Refine search
Actions for selected content:
48529 results in Computer Science
An intrinsically non minimal-time Minsky-like 6-states solution to the Firing Squad synchronization problem
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 18 January 2008, pp. 55-68
- Print publication:
- January 2008
-
- Article
- Export citation
Efficient execution in an automated reasoning environment
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 18 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 15-46
-
- Article
-
- You have access
- Export citation
Applicative programming with effects
-
- Journal:
- Journal of Functional Programming / Volume 18 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 1-13
-
- Article
-
- You have access
- Export citation
Enumerating Contingency Tables via Random Permanents
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 1-19
-
- Article
- Export citation
-
Given m positive integers R = (ri), n positive integers C = (cj) such that Σri = Σcj = N, and mn non-negative weights W=(wij), we consider the total weight T=T(R, C; W) of non-negative integer matrices D=(dij) with the row sums ri, column sums cj, and the weight of D equal to
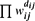 . For different choices of R, C, and W, the quantity T(R,C; W) specializes to the permanent of a matrix, the number of contingency tables with prescribed margins, and the number of integer feasible flows in a network. We present a randomized algorithm whose complexity is polynomial in N and which computes a number T′=T′(R,C;W) such that T′ ≤ T ≤ α(R,C)T′ where
. For different choices of R, C, and W, the quantity T(R,C; W) specializes to the permanent of a matrix, the number of contingency tables with prescribed margins, and the number of integer feasible flows in a network. We present a randomized algorithm whose complexity is polynomial in N and which computes a number T′=T′(R,C;W) such that T′ ≤ T ≤ α(R,C)T′ where 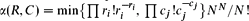 . In many cases, ln T′ provides an asymptotically accurate estimate of ln T. The idea of the algorithm is to express T as the expectation of the permanent of an N × N random matrix with exponentially distributed entries and approximate the expectation by the integral T′ of an efficiently computable log-concave function on ℝmn.
. In many cases, ln T′ provides an asymptotically accurate estimate of ln T. The idea of the algorithm is to express T as the expectation of the permanent of an N × N random matrix with exponentially distributed entries and approximate the expectation by the integral T′ of an efficiently computable log-concave function on ℝmn.
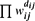 . For different choices of
. For different choices of 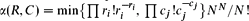 . In many cases, ln
. In many cases, ln On Iterated Image Size for Point-Symmetric Relations
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 61-66
-
- Article
- Export citation
-
Let Γ =(V,E) be a point-symmetric reflexive relation and let υ ∈ V such that |Γ(υ)| is finite (and hence |Γ(x)| is finite for all x, by the transitive action of the group of automorphisms). Let j ∈ℕ be an integer such that Γj(υ)∩ Γ−(υ)={υ}. Our main result states that
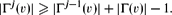
As an application we have |Γj(υ)| ≥ 1+(|Γ(υ)|−1)j. The last result confirms a recent conjecture of Seymour in the case of vertex-symmetric graphs. Also it gives a short proof for the validity of the Caccetta–Häggkvist conjecture for vertex-symmetric graphs and generalizes an additive result of Shepherdson.
Calculating modules in contextual logic program refinement
-
- Journal:
- Theory and Practice of Logic Programming / Volume 8 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 1-31
-
- Article
- Export citation
Learning verb complements for Modern Greek: balancing the noisy dataset
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 71-100
-
- Article
- Export citation
Learning discrete categorial grammars from structures
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 18 January 2008, pp. 165-182
- Print publication:
- January 2008
-
- Article
- Export citation
Enumeration Schemes for Restricted Permutations
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 137-159
-
- Article
- Export citation
Natural language processing in CLIME, a multilingual legal advisory system†
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 101-132
-
- Article
- Export citation
An operational semantics for Scheme1
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 18 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 47-86
-
- Article
-
- You have access
- Export citation
Deciding whether a relation defined inPresburger logiccan be defined in weaker logics
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 42 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 18 January 2008, pp. 121-135
- Print publication:
- January 2008
-
- Article
- Export citation
-
We consider logics on $\mathbb{Z}$
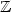 and $\mathbb{N}$
and $\mathbb{N}$ 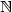 which are weaker than Presburger arithmetic and we settle the following decision problem: given a k-ary relation on $\mathbb{Z}$ and $\mathbb{N}$ which are first order definable inPresburger arithmetic, are they definable in theseweaker logics? These logics, intuitively,are obtained by considering modulo and threshold counting predicates for differences of two variables.
which are weaker than Presburger arithmetic and we settle the following decision problem: given a k-ary relation on $\mathbb{Z}$ and $\mathbb{N}$ which are first order definable inPresburger arithmetic, are they definable in theseweaker logics? These logics, intuitively,are obtained by considering modulo and threshold counting predicates for differences of two variables.
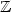
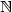
Recurrence with affine level mappings is P-time decidable for CLP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 8 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 111-119
-
- Article
- Export citation
Logic programming with satisfiability
-
- Journal:
- Theory and Practice of Logic Programming / Volume 8 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 121-128
-
- Article
- Export citation
The Critical Phase for Random Graphs with a Given Degree Sequence
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 67-86
-
- Article
- Export citation
Linear tabling strategies and optimizations
-
- Journal:
- Theory and Practice of Logic Programming / Volume 8 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 81-109
-
- Article
- Export citation
The Distribution of Patterns in Random Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 1 / January 2008
- Published online by Cambridge University Press:
- 01 January 2008, pp. 21-59
-
- Article
- Export citation
-
Let
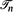 denote the set of unrooted labelled trees of size n and let ℳ be a particular (finite, unlabelled) tree. Assuming that every tree of is equally likely, it is shown that the limiting distribution as n goes to infinity of the number of occurrences of ℳ is asymptotically normal with mean value and variance asymptotically equivalent to μn and σ2n, respectively, where the constants μ>0 and σ≥0 are computable.
denote the set of unrooted labelled trees of size n and let ℳ be a particular (finite, unlabelled) tree. Assuming that every tree of is equally likely, it is shown that the limiting distribution as n goes to infinity of the number of occurrences of ℳ is asymptotically normal with mean value and variance asymptotically equivalent to μn and σ2n, respectively, where the constants μ>0 and σ≥0 are computable.
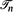 denote the set of unrooted labelled trees of size
denote the set of unrooted labelled trees of size 