Refine search
Actions for selected content:
49522 results in Computer Science
Precise large deviations for a multidimensional risk model with regression dependence structure
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 01 December 2023, pp. 448-457
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we consider a nonstandard multidimensional risk model, in which the claim sizes
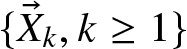 $\{\vec{X}_k, k\ge 1\}$ form an independent and identically distributed random vector sequence with dependent components. By assuming that there exists the regression dependence structure between inter-arrival time and the claim-size vectors, we extend the regression dependence to a more practical multidimensional risk model. For the univariate marginal distributions of claim vectors with consistently varying tails, we obtain the precise large deviation formulas for the multidimensional risk model with the regression size-dependent structure.
$\{\vec{X}_k, k\ge 1\}$ form an independent and identically distributed random vector sequence with dependent components. By assuming that there exists the regression dependence structure between inter-arrival time and the claim-size vectors, we extend the regression dependence to a more practical multidimensional risk model. For the univariate marginal distributions of claim vectors with consistently varying tails, we obtain the precise large deviation formulas for the multidimensional risk model with the regression size-dependent structure.
RSL volume 16 issue 4 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 December 2023, pp. f1-f4
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
Annual estimates of global and national CO2 emissions from fossil fuels: Tracking revisions to the United Nations energy statistics database input energy data
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 01 December 2023, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
OSO volume 28 issue 3 Cover and Front matter
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 23 February 2024, pp. f1-f2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
Sound and Video Examples – Issue 28(3)
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 23 February 2024, p. 423
- Print publication:
- December 2023
-
- Article
- Export citation
8 - The Islamophobic Consensus
- from Part II - Automated States
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 152-170
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
10 - Sorting Teachers Out
- from Part III - Synergies and Safeguards
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 189-204
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
5 - Traditionalist Data Protection Rules
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 88-109
-
- Chapter
- Export citation
Abbreviations
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp xxi-xxii
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
9 - Law and Empathy in the Automated State
- from Part III - Synergies and Safeguards
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 173-188
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Part II - Automated States
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 93-170
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
A longitudinal study of conversational remembering in WhatsApp group messages before, during, and after COVID-19 lockdown
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 2 / 2023
- Published online by Cambridge University Press:
- 30 November 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Leveraging AI to Mitigate Money Laundering Risks in the Banking System
- from Part I - Automated Banks
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 51-69
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
3 - The Consent Illusion
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 46-66
-
- Chapter
- Export citation
On minimum spanning trees for random Euclidean bipartite graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 30 November 2023, pp. 319-350
-
- Article
- Export citation
-
We consider the minimum spanning tree problem on a weighted complete bipartite graph
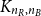 $K_{n_R, n_B}$ whose
$K_{n_R, n_B}$ whose 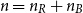 $n=n_R+n_B$ vertices are random, i.i.d. uniformly distributed points in the unit cube in
$n=n_R+n_B$ vertices are random, i.i.d. uniformly distributed points in the unit cube in 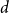 $d$ dimensions and edge weights are the
$d$ dimensions and edge weights are the 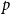 $p$-th power of their Euclidean distance, with
$p$-th power of their Euclidean distance, with 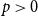 $p\gt 0$. In the large
$p\gt 0$. In the large  $n$ limit with
$n$ limit with 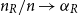 $n_R/n \to \alpha _R$ and
$n_R/n \to \alpha _R$ and 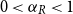 $0\lt \alpha _R\lt 1$, we show that the maximum vertex degree of the tree grows logarithmically, in contrast with the classical, non-bipartite, case, where a uniform bound holds depending on
$0\lt \alpha _R\lt 1$, we show that the maximum vertex degree of the tree grows logarithmically, in contrast with the classical, non-bipartite, case, where a uniform bound holds depending on 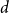 $d$ only. Despite this difference, for
$d$ only. Despite this difference, for 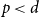 $p\lt d$, we are able to prove that the total edge costs normalized by the rate
$p\lt d$, we are able to prove that the total edge costs normalized by the rate 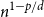 $n^{1-p/d}$ converge to a limiting constant that can be represented as a series of integrals, thus extending a classical result of Avram and Bertsimas to the bipartite case and confirming a conjecture of Riva, Caracciolo and Malatesta.
$n^{1-p/d}$ converge to a limiting constant that can be represented as a series of integrals, thus extending a classical result of Avram and Bertsimas to the bipartite case and confirming a conjecture of Riva, Caracciolo and Malatesta.
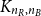
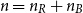
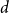
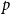
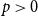

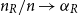
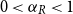
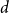
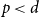
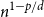
5 - The Automated Welfare State
- from Part II - Automated States
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 95-115
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
2 - Privacy Myths
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 28-45
-
- Chapter
- Export citation
1 - The Traditionalist Approach to Privacy
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 11-27
-
- Chapter
- Export citation
Notes
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 173-242
-
- Chapter
- Export citation
Dedication
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp v-vi
-
- Chapter
- Export citation
