Refine search
Actions for selected content:
48287 results in Computer Science
2 - Inductive Definitions
- from Part I - Judgments and Rules
-
- Book:
- Practical Foundations for Programming Languages
- Published online:
- 05 February 2013
- Print publication:
- 17 December 2012, pp 11-19
-
- Chapter
- Export citation
16 - Recursive Types
- from Part V - Infinite Data Types
-
- Book:
- Practical Foundations for Programming Languages
- Published online:
- 05 February 2013
- Print publication:
- 17 December 2012, pp 116-124
-
- Chapter
- Export citation
42 - Concurrent Algol
- from Part XVI - Concurrency
-
- Book:
- Practical Foundations for Programming Languages
- Published online:
- 05 February 2013
- Print publication:
- 17 December 2012, pp 363-372
-
- Chapter
- Export citation
3 - Hypothetical and General Judgments
- from Part I - Judgments and Rules
-
- Book:
- Practical Foundations for Programming Languages
- Published online:
- 05 February 2013
- Print publication:
- 17 December 2012, pp 20-28
-
- Chapter
- Export citation
MSC volume 23 issue 1 Cover and Front matter
-
- Journal:
- Mathematical Structures in Computer Science / Volume 23 / Issue 1 / February 2013
- Published online by Cambridge University Press:
- 14 December 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
MSC volume 23 issue 1 Cover and Back matter
-
- Journal:
- Mathematical Structures in Computer Science / Volume 23 / Issue 1 / February 2013
- Published online by Cambridge University Press:
- 14 December 2012, pp. b1-b7
-
- Article
-
- You have access
- Export citation
Using the crowd for readability prediction
-
- Journal:
- Natural Language Engineering / Volume 20 / Issue 3 / July 2014
- Published online by Cambridge University Press:
- 14 December 2012, pp. 293-325
-
- Article
- Export citation
Using morphemes in language modeling and automatic speech recognition of Amharic
-
- Journal:
- Natural Language Engineering / Volume 20 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 12 December 2012, pp. 235-259
-
- Article
- Export citation
ON ORDERINGS BETWEEN WEIGHTED SUMS OF RANDOM VARIABLES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 10 December 2012, pp. 85-97
-
- Article
- Export citation
THE SEQUENTIAL STOCHASTIC ASSIGNMENT PROBLEM WITH POSTPONEMENT OPTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 10 December 2012, pp. 25-51
-
- Article
- Export citation
ANALYTIC PROPERTIES OF TWO-CAROUSEL SYSTEMS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 10 December 2012, pp. 57-84
-
- Article
- Export citation
A MARKOV CHAIN CHOICE PROBLEM
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 27 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 10 December 2012, pp. 53-55
-
- Article
- Export citation
Applications of the Semi-Definite Method to the Turán Density Problem for 3-Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 07 December 2012, pp. 21-54
-
- Article
- Export citation
-
In this paper, we prove several new Turán density results for 3-graphs with independent neighbourhoods. We show:
where Jt is the 3-graph consisting of a single vertex x together with a disjoint set A of size t and all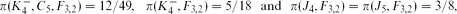 \begin{align*}\pi (K_4^-, C_5, F_{3,2})=12/49, \pi (K_4^-, F_{3,2})=5/18 \textrm {and} \pi (J_4, F_{3,2})=\pi (J_5, F_{3,2})=3/8,\end{align*}
\begin{align*}\pi (K_4^-, C_5, F_{3,2})=12/49, \pi (K_4^-, F_{3,2})=5/18 \textrm {and} \pi (J_4, F_{3,2})=\pi (J_5, F_{3,2})=3/8,\end{align*} $\binom{|A|}{2}$ 3-edges containing x. We also prove two Turán density results where we forbid certain induced subgraphs:The latter result is an analogue for K5 of Razborov's result that
$\binom{|A|}{2}$ 3-edges containing x. We also prove two Turán density results where we forbid certain induced subgraphs:The latter result is an analogue for K5 of Razborov's result that \begin{align*}\pi (F_{3,2}, \textrm { induced }K_4^-)=3/8 \textrm {and} \pi (K_5, 5\textrm {-set spanning exactly 8 edges})=3/4.\end{align*}We give several new constructions, conjectures and bounds for Turán densities of 3-graphs which should be of interest to researchers in the area. Our main tool is ‘Flagmatic’, an implementation of Razborov's semi-definite method, which we are making publicly available. In a bid to make the power of Razborov's method more widely accessible, we have tried to make Flagmatic as user-friendly as possible, hoping to remove thereby the major hurdle that needs to be cleared before using the semi-definite method. Finally, we spend some time reflecting on the limitations of our approach, and in particular on which problems we may be unable to solve. Our discussion of the ‘complexity barrier’ for the semi-definite method may be of general interest.
