Refine search
Actions for selected content:
49522 results in Computer Science
Analysis of spatial–temporal validation patterns in Fortaleza’s public transport systems: a data mining approach
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 14 December 2023, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A social science mixed-methods approach to stimulating and measuring creativity in the design classroom
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 14 December 2023, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Kinematics and singularity analysis of a novel hybrid industrial manipulator
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PARACONSISTENT AND PARACOMPLETE ZERMELO–FRAENKEL SET THEORY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 13 December 2023, pp. 965-995
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present a novel treatment of set theory in a four-valued paraconsistent and paracomplete logic, i.e., a logic in which propositions can be both true and false, and neither true nor false. Our approach is a significant departure from previous research in paraconsistent set theory, which has almost exclusively been motivated by a desire to avoid Russell’s paradox and fulfil naive comprehension. Instead, we prioritise setting up a system with a clear ontology of non-classical sets, which can be used to reason informally about incomplete and inconsistent phenomena, and is sufficiently similar to
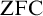 ${\mathrm {ZFC}}$ to enable the development of interesting mathematics.
${\mathrm {ZFC}}$ to enable the development of interesting mathematics.We propose an axiomatic system
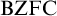 ${\mathrm {BZFC}}$, obtained by analysing the
${\mathrm {BZFC}}$, obtained by analysing the 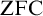 ${\mathrm {ZFC}}$-axioms and translating them to a four-valued setting in a careful manner, avoiding many of the obstacles encountered by other attempted formalizations. We introduce the anti-classicality axiom postulating the existence of non-classical sets, and prove a surprising results stating that the existence of a single non-classical set is sufficient to produce any other type of non-classical set.
${\mathrm {ZFC}}$-axioms and translating them to a four-valued setting in a careful manner, avoiding many of the obstacles encountered by other attempted formalizations. We introduce the anti-classicality axiom postulating the existence of non-classical sets, and prove a surprising results stating that the existence of a single non-classical set is sufficient to produce any other type of non-classical set.Our theory is naturally bi-interpretable with
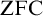 ${\mathrm {ZFC}}$, and provides a philosophically satisfying view in which non-classical sets can be seen as a natural extension of classical ones, in a similar way to the non-well-founded sets of Peter Aczel [1].
${\mathrm {ZFC}}$, and provides a philosophically satisfying view in which non-classical sets can be seen as a natural extension of classical ones, in a similar way to the non-well-founded sets of Peter Aczel [1].Finally, we provide an interesting application concerning Tarski semantics, showing that the classical definition of the satisfaction relation yields a logic precisely reflecting the non-classicality in the meta-theory.
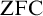
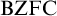
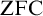
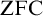
Aggregation strategies to improve XAI for geoscience models that use correlated, high-dimensional rasters
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 13 December 2023, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Virtual reality as a technology of memory: Immersive presence in Polish politics of memory
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 2 / 2023
- Published online by Cambridge University Press:
- 13 December 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
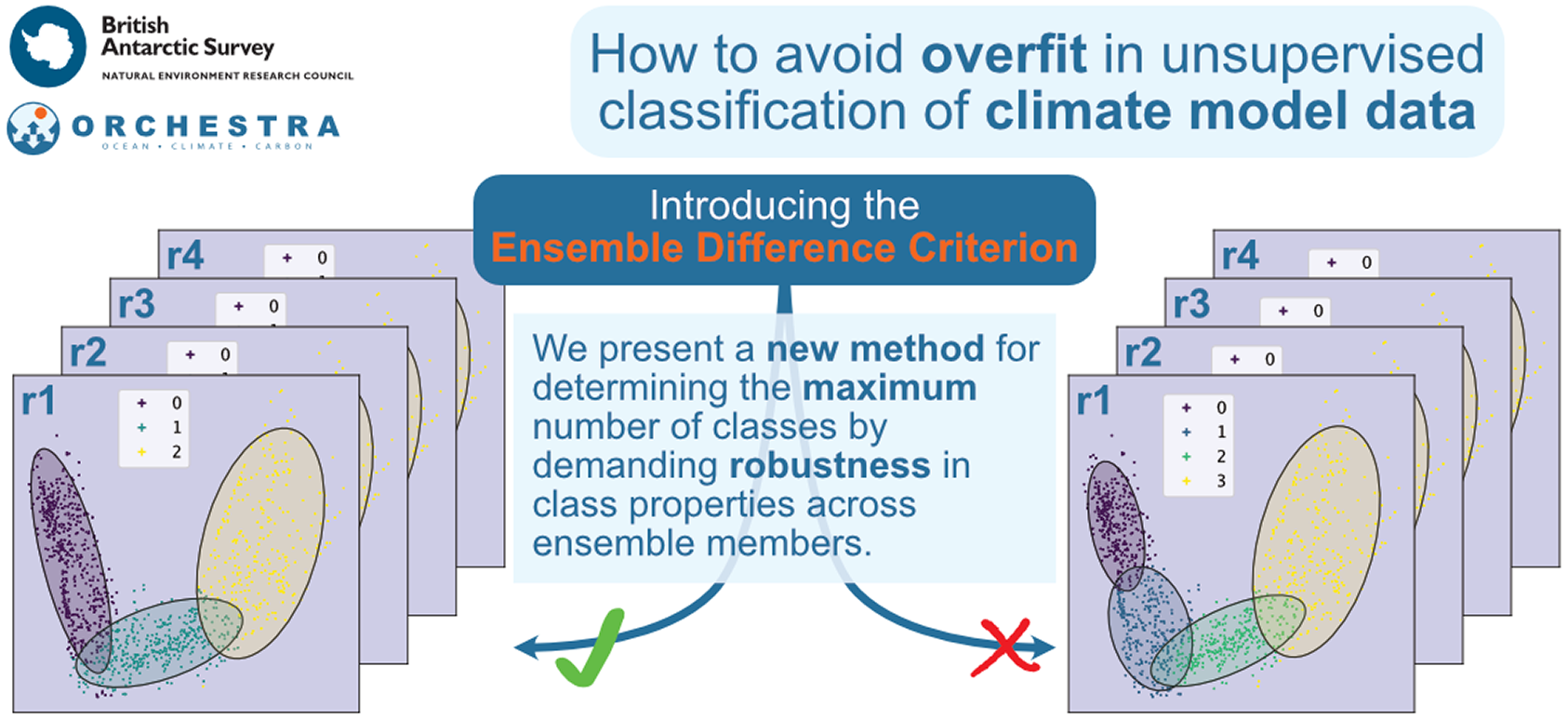
A novel heuristic method for detecting overfit in unsupervised classification of climate model data
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 13 December 2023, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distributed data network: a case study of the Indian textile homeworkers
