Refine search
Actions for selected content:
49522 results in Computer Science
10 - Surfacing the Body: Embodiment, Site and Source
-
-
- Book:
- Information Literacy through Theory
- Published by:
- Facet
- Published online:
- 26 March 2024
- Print publication:
- 07 December 2023, pp 165-182
-
- Chapter
- Export citation
A novel filtering method for geodetically determined ocean surface currents using deep learning
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 06 December 2023, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preface: Special issue on NLP approaches to offensive content online
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 06 December 2023, p. 1415
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
OffensEval 2023: Offensive language identification in the age of Large Language Models
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 06 December 2023, pp. 1416-1435
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interesting and impressive: exploring design factors for product graphics interchange format to enhance engagement
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Neural representation of the stratospheric ozone chemistry
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Short-term forecasting of ozone air pollution across Europe with transformers
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Surface ozone is an air pollutant that contributes to hundreds of thousands of premature deaths annually. Accurate short-term ozone forecasts may allow improved policy actions to reduce the risk to human health. However, forecasting surface ozone is a difficult problem as its concentrations are controlled by a number of physical and chemical processes that act on varying timescales. We implement a state-of-the-art transformer-based model, the temporal fusion transformer, trained on observational data from three European countries. In four-day forecasts of daily maximum 8-hour ozone (DMA8), our novel approach is highly skillful (MAE = 4.9 ppb, coefficient of determination
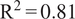 $ {\mathrm{R}}^2=0.81 $) and generalizes well to data from 13 other European countries unseen during training (MAE = 5.0 ppb,
$ {\mathrm{R}}^2=0.81 $) and generalizes well to data from 13 other European countries unseen during training (MAE = 5.0 ppb, 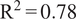 $ {\mathrm{R}}^2=0.78 $). The model outperforms other machine learning models on our data (ridge regression, random forests, and long short-term memory networks) and compares favorably to the performance of other published deep learning architectures tested on different data. Furthermore, we illustrate that the model pays attention to physical variables known to control ozone concentrations and that the attention mechanism allows the model to use the most relevant days of past ozone concentrations to make accurate forecasts on test data. The skillful performance of the model, particularly in generalizing to unseen European countries, suggests that machine learning methods may provide a computationally cheap approach for accurate air quality forecasting across Europe.
$ {\mathrm{R}}^2=0.78 $). The model outperforms other machine learning models on our data (ridge regression, random forests, and long short-term memory networks) and compares favorably to the performance of other published deep learning architectures tested on different data. Furthermore, we illustrate that the model pays attention to physical variables known to control ozone concentrations and that the attention mechanism allows the model to use the most relevant days of past ozone concentrations to make accurate forecasts on test data. The skillful performance of the model, particularly in generalizing to unseen European countries, suggests that machine learning methods may provide a computationally cheap approach for accurate air quality forecasting across Europe.
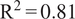
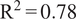
Extending scene-to-patch models: Multi-resolution multiple instance learning for Earth observation
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Make it or draw it? Investigating the communicative trade-offs between sketches and prototypes
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 01 December 2023, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editorial: Ecologically grounded creative practices and ubiquitous music – interaction and environment
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 25 January 2024, pp. 321-327
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
A steerable robot walker driven by two actuators
- Part of
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ecomprovisation: Project Markarian 335
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 30 January 2024, pp. 328-337
- Print publication:
- December 2023
-
- Article
- Export citation
The Artist as a Subscription: Patching music as an artistic device
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 08 January 2024, pp. 352-361
- Print publication:
- December 2023
-
- Article
- Export citation
Diverse Sound Practices: An exploration of experimental electronic music in regional Australia
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 25 January 2024, pp. 362-371
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From Site-Specific Sampling to Gamification: An exploration of performative engagement with the environment
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 06 December 2023, pp. 338-351
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RSL volume 16 issue 4 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 December 2023, pp. b1-b2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
OSO volume 28 issue 3 Cover and Back matter
-
- Journal:
- Organised Sound / Volume 28 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 23 February 2024, pp. b1-b2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
A point-free perspective on lax extensions and predicate liftings
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 2 / February 2024
- Published online by Cambridge University Press:
- 01 December 2023, pp. 98-127
-
- Article
- Export citation
