue 2 Cover and Back matter
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 07 October 2013, pp. b1-b2
-
- Article
-
- You have access
- Export citation
NWS volume 1 issue 2 Cover and Front matter
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 07 October 2013, pp. f1-f4
-
- Article
-
- You have access
- Export citation
Near-Optimal Separators in String Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 07 October 2013, pp. 135-139
-
- Article
- Export citation
-
Let G be a string graph (an intersection graph of continuous arcs in the plane) with m edges. Fox and Pach proved that G has a separator consisting of
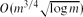 $O(m^{3/4}\sqrt{\log m})$ vertices, and they conjectured that the bound of
$O(m^{3/4}\sqrt{\log m})$ vertices, and they conjectured that the bound of 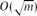 $O(\sqrt m)$ actually holds. We obtain separators with
$O(\sqrt m)$ actually holds. We obtain separators with 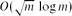 $O(\sqrt m \,\log m)$ vertices.
$O(\sqrt m \,\log m)$ vertices.
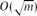
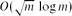
What we publish
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 07 October 2013, pp. 123-124
-
- Article
-
- You have access
- Export citation

Who's Bigger?
- Where Historical Figures Really Rank
-
- Published online:
- 05 October 2013
- Print publication:
- 14 October 2013

Mobility Data
- Modeling, Management, and Understanding
-
- Published online:
- 05 October 2013
- Print publication:
- 14 October 2013

Parallel Scientific Computing in C++ and MPI
- A Seamless Approach to Parallel Algorithms and their Implementation
-
- Published online:
- 05 October 2013
- Print publication:
- 16 June 2003

The Seismic Analysis Code
- A Primer and User's Guide
-
- Published online:
- 05 October 2013
- Print publication:
- 19 September 2013

Brain-Computer Interfacing
- An Introduction
-
- Published online:
- 05 October 2013
- Print publication:
- 30 September 2013

The Discrepancy Method
- Randomness and Complexity
-
- Published online:
- 05 October 2013
- Print publication:
- 24 July 2000
ROB volume 31 issue 7 Cover and Front matter
-
- Article
-
- You have access
- Export citation
ROB volume 31 issue 7 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Editorial
-
- Article
-
- You have access
- Export citation
CPC volume 22 issue 6 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 01 October 2013, pp. b1-b8
-
- Article
-
- You have access
- Export citation
