Refine search
Actions for selected content:
48202 results in Computer Science
7 - Fundamental thresholds in compressed sensing: a high-dimensional geometry approach
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 305-347
-
- Chapter
- Export citation
Preface
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp ix-xii
-
- Chapter
- Export citation
Singular and plural functions for functional logic programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 14 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 17 May 2012, pp. 65-116
-
- Article
- Export citation
9 - Graphical models concepts in compressed sensing
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 394-438
-
- Chapter
- Export citation
Contents
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp v-vi
-
- Chapter
- Export citation
2 - Second-generation sparse modeling: structured and collaborative signal analysis
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 65-87
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp i-iv
-
- Chapter
- Export citation
11 - Data separation by sparse representations
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 485-514
-
- Chapter
- Export citation
List of contributors
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp vii-viii
-
- Chapter
- Export citation
4 - Sampling at the rate of innovation: theory and applications
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 148-209
-
- Chapter
- Export citation
1 - Introduction to compressed sensing
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 1-64
-
- Chapter
- Export citation
8 - Greedy algorithms for compressed sensing
-
-
- Book:
- Compressed Sensing
- Published online:
- 05 November 2012
- Print publication:
- 17 May 2012, pp 348-393
-
- Chapter
- Export citation
A SOLUTION TO THE SURPRISE EXAM PARADOX IN CONSTRUCTIVE MATHEMATICS
-
- Journal:
- The Review of Symbolic Logic / Volume 5 / Issue 4 / December 2012
- Published online by Cambridge University Press:
- 16 May 2012, pp. 679-686
- Print publication:
- December 2012
-
- Article
- Export citation
Perfect Graphs of Fixed Density: Counting and Homogeneous Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 14 May 2012, pp. 661-682
-
- Article
- Export citation
-
For c ∈ (0,1) let
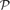

We show that
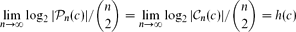 with
with 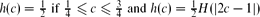
Further, we use this result to deduce that almost all graphs in
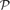

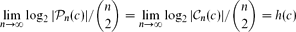
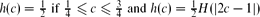
Reinhard Köhler. Quantitative Syntax Analysis. Mouton de Gruyter, Berlin/Boston, 2012, x + 224 pp., €99.95/US$ 140.00, ISBN: 978-3-11-027219-2
-
- Journal:
- Natural Language Engineering / Volume 19 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 14 May 2012, pp. 143-146
-
- Article
- Export citation
Statistical Translation After Source Reordering: Oracles, Context-Aware Models, and Empirical Analysis
-
- Journal:
- Natural Language Engineering / Volume 18 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 14 May 2012, pp. 491-519
-
- Article
- Export citation
JFP volume 22 issue 2 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 2 / March 2012
- Published online by Cambridge University Press:
- 09 May 2012, pp. b1-b7
-
- Article
-
- You have access
- Export citation
Drawing Programs: The Theory and Practice of Schematic Functional Programming, by Tom Addis and Jan Addis Springer, 2010, ISBN 978-1-84882-617-5, 379pp
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 2 / March 2012
- Published online by Cambridge University Press:
- 09 May 2012, pp. 219-221
-
- Article
-
- You have access
- Export citation