\begin{align*}\pi (F_{3,2}, \textrm { induced }K_4^-)=3/8 \textrm {and} \pi (K_5, 5\textrm {-set spanning exactly 8 edges})=3/4.\end{align*}We give several new constructions, conjectures and bounds for Turán densities of 3-graphs which should be of interest to researchers in the area. Our main tool is ‘Flagmatic’, an implementation of Razborov's semi-definite method, which we are making publicly available. In a bid to make the power of Razborov's method more widely accessible, we have tried to make Flagmatic as user-friendly as possible, hoping to remove thereby the major hurdle that needs to be cleared before using the semi-definite method. Finally, we spend some time reflecting on the limitations of our approach, and in particular on which problems we may be unable to solve. Our discussion of the ‘complexity barrier’ for the semi-definite method may be of general interest.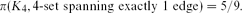 \begin{align*}\pi (K_4, 4\textrm {-set spanning exactly 1 edge})=5/9.\end{align*}
\begin{align*}\pi (K_4, 4\textrm {-set spanning exactly 1 edge})=5/9.\end{align*}


CPC volume 22 issue 1 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 07 December 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Improved Mixing Time Bounds for the Thorp Shuffle
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 07 December 2012, pp. 118-132
-
- Article
- Export citation
A Multipartite Version of the Hajnal–Szemerédi Theorem for Graphs and Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 07 December 2012, pp. 97-111
-
- Article
- Export citation
-
A perfect Kt-matching in a graph G is a spanning subgraph consisting of vertex-disjoint copies of Kt. A classic theorem of Hajnal and Szemerédi states that if G is a graph of order n with minimum degree δ(G) ≥ (t − 1)n/t and t|n, then G contains a perfect Kt-matching. Let G be a t-partite graph with vertex classes V1, …, Vt each of size n. We show that, for any γ > 0, if every vertex x ∈ Vi is joined to at least
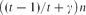 $\bigl ((t-1)/t + \gamma \bigr )n$ vertices of Vj for each j ≠ i, then G contains a perfect Kt-matching, provided n is large enough. Thus, we verify a conjecture of Fischer [6] asymptotically. Furthermore, we consider a generalization to hypergraphs in terms of the codegree.
$\bigl ((t-1)/t + \gamma \bigr )n$ vertices of Vj for each j ≠ i, then G contains a perfect Kt-matching, provided n is large enough. Thus, we verify a conjecture of Fischer [6] asymptotically. Furthermore, we consider a generalization to hypergraphs in terms of the codegree.
CPC volume 22 issue 1 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 07 December 2012, pp. b1-b4
-
- Article
-
- You have access
- Export citation
Preface
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 06 December 2012, pp. 1-2
- Print publication:
- January 2013
-
- Article
-
- You have access
- Export citation
JFP volume 23 issue 1 Cover and Front matter
-
- Journal:
- Journal of Functional Programming / Volume 23 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 05 December 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation

Data-Intensive Computing
- Architectures, Algorithms, and Applications
-
- Published online:
- 05 December 2012
- Print publication:
- 29 October 2012
