Refine search
Actions for selected content:
49448 results in Computer Science
Acknowledgments
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 279-280
-
- Chapter
- Export citation
4 - AI Literacy
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 60-135
-
- Chapter
- Export citation
A scoping review of AI-mediated informal language learning: Mapping out the terrain and identifying future directions
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
National digital ID apps and disability: towards an agenda for digital inclusion?
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 29 October 2025, e74
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Catching the bad apples to keep up the good work: Dutch municipal government perspectives on data-driven technologies in unemployment
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 29 October 2025, e75
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A multi-modal embodied robot framework for English as a second language learning in preschoolers: design and evaluation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Call-by-value and call-by-name: A simple proof of a classic theorem
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 35 / 2025
- Published online by Cambridge University Press:
- 29 October 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
One of the natural problems of operational semantics is to characterise the relationship between eager and lazy evaluation. In the context of
 $\lambda$-calculus, this is expressed by the classic theorem that call-by-value evaluation of a program to (weak-head) normal form can always be simulated by a call-by-name evaluation. While the statement and intuition behind it are simple and clear, naive attempts at proof famously fail: the result is usually established as a consequence of the more complex standardisation theorem. In this work, we develop and formalise a novel and lightweight inductive approach to tackle the problem of simulation between two semantics for a single calculus, but with different evaluation orders. We exercise our method on the classic call-by-value and call-by-name example and report on methodological takeaways suggested by our approach, in particular what effect the flavour of semantics chosen has on the proof.
$\lambda$-calculus, this is expressed by the classic theorem that call-by-value evaluation of a program to (weak-head) normal form can always be simulated by a call-by-name evaluation. While the statement and intuition behind it are simple and clear, naive attempts at proof famously fail: the result is usually established as a consequence of the more complex standardisation theorem. In this work, we develop and formalise a novel and lightweight inductive approach to tackle the problem of simulation between two semantics for a single calculus, but with different evaluation orders. We exercise our method on the classic call-by-value and call-by-name example and report on methodological takeaways suggested by our approach, in particular what effect the flavour of semantics chosen has on the proof.

Powers of Hamilton cycles in oriented and directed graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 28 October 2025, pp. 101-133
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The Pósa–Seymour conjecture determines the minimum degree threshold for forcing the
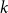 $k$th power of a Hamilton cycle in a graph. After numerous partial results, Komlós, Sárközy, and Szemerédi proved the conjecture for sufficiently large graphs. In this paper, we focus on the analogous problem for digraphs and for oriented graphs. We asymptotically determine the minimum total degree threshold for forcing the square of a Hamilton cycle in a digraph. We also give a conjecture on the corresponding threshold for
$k$th power of a Hamilton cycle in a graph. After numerous partial results, Komlós, Sárközy, and Szemerédi proved the conjecture for sufficiently large graphs. In this paper, we focus on the analogous problem for digraphs and for oriented graphs. We asymptotically determine the minimum total degree threshold for forcing the square of a Hamilton cycle in a digraph. We also give a conjecture on the corresponding threshold for 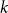 $k$th powers of a Hamilton cycle more generally. For oriented graphs, we provide a minimum semi-degree condition that forces the
$k$th powers of a Hamilton cycle more generally. For oriented graphs, we provide a minimum semi-degree condition that forces the 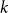 $k$th power of a Hamilton cycle; although this minimum semi-degree condition is not tight, it does provide the correct order of magnitude of the threshold. Turán-type problems for oriented graphs are also discussed.
$k$th power of a Hamilton cycle; although this minimum semi-degree condition is not tight, it does provide the correct order of magnitude of the threshold. Turán-type problems for oriented graphs are also discussed.
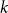
Foreword for the special issue “Differential Structures in Computer Science and Mathematics”
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 27 October 2025, e27
-
- Article
-
- You have access
- HTML
- Export citation
From winter storm thermodynamics to wind gust extremes: discovering interpretable equations from data
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 27 October 2025, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A comparative analysis of initial-pose self-calibration algorithms for underactuated cable-driven parallel robots
- Part of
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Complexity of inversion of functions on the reals
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 27 October 2025, e26
-
- Article
- Export citation
Disperse hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 27 October 2025, pp