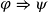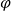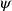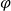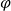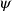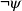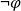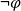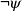Refine search
Actions for selected content:
49522 results in Computer Science
Accelerating and enhancing the generation of socioeconomic data to inform forced displacement policy and response
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 22 December 2023, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
BEYOND LINGUISTIC INTERPRETATION IN THEORY COMPARISON
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 21 December 2023, pp. 819-859
- Print publication:
- September 2024
-
- Article
- Export citation
“That is why users do not understand the maps we make for them”: Cartographic gaps between experts and domestic workers and the Right to the City
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 21 December 2023, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The order-K-ification monads
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 21 December 2023, pp. 45-62
-
- Article
- Export citation
-
Monads prove to be useful mathematical tools in theoretical computer science, notably in denoting different effects of programming languages. In this paper, we investigate a type of monads which arise naturally from Keimel and Lawson’s
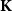 $\mathbf{K}$-ification.
$\mathbf{K}$-ification.A subcategory of
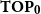 $\mathbf{TOP}_{\mathbf{0}}$ is called of type
$\mathbf{TOP}_{\mathbf{0}}$ is called of type 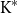 $\mathrm{K}^{*}$ if it consists of monotone convergence spaces and is of type
$\mathrm{K}^{*}$ if it consists of monotone convergence spaces and is of type 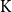 $\mathrm K$ in the sense of Keimel and Lawson. Each such category induces a canonical monad
$\mathrm K$ in the sense of Keimel and Lawson. Each such category induces a canonical monad 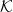 $\mathcal K$ on the category
$\mathcal K$ on the category 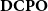 $\mathbf{DCPO}$ of dcpos and Scott-continuous maps, which is called the order-
$\mathbf{DCPO}$ of dcpos and Scott-continuous maps, which is called the order-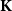 $\mathbf{K}$-ification monad in this paper. First, for each category of type
$\mathbf{K}$-ification monad in this paper. First, for each category of type 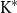 $\mathrm{K}^{*}$, we characterize the algebras of the corresponding monad
$\mathrm{K}^{*}$, we characterize the algebras of the corresponding monad 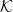 $\mathcal K$ as k-complete posets and algebraic homomorphisms as k-continuous maps, from which we obtain that the order-
$\mathcal K$ as k-complete posets and algebraic homomorphisms as k-continuous maps, from which we obtain that the order-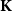 $\mathbf{K}$-ification monad gives the free k-complete poset construction over the category
$\mathbf{K}$-ification monad gives the free k-complete poset construction over the category 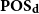 $\mathbf{POS}_{\mathbf{d}}$ of posets and Scott-continuous maps. In addition, we show that all k-complete posets and Scott-continuous maps form a Cartesian closed category. Moreover, we consider the strongness of the order-K-ification monad and conclude with the fact that each order-K-ification monad is always commutative.
$\mathbf{POS}_{\mathbf{d}}$ of posets and Scott-continuous maps. In addition, we show that all k-complete posets and Scott-continuous maps form a Cartesian closed category. Moreover, we consider the strongness of the order-K-ification monad and conclude with the fact that each order-K-ification monad is always commutative.
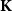
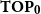
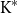
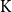
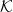
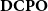
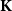
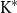
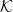
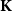
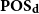
CNL2ASP: Converting Controlled Natural Language Sentences into ASP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 20 December 2023, pp. 196-226
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Percolation on irregular high-dimensional product graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 20 December 2023, pp. 377-403
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider bond percolation on high-dimensional product graphs
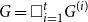 $G=\square _{i=1}^tG^{(i)}$, where
$G=\square _{i=1}^tG^{(i)}$, where  $\square$ denotes the Cartesian product. We call the
$\square$ denotes the Cartesian product. We call the 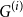 $G^{(i)}$ the base graphs and the product graph
$G^{(i)}$ the base graphs and the product graph 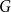 $G$ the host graph. Very recently, Lichev (J. Graph Theory, 99(4):651–670, 2022) showed that, under a mild requirement on the isoperimetric properties of the base graphs, the component structure of the percolated graph
$G$ the host graph. Very recently, Lichev (J. Graph Theory, 99(4):651–670, 2022) showed that, under a mild requirement on the isoperimetric properties of the base graphs, the component structure of the percolated graph 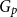 $G_p$ undergoes a phase transition when
$G_p$ undergoes a phase transition when 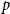 $p$ is around
$p$ is around 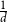 $\frac{1}{d}$, where
$\frac{1}{d}$, where 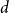 $d$ is the average degree of the host graph.
