Refine search
Actions for selected content:
48202 results in Computer Science
3 - A first tour of topology: metric spaces
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 18-45
-
- Chapter
- Export citation
7 - Completeness
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 260-340
-
- Chapter
- Export citation
A NOTE ON BIVARIATE DUAL GENERALIZED MARSHALL–OLKIN DISTRIBUTIONS WITH APPLICATIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 367-374
-
- Article
- Export citation
References
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 475-479
-
- Chapter
- Export citation
SINGLE-MACHINE MULTIPLE-RECIPE PREDICTIVE MAINTENANCE
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 209-235
-
- Article
- Export citation
STOCHASTIC SEQUENTIAL ASSIGNMENT PROBLEM WITH THRESHOLD CRITERIA
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 277-296
-
- Article
- Export citation
4 - Topology
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 46-119
-
- Chapter
- Export citation
A BALANCE SCALE PROBLEM
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 141-146
-
- Article
- Export citation
2 - Elements of set theory
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 4-17
-
- Chapter
- Export citation
Contents
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp v-vi
-
- Chapter
- Export citation
DRAWING MULTISETS OF BALLS FROM TENABLE BALANCED LINEAR URNS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 147-162
-
- Article
- Export citation
-
We investigate the evolution of an urn of balls of two colors, where one chooses a pair of balls and observes rules of ball addition according to the outcome. A nonsquare ball addition matrix of the form
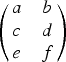 $\left( \matrix{a & b \cr c & d \cr e & f}\right)$ corresponds to such a scheme, in contrast to pólya urn models that possess a square ball addition matrix. We look into the case of constant row sum (the so-called balanced urns) and identify a linear case therein. Two cases arise in linear urns: the nondegenerate and the degenerate. Via martingales, in the nondegenerate case one gets an asymptotic normal distribution for the number of balls of any color. In the degenerate case, a simpler probability structure underlies the process. We mention in passing a heuristic for the average-case analysis for the general case of constant row sum.
$\left( \matrix{a & b \cr c & d \cr e & f}\right)$ corresponds to such a scheme, in contrast to pólya urn models that possess a square ball addition matrix. We look into the case of constant row sum (the so-called balanced urns) and identify a linear case therein. Two cases arise in linear urns: the nondegenerate and the degenerate. Via martingales, in the nondegenerate case one gets an asymptotic normal distribution for the number of balls of any color. In the degenerate case, a simpler probability structure underlies the process. We mention in passing a heuristic for the average-case analysis for the general case of constant row sum.
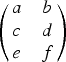
DYNAMIC ANALYSIS OF A MULTIVARIATE REWARD PROCESS DEFINED ON THE UMCP WITH APPLICATION TO OPTIMAL PREVENTIVE MAINTENANCE POLICY PROBLEMS IN MANUFACTURING
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 187-208
-
- Article
- Export citation
9 - Stably compact spaces and compact pospaces
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 397-474
-
- Chapter
- Export citation
PES volume 27 issue 2 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. f1-f2
-
- Article
-
- You have access
- Export citation
5 - Approximation and function spaces
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 120-202
-
- Chapter
- Export citation
THE ZAGREB INDICES OF RANDOM GRAPHS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 247-260
-
- Article
- Export citation
1 - Introduction
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 1-3
-
- Chapter
- Export citation
ON A CLASS OF GENERALIZED MARSHALL–OLKIN BIVARIATE DISTRIBUTIONS AND SOME RELIABILITY CHARACTERISTICS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 261-275
-
- Article
- Export citation
Notation index
-
- Book:
- Non-Hausdorff Topology and Domain Theory
- Published online:
- 05 May 2013
- Print publication:
- 28 March 2013, pp 480-483
-
- Chapter
- Export citation
SOME NEW APPLICATIONS OF P–P PLOTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 28 March 2013, pp. 353-366
-
- Article
- Export citation
