Refine search
Actions for selected content:
48179 results in Computer Science

Body Area Networks
- Safety, Security, and Sustainability
-
- Published online:
- 05 April 2013
- Print publication:
- 18 April 2013

Computation and Automata
-
- Published online:
- 05 April 2013
- Print publication:
- 23 May 1985
On the Swap-Distances of Different Realizations of a Graphical Degree Sequence
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. 366-383
-
- Article
- Export citation
CPC volume 22 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. b1-b6
-
- Article
-
- You have access
- Export citation
Normal Numbers and the Normality Measure
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. 342-345
-
- Article
- Export citation
-
In a paper published in this journal, Alon, Kohayakawa, Mauduit, Moreira and Rödl proved that the minimal possible value of the normality measure of an N-element binary sequence satisfies
for sufficiently large N, and conjectured that the lower bound can be improved to some power of N. In this note it is observed that a construction of Levin of a normal number having small discrepancy gives a construction of a binary sequence EN with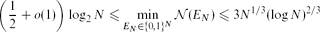 \begin{equation*}\biggl( \frac{1}{2} + o(1) \biggr) \log_2 N \leq \min_{E_N \in \{0,1\}^N} \mathcal{N}(E_N) \leq 3 N^{1/3} (\log N)^{2/3}\end{equation*}
\begin{equation*}\biggl( \frac{1}{2} + o(1) \biggr) \log_2 N \leq \min_{E_N \in \{0,1\}^N} \mathcal{N}(E_N) \leq 3 N^{1/3} (\log N)^{2/3}\end{equation*}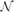
CPC volume 22 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. f1-f2
-
- Article
-
- You have access
- Export citation

Quantum Computing since Democritus
-
- Published online:
- 05 April 2013
- Print publication:
- 14 March 2013
A multidisciplinary survey on discrimination analysis
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 5 / November 2014
- Published online by Cambridge University Press:
- 03 April 2013, pp. 582-638
-
- Article
- Export citation
Decidability of the HD0L ultimateperiodicity problem
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 25 April 2013, pp. 201-214
- Print publication:
- April 2013
-
- Article
- Export citation
A note on constructing infinite binary words with polynomial subword complexity∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 25 April 2013, pp. 195-199
- Print publication:
- April 2013
-
- Article
- Export citation
Part 2 - Other players: roles and responsibilities
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 115-116
-
- Chapter
- Export citation
2 - Supporting qualitative research in the humanities and social sciences: using the Mass Observation Archive
- from Part 1 - Changing researcher behaviour
-
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 25-38
-
- Chapter
- Export citation
13 - The library users’ view
- from Part 2 - Other players: roles and responsibilities
-
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 169-178
-
- Chapter
- Export citation
Contributors
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp vii-xii
-
- Chapter
- Export citation
8 - The changing role of the publisher in the scholarly communications process
- from Part 1 - Changing researcher behaviour
-
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 103-114
-
- Chapter
- Export citation
11 - Changing institutional research strategies
- from Part 2 - Other players: roles and responsibilities
-
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 145-156
-
- Chapter
- Export citation
Index
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 179-188
-
- Chapter
- Export citation
Introduction: Scholarly communications – disruptions in a complex ecology
-
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp xiii-xxxvi
-
- Chapter
- Export citation
7 - Social media and scholarly communications: the more they change, the more they stay the same?
- from Part 1 - Changing researcher behaviour
-
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp 89-102
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- The Future of Scholarly Communication
- Published by:
- Facet
- Published online:
- 08 June 2018
- Print publication:
- 31 March 2013, pp i-ii
-
- Chapter
- Export citation