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 13 December 2023, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fixed point logics and definable topological properties
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 2 / February 2024
- Published online by Cambridge University Press:
- 13 December 2023, pp. 81-97
-
- Article
- Export citation
Trace contracts
-
- Journal:
- Journal of Functional Programming / Volume 33 / 2023
- Published online by Cambridge University Press:
- 13 December 2023, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
dCNN/dCAM: anomaly precursors discovery in multivariate time series with deep convolutional neural networks
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 13 December 2023, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Photo age: Temporal preferences for external memory across the lifespan
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 2 / 2023
- Published online by Cambridge University Press:
- 12 December 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Certified, total serialisers with an application to Huffman encoding
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 33 / 2023
- Published online by Cambridge University Press:
- 12 December 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mapping artificial intelligence-based methods to engineering design stages: a focused literature review
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Level-p-complexity of Boolean functions using thinning, memoization, and polynomials
-
- Journal:
- Journal of Functional Programming / Volume 33 / 2023
- Published online by Cambridge University Press:
- 12 December 2023, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper describes a purely functional library for computing level-p-complexity of Boolean functions and applies it to two-level iterated majority. Boolean functions are simply functions from n bits to one bit, and they can describe digital circuits, voting systems, etc. An example of a Boolean function is majority, which returns the value that has majority among the n input bits for odd n. The complexity of a Boolean function f measures the cost of evaluating it: how many bits of the input are needed to be certain about the result of f. There are many competing complexity measures, but we focus on level-p-complexity — a function of the probability p that a bit is 1. The level-p-complexity
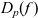 $D_p(f)$ is the minimum expected cost when the input bits are independent and identically distributed with Bernoulli(p) distribution. We specify the problem as choosing the minimum expected cost of all possible decision trees — which directly translates to a clearly correct, but very inefficient implementation. The library uses thinning and memoization for efficiency and type classes for separation of concerns. The complexity is represented using (sets of) polynomials, and the order relation used for thinning is implemented using polynomial factorization and root counting. Finally, we compute the complexity for two-level iterated majority and improve on an earlier result by J. Jansson.
$D_p(f)$ is the minimum expected cost when the input bits are independent and identically distributed with Bernoulli(p) distribution. We specify the problem as choosing the minimum expected cost of all possible decision trees — which directly translates to a clearly correct, but very inefficient implementation. The library uses thinning and memoization for efficiency and type classes for separation of concerns. The complexity is represented using (sets of) polynomials, and the order relation used for thinning is implemented using polynomial factorization and root counting. Finally, we compute the complexity for two-level iterated majority and improve on an earlier result by J. Jansson.
A comparative cyber risk analysis between federated and self-sovereign identity management systems
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 12 December 2023, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A variable stiffness robotic gripper based on parallel beam with vision-based force sensing for flexible grasping
- Part of
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 1 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Cycling Assessment: A tool to inform policymakers and enhance the cyclist’s travel experience, with a gender perspective
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 11 December 2023, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
