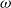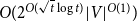Refine search
Actions for selected content:
49522 results in Computer Science
1 - Introduction: The Enduring ‘Point’ and Value of Industrial Relations Research
-
-
- Book:
- The Value of Industrial Relations
- Published by:
- Bristol University Press
- Published online:
- 07 January 2025
- Print publication:
- 15 January 2024, pp 1-11
-
- Chapter
- Export citation
5 - Trade Unions in a Changing World of Work
-
-
- Book:
- The Value of Industrial Relations
- Published by:
- Bristol University Press
- Published online:
- 07 January 2025
- Print publication:
- 15 January 2024, pp 53-64
-
- Chapter
- Export citation
Lightweight transformers for clinical natural language processing
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 12 January 2024, pp. 887-914
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv: 1910.01108, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from
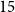 $15$ million to
$15$ million to 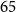 $65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
$65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
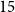
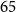
Active learning of the collision distance function for high-DOF multi-arm robot systems
- Part of
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Motion planning for high-DOF multi-arm systems operating in complex environments remains a challenging problem, with many motion planning algorithms requiring evaluation of the minimum collision distance and its derivative. Because of the computational complexity of calculating the collision distance, recent methods have attempted to leverage data-driven machine learning methods to learn the collision distance. Because of the significant training dataset requirements for high-DOF robots, existing kernel-based methods, which require
 $O(N^2)$ memory and computation resources, where
$O(N^2)$ memory and computation resources, where  $N$ denotes the number of dataset points, often perform poorly. This paper proposes a new active learning method for learning the collision distance function that overcomes the limitations of existing methods: (i) the size of the training dataset remains fixed, with the dataset containing more points near the collision boundary as learning proceeds, and (ii) calculating collision distances in the higher-dimensional link
$N$ denotes the number of dataset points, often perform poorly. This paper proposes a new active learning method for learning the collision distance function that overcomes the limitations of existing methods: (i) the size of the training dataset remains fixed, with the dataset containing more points near the collision boundary as learning proceeds, and (ii) calculating collision distances in the higher-dimensional link  $SE(3)^n$ configuration space – here
$SE(3)^n$ configuration space – here  $n$ denotes the number of links – leads to more accurate and robust collision distance function learning. Performance evaluations with high-DOF multi-arm robot systems demonstrate the advantages of the proposed active learning-based strategy vis-
$n$ denotes the number of links – leads to more accurate and robust collision distance function learning. Performance evaluations with high-DOF multi-arm robot systems demonstrate the advantages of the proposed active learning-based strategy vis- $\grave{\text{a}}$-vis existing learning-based methods.
$\grave{\text{a}}$-vis existing learning-based methods.





Audience selection for maximizing social influence
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 12 January 2024, pp. 65-87
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Equilibrium analysis of the fluid model with two types of parallel customers and incomplete fault
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 12 January 2024, pp. 539-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Game-theoretic policy computing and simulation for blockchained buffering system via diffusion approximation
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 12 January 2024, pp. 503-538
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

State Estimation for Robotics
- Second Edition
-
- Published online:
- 11 January 2024
- Print publication:
- 01 February 2024
Determinants for university students’ location data sharing with public institutions during COVID-19: The Italian case
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 11 January 2024, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bus Rapid Transit: End of trend in Latin America?
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 11 January 2024, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the dynamic residual measure of inaccuracy based on extropy in order statistics
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 11 January 2024, pp. 481-502
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Spatial (In)justice and Hot Flushes in the Workplace: Some Musings and Provocations
-
-
- Book:
- Menopause Transitions and the Workplace
- Published by:
- Bristol University Press
- Published online:
- 17 December 2024
- Print publication:
- 10 January 2024, pp 116-134
-
- Chapter
- Export citation
7 - Menopause and the Possibilities of Male Allyship
-
-
- Book:
- Menopause Transitions and the Workplace
- Published by:
- Bristol University Press
- Published online:
- 17 December 2024
- Print publication:
- 10 January 2024, pp 135-156
-
- Chapter
- Export citation
Notes on Contributors
-
- Book:
- Menopause Transitions and the Workplace
- Published by:
- Bristol University Press
- Published online:
- 17 December 2024
- Print publication:
- 10 January 2024, pp xi-xiv
-
- Chapter
- Export citation
A construction of free dcpo-cones
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 10 January 2024, pp. 63-79
-
- Article
- Export citation
-
We give a construction of the free dcpo-cone over any dcpo. There are two steps for getting this result. Firstly, we extend the notion of power domain to directed spaces which are equivalent to
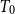 $T_0$ monotone-determined spaces introduced by Erné, and we construct the probabilistic powerspace of the monotone determined space, which is defined as a free monotone determined cone. Secondly, we take D-completion of the free monotone determined cone over the dcpo with its Scott topology. In addition, we show that generally the valuation power domain of any dcpo is not the free dcpo-cone.
$T_0$ monotone-determined spaces introduced by Erné, and we construct the probabilistic powerspace of the monotone determined space, which is defined as a free monotone determined cone. Secondly, we take D-completion of the free monotone determined cone over the dcpo with its Scott topology. In addition, we show that generally the valuation power domain of any dcpo is not the free dcpo-cone.
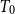
Game characterizations for the number of quantifiers
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 5 / May 2024
- Published online by Cambridge University Press:
- 10 January 2024, pp. 390-409
-
- Article
- Export citation
1 - Introduction
-
-
- Book:
- Menopause Transitions and the Workplace
- Published by:
- Bristol University Press
- Published online:
- 17 December 2024
- Print publication:
- 10 January 2024, pp 1-19
-
- Chapter
- Export citation
Approximation Algorithm and FPT Algorithm for Connected-k-Subgraph Cover on Minor-Free Graphs
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 3 / March 2024
- Published online by Cambridge University Press:
- 10 January 2024, pp. 180-192
-
- Article
- Export citation
-
Given a graph G, the minimum Connected-k-Subgraph Cover problem (MinCkSC) is to find a minimum vertex subset C of G such that every connected subgraph of G on k vertices has at least one vertex in C. If furthermore the subgraph of G induced by C is connected, then the problem is denoted as MinCkSC
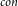 $_{con}$. In this paper, we first present a PTAS for MinCkSC on an H-minor-free graph, where H is a graph with a constant number of vertices. Then, we design an
$_{con}$. In this paper, we first present a PTAS for MinCkSC on an H-minor-free graph, where H is a graph with a constant number of vertices. Then, we design an 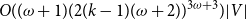 $O((\omega+1)(2(k-1)(\omega+2))^{3\omega+3})|V|$-time FPT algorithm for MinCkSC
$O((\omega+1)(2(k-1)(\omega+2))^{3\omega+3})|V|$-time FPT algorithm for MinCkSC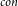 $_{con}$ on a graph with treewidth
$_{con}$ on a graph with treewidth 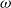 $\omega$, based on which we further design an
$\omega$, based on which we further design an 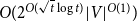 $O(2^{O(\sqrt{t}\log t)}|V|^{O(1)})$ time subexponential FPT algorithm for MinCkSC
$O(2^{O(\sqrt{t}\log t)}|V|^{O(1)})$ time subexponential FPT algorithm for MinCkSC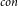 $_{con}$ on an H-minor-free graph, where t is an upper bound of solution size.
$_{con}$ on an H-minor-free graph, where t is an upper bound of solution size.