Refine search
Actions for selected content:
48287 results in Computer Science

The Map-Building and Exploration Strategies of a Simple Sonar-Equipped Mobile Robot
- An Experimental, Quantitative Evaluation
-
- Published online:
- 05 March 2012
- Print publication:
- 26 July 1996

Density Ratio Estimation in Machine Learning
-
- Published online:
- 05 March 2012
- Print publication:
- 20 February 2012

Adaptive Technologies for Training and Education
-
- Published online:
- 05 March 2012
- Print publication:
- 20 February 2012

EMBOSS Administrator's Guide
- Bioinformatics Software Management
-
- Published online:
- 05 March 2012
- Print publication:
- 16 June 2011
NORMAL DERIVABILITY IN CLASSICAL NATURAL DEDUCTION
-
- Journal:
- The Review of Symbolic Logic / Volume 5 / Issue 2 / June 2012
- Published online by Cambridge University Press:
- 05 March 2012, pp. 205-211
- Print publication:
- June 2012
-
- Article
- Export citation

Simple Theories and Hyperimaginaries
-
- Published online:
- 05 March 2012
- Print publication:
- 30 June 2011

Perception as Bayesian Inference
-
- Published online:
- 05 March 2012
- Print publication:
- 13 September 1996
Equivalences and Congruences on Infinite Conway Games∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 02 March 2012, pp. 231-259
- Print publication:
- April 2012
-
- Article
- Export citation
The Density Turán Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 29 February 2012, pp. 531-553
-
- Article
- Export citation
-
Let H be a graph on n vertices and let the blow-up graph G[H] be defined as follows. We replace each vertex vi of H by a cluster Ai and connect some pairs of vertices of Ai and Aj if (vi,vj) is an edge of the graph H. As usual, we define the edge density between Ai and Aj as
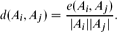 We study the following problem. Given densities γij for each edge (i,j) ∈ E(H), one has to decide whether there exists a blow-up graph G[H], with edge densities at least γij, such that one cannot choose a vertex from each cluster, so that the obtained graph is isomorphic to H, i.e., no H appears as a transversal in G[H]. We call dcrit(H) the maximal value for which there exists a blow-up graph G[H] with edge densities d(Ai,Aj)=dcrit(H) ((vi,vj) ∈ E(H)) not containing H in the above sense. Our main goal is to determine the critical edge density and to characterize the extremal graphs.
We study the following problem. Given densities γij for each edge (i,j) ∈ E(H), one has to decide whether there exists a blow-up graph G[H], with edge densities at least γij, such that one cannot choose a vertex from each cluster, so that the obtained graph is isomorphic to H, i.e., no H appears as a transversal in G[H]. We call dcrit(H) the maximal value for which there exists a blow-up graph G[H] with edge densities d(Ai,Aj)=dcrit(H) ((vi,vj) ∈ E(H)) not containing H in the above sense. Our main goal is to determine the critical edge density and to characterize the extremal graphs.First, in the case of tree T we give an efficient algorithm to decide whether a given set of edge densities ensures the existence of a transversal T in the blow-up graph. Then we give general bounds on dcrit(H) in terms of the maximal degree. In connection with the extremal structure, the so-called star decomposition is proved to give the best construction for H-transversal-free blow-up graphs for several graph classes. Our approach applies algebraic graph-theoretical, combinatorial and probabilistic tools.
A compiled implementation of normalisation by evaluation*
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 29 February 2012, pp. 9-30
-
- Article
-
- You have access
- Export citation
Preface to special issue: EXPRESS, ICE and SOS 2009
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 123-124
-
- Article
-
- You have access
- Export citation
MSC volume 22 issue 2 Cover and Front matter
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
A hierarchy of reverse bisimulations on stable configuration structures
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 333-372
-
- Article
- Export citation
Almost linear Büchi automata
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 203-235
-
- Article
- Export citation
Proving the validity of equations in GSOS languages using rule-matching bisimilarity
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 291-331
-
- Article
- Export citation
Characteristic formulae for fixed-point semantics: a general framework
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 125-173
-
- Article
- Export citation
Modal logic and the approximation induction principle
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 175-201
-
- Article
- Export citation
MSC volume 22 issue 2 Cover and Back matter
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. b1-b8
-
- Article
-
- You have access
- Export citation
On projecting processes into session types
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 28 February 2012, pp. 237-289
-
- Article
- Export citation
Detachments of Hypergraphs I: The Berge–Johnson Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 27 February 2012, pp. 483-495
-
- Article
- Export citation
-
A detachment of a hypergraph is formed by splitting each vertex into one or more subvertices, and sharing the incident edges arbitrarily among the subvertices. For a given edge-coloured hypergraph
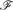
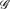
Let
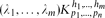 be a hypergraph with vertex partition {V1,. . .,Vn}, |Vi| = pi for 1 ≤ i ≤ n such that there are λi edges of size hi incident with every hi vertices, at most one vertex from each part for 1 ≤ i ≤ m (so no edge is incident with more than one vertex of a part). We use our detachment theorem to show that the obvious necessary conditions for
be a hypergraph with vertex partition {V1,. . .,Vn}, |Vi| = pi for 1 ≤ i ≤ n such that there are λi edges of size hi incident with every hi vertices, at most one vertex from each part for 1 ≤ i ≤ m (so no edge is incident with more than one vertex of a part). We use our detachment theorem to show that the obvious necessary conditions for 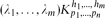 to be expressed as the union
to be expressed as the union
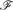
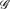
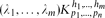 be a hypergraph with vertex partition {
be a hypergraph with vertex partition {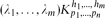 to be expressed as the union
to be expressed as the union 