$d$ is the average degree of the host graph.In the supercritical regime, we strengthen Lichev’s result by showing that the giant component is in fact unique, with all other components of order
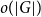 $o(|G|)$, and determining the sharp asymptotic order of the giant. Furthermore, we answer two questions posed by Lichev (J. Graph Theory, 99(4):651–670, 2022): firstly, we provide a construction showing that the requirement of bounded degree is necessary for the likely emergence of a linear order component; secondly, we show that the isoperimetric requirement on the base graphs can be, in fact, super-exponentially small in the dimension. Finally, in the subcritical regime, we give an example showing that in the case of irregular high-dimensional product graphs, there can be a polynomially large component with high probability, very much unlike the quantitative behaviour seen in the Erdős-Rényi random graph and in the percolated hypercube, and in fact in any regular high-dimensional product graphs, as shown by the authors in a companion paper (Percolation on high-dimensional product graphs. arXiv:2209.03722, 2022).
$o(|G|)$, and determining the sharp asymptotic order of the giant. Furthermore, we answer two questions posed by Lichev (J. Graph Theory, 99(4):651–670, 2022): firstly, we provide a construction showing that the requirement of bounded degree is necessary for the likely emergence of a linear order component; secondly, we show that the isoperimetric requirement on the base graphs can be, in fact, super-exponentially small in the dimension. Finally, in the subcritical regime, we give an example showing that in the case of irregular high-dimensional product graphs, there can be a polynomially large component with high probability, very much unlike the quantitative behaviour seen in the Erdős-Rényi random graph and in the percolated hypercube, and in fact in any regular high-dimensional product graphs, as shown by the authors in a companion paper (Percolation on high-dimensional product graphs. arXiv:2209.03722, 2022).

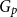
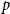
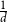
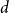
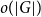
Forty-two years of computer-assisted language learning research: A scientometric study of hotspot research and trending issues
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Visibility and exploitation in social networks
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 7 / August 2024
- Published online by Cambridge University Press:
- 19 December 2023, pp. 615-644
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Force-based organization and control scheme for the non-prehensile cooperative transportation of objects
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reengineering of interbank networks
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 18 December 2023, pp. 41-64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spatiotemporal self-supervised pre-training on satellite imagery improves food insecurity prediction
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 18 December 2023, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation


Large-Scale Data Analytics with Python and Spark
- A Hands-on Guide to Implementing Machine Learning Solutions
-
- Published online:
- 15 December 2023
- Print publication:
- 23 November 2023
-
- Textbook
- Export citation
Fractional order inspired iterative adaptive control
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Machine learning and feature selection: Applications in economics and climate change
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 15 December 2023, e47
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Shock models governed by an inverse gamma mixed Poisson process
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 15 December 2023, pp. 459-480
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Modern Discrete Probability
- An Essential Toolkit
-
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024
Human Conditional Reasoning in Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 14 December 2023, pp. 157-192
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a conditional sentence “
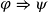 ${\varphi}\Rightarrow \psi$" (if
${\varphi}\Rightarrow \psi$" (if 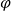 ${\varphi}$ then
${\varphi}$ then 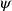 $\psi$) and respective facts, four different types of inferences are observed in human reasoning: Affirming the antecedent (AA) (or modus ponens) reasons
$\psi$) and respective facts, four different types of inferences are observed in human reasoning: Affirming the antecedent (AA) (or modus ponens) reasons 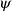 $\psi$ from
$\psi$ from 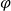 ${\varphi}$; affirming the consequent (AC) reasons
${\varphi}$; affirming the consequent (AC) reasons 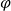 ${\varphi}$ from
${\varphi}$ from 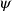 $\psi$; denying the antecedent (DA) reasons
$\psi$; denying the antecedent (DA) reasons 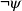 $\neg\psi$ from
$\neg\psi$ from 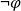 $\neg{\varphi}$; and denying the consequent (DC) (or modus tollens) reasons
$\neg{\varphi}$; and denying the consequent (DC) (or modus tollens) reasons 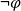 $\neg{\varphi}$ from
$\neg{\varphi}$ from 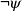 $\neg\psi$. Among them, AA and DC are logically valid, while AC and DA are logically invalid and often called logical fallacies. Nevertheless, humans often perform AC or DA as pragmatic inference in daily life. In this paper, we realize AC, DA and DC inferences in answer set programming. Eight different types of completion are introduced, and their semantics are given by answer sets. We investigate formal properties and characterize human reasoning tasks in cognitive psychology. Those completions are also applied to commonsense reasoning in AI.
$\neg\psi$. Among them, AA and DC are logically valid, while AC and DA are logically invalid and often called logical fallacies. Nevertheless, humans often perform AC or DA as pragmatic inference in daily life. In this paper, we realize AC, DA and DC inferences in answer set programming. Eight different types of completion are introduced, and their semantics are given by answer sets. We investigate formal properties and characterize human reasoning tasks in cognitive psychology. Those completions are also applied to commonsense reasoning in AI.