Refine search
Actions for selected content:
49522 results in Computer Science
Copyright page
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp iv-iv
-
- Chapter
- Export citation
Conclusion
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 165-172
-
- Chapter
- Export citation
2 - Demystifying Consumer-Facing Fintech
- from Part I - Automated Banks
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 29-50
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Foreword
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp xv-xviii
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Acknowledgements
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp xix-xx
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
6 - Pervasive Data Harms
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 110-137
-
- Chapter
- Export citation
6 - A New ‘Machinery of Government’?
- from Part II - Automated States
-
-
- Book:
- <i>Money, Power, and AI</i>
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 116-135
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Index
-
- Book:
- The Privacy Fallacy
- Published online:
- 16 November 2023
- Print publication:
- 30 November 2023, pp 243-248
-
- Chapter
- Export citation
Shaping the future of tunneling with data and emerging technologies
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 29 November 2023, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Threshold graphs maximise homomorphism densities
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 29 November 2023, pp. 300-318
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a fixed graph
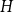 $H$ and a constant
$H$ and a constant 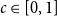 $c \in [0,1]$, we can ask what graphs
$c \in [0,1]$, we can ask what graphs 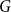 $G$ with edge density
$G$ with edge density  $c$ asymptotically maximise the homomorphism density of
$c$ asymptotically maximise the homomorphism density of 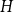 $H$ in
$H$ in 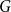 $G$. For all
$G$. For all 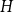 $H$ for which this problem has been solved, the maximum is always asymptotically attained on one of two kinds of graphs: the quasi-star or the quasi-clique. We show that for any
$H$ for which this problem has been solved, the maximum is always asymptotically attained on one of two kinds of graphs: the quasi-star or the quasi-clique. We show that for any 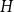 $H$ the maximising
$H$ the maximising 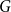 $G$ is asymptotically a threshold graph, while the quasi-clique and the quasi-star are the simplest threshold graphs, having only two parts. This result gives us a unified framework to derive a number of results on graph homomorphism maximisation, some of which were also found quite recently and independently using several different approaches. We show that there exist graphs
$G$ is asymptotically a threshold graph, while the quasi-clique and the quasi-star are the simplest threshold graphs, having only two parts. This result gives us a unified framework to derive a number of results on graph homomorphism maximisation, some of which were also found quite recently and independently using several different approaches. We show that there exist graphs 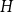 $H$ and densities
$H$ and densities  $c$ such that the optimising graph
$c$ such that the optimising graph 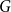 $G$ is neither the quasi-star nor the quasi-clique (Day and Sarkar, SIAM J. Discrete Math. 35(1), 294–306, 2021). We also show that for
$G$ is neither the quasi-star nor the quasi-clique (Day and Sarkar, SIAM J. Discrete Math. 35(1), 294–306, 2021). We also show that for  $c$ large enough all graphs
$c$ large enough all graphs 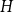 $H$ maximise on the quasi-clique (Gerbner et al., J. Graph Theory 96(1), 34–43, 2021), and for any
$H$ maximise on the quasi-clique (Gerbner et al., J. Graph Theory 96(1), 34–43, 2021), and for any 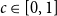 $c \in [0,1]$ the density of
$c \in [0,1]$ the density of 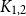 $K_{1,2}$ is always maximised on either the quasi-star or the quasi-clique (Ahlswede and Katona, Acta Math. Hung. 32(1–2), 97–120, 1978). Finally, we extend our results to uniform hypergraphs.
$K_{1,2}$ is always maximised on either the quasi-star or the quasi-clique (Ahlswede and Katona, Acta Math. Hung. 32(1–2), 97–120, 1978). Finally, we extend our results to uniform hypergraphs.
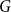

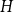
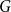
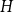
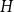
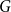
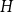


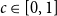
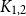
Adaptive learning with artificial barriers yielding Nash equilibria in general games
-
- Journal:
- The Knowledge Engineering Review / Volume 38 / 2023
- Published online by Cambridge University Press:
- 29 November 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Querying Incomplete Data: Complexity and Tractability via Datalog and First-Order Rewritings
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 28 November 2023, pp. 279-309
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
LOGICS FROM ULTRAFILTERS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 28 November 2023, pp. 142-159
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Ultrafilters play a significant role in model theory to characterize logics having various compactness and interpolation properties. They also provide a general method to construct extensions of first-order logic having these properties. A main result of this paper is that every class
 $\Omega $ of uniform ultrafilters generates a
$\Omega $ of uniform ultrafilters generates a  $\Delta $-closed logic
$\Delta $-closed logic  ${\mathcal {L}}_\Omega $.
${\mathcal {L}}_\Omega $.  ${\mathcal {L}}_\Omega $ is
${\mathcal {L}}_\Omega $ is  $\omega $-relatively compact iff some
$\omega $-relatively compact iff some  $D\in \Omega $ fails to be
$D\in \Omega $ fails to be  $\omega _1$-complete iff
$\omega _1$-complete iff  ${\mathcal {L}}_\Omega $ does not contain the quantifier “there are uncountably many.” If
${\mathcal {L}}_\Omega $ does not contain the quantifier “there are uncountably many.” If  $\Omega $ is a set, or if it contains a countably incomplete ultrafilter, then
$\Omega $ is a set, or if it contains a countably incomplete ultrafilter, then  ${\mathcal {L}}_\Omega $ is not generated by Mostowski cardinality quantifiers. Assuming
${\mathcal {L}}_\Omega $ is not generated by Mostowski cardinality quantifiers. Assuming  $\neg 0^\sharp $ or
$\neg 0^\sharp $ or  $\neg L^{\mu }$, if
$\neg L^{\mu }$, if  $D\in \Omega $ is a uniform ultrafilter over a regular cardinal
$D\in \Omega $ is a uniform ultrafilter over a regular cardinal  $\nu $, then every family
$\nu $, then every family  $\Psi $ of formulas in
$\Psi $ of formulas in  ${\mathcal {L}}_\Omega $ with
${\mathcal {L}}_\Omega $ with  $|\Phi |\leq \nu $ satisfies the compactness theorem. In particular, if
$|\Phi |\leq \nu $ satisfies the compactness theorem. In particular, if  $\Omega $ is a proper class of uniform ultrafilters over regular cardinals,
$\Omega $ is a proper class of uniform ultrafilters over regular cardinals,  ${\mathcal {L}}_\Omega $ is compact.
${\mathcal {L}}_\Omega $ is compact.



















Data-to-text generation using conditional generative adversarial with enhanced transformer
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 28 November 2023, pp. 696-721
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Closing the domain gap: blended synthetic imagery for climate object detection
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 28 November 2023, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Introduction to Intelligent Systems, Control, and Machine Learning using MATLAB
-
- Published online:
- 27 November 2023
- Print publication:
- 16 November 2023
-
- Textbook
- Export citation
Reframing Sound Shapes in Spectromorphological Composition: Notating perspectival space through spherical, Euclidean and Cartesian-coordinate systems
-
- Journal:
- Organised Sound / Volume 29 / Issue 2 / August 2024
- Published online by Cambridge University Press:
- 24 November 2023, pp. 228-238
- Print publication:
- August 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Overview of transparency and inspectability mechanisms to achieve accountability of artificial intelligence systems
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 24 November 2023, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
