Refine search
Actions for selected content:
48284 results in Computer Science
The Largest Minimum Codegree of a 3-Graph Without a Generalized 4-Cycle
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 19 October 2012, pp. 112-117
-
- Article
- Export citation
Metamorphism in jigsaw
-
- Journal:
- Journal of Functional Programming / Volume 23 / Issue 2 / March 2013
- Published online by Cambridge University Press:
- 19 October 2012, pp. 161-173
-
- Article
-
- You have access
- Export citation
ARITHMETICAL INTERPRETATIONS AND KRIPKE FRAMES OF PREDICATE MODAL LOGIC OF PROVABILITY
-
- Journal:
- The Review of Symbolic Logic / Volume 6 / Issue 1 / March 2013
- Published online by Cambridge University Press:
- 12 October 2012, pp. 129-146
- Print publication:
- March 2013
-
- Article
- Export citation
-
Solovay proved the arithmetical completeness theorem for the system GL of propositional modal logic of provability. Montagna proved that this completeness does not hold for a natural extension QGL of GL to the predicate modal logic. Let Th(QGL) be the set of all theorems of QGL, Fr(QGL) be the set of all formulas valid in all transitive and conversely well-founded Kripke frames, and let PL(T) be the set of all predicate modal formulas provable in Tfor any arithmetical interpretation. Montagna’s results are described as Th(QGL) ⊊ (Fr(QGL), PL(PA) ⊈ Fr(QGL), and Th(QGL) ⊊ PL(PA).
In this paper, we prove the following three theorems: (1) Fr(QGL) ⊈ PL(T) for any Σ1-sound recursively enumerable extension T of I Σ1, (2) PL(T) ⊈ Fr(QGL) for any recursively enumerable
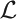 A-theory T extending I Σ1, and (3) Th(QGL) ⊊ Fr(QGL) ∩ PL(T) for any recursively enumerable
A-theory T extending I Σ1, and (3) Th(QGL) ⊊ Fr(QGL) ∩ PL(T) for any recursively enumerable 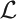 A-theory T extending I Σ2.
A-theory T extending I Σ2.To prove these theorems, we use iterated consistency assertions and nonstandard models of arithmetic, and we improve Artemov’s lemma which is used to prove Vardanyan’s theorem on the Π02-completeness of PL(T).
THE SUBFORMULA PROPERTY IN CLASSICAL NATURAL DEDUCTION ESTABLISHED CONSTRUCTIVELY
-
- Journal:
- The Review of Symbolic Logic / Volume 5 / Issue 4 / December 2012
- Published online by Cambridge University Press:
- 12 October 2012, pp. 710-719
- Print publication:
- December 2012
-
- Article
- Export citation
Modeling human newspaper readers: The Fuzzy Believer approach
-
- Journal:
- Natural Language Engineering / Volume 20 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 12 October 2012, pp. 261-288
-
- Article
- Export citation
JFP volume 22 issue 6 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 11 October 2012, pp. b1-b5
-
- Article
-
- You have access
- Export citation
JFP volume 22 issue 6 Cover and Front matter
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 11 October 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Hypergraph Independent Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 11 October 2012, pp. 9-20
-
- Article
- Export citation
MRI: Modular reasoning about interference in incremental programming
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 11 October 2012, pp. 797-852
-
- Article
-
- You have access
- Export citation
Syntactic soundness proof of a type-and-capability system with hidden state
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 23 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 10 October 2012, pp. 38-144
-
- Article
-
- You have access
- Export citation
Context identification of sentences in research articles: Towards developing intelligent tools for the research community
-
- Journal:
- Natural Language Engineering / Volume 19 / Issue 4 / October 2013
- Published online by Cambridge University Press:
- 10 October 2012, pp. 481-515
-
- Article
- Export citation
Explorations in lexical sample and all-words lexical substitution
-
- Journal:
- Natural Language Engineering / Volume 20 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 09 October 2012, pp. 99-129
-
- Article
- Export citation
A categorical analogue of the monoid semiring construction
-
- Journal:
- Mathematical Structures in Computer Science / Volume 23 / Issue 1 / February 2013
- Published online by Cambridge University Press:
- 09 October 2012, pp. 55-94
-
- Article
- Export citation
Probably Intersecting Families are Not Nested
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 09 October 2012, pp. 146-160
-
- Article
- Export citation
-
It is well known that an intersecting family of subsets of an n-element set can contain at most 2n−1 sets. It is natural to wonder how ‘close’ to intersecting a family of size greater than 2n−1 can be. Katona, Katona and Katona introduced the idea of a ‘most probably intersecting family’. Suppose that
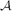
Katona, Katona and Katona conjectured that there is a nested sequence consisting of most probably intersecting families of every possible size. We show that this conjecture is false for every value of p provided that n is sufficiently large.
22 - A Simplified DLX: Implementation
- from PART IV - A SIMPLIFIED DLX
-
- Book:
- Digital Logic Design
- Published online:
- 05 November 2012
- Print publication:
- 08 October 2012, pp 323-342
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Digital Logic Design
- Published online:
- 05 November 2012
- Print publication:
- 08 October 2012, pp i-iv
-
- Chapter
- Export citation
13 - Decoders and Encoders
- from PART II - COMBINATIONAL CIRCUITS
-
- Book:
- Digital Logic Design
- Published online:
- 05 November 2012
- Print publication:
- 08 October 2012, pp 184-200
-
- Chapter
- Export citation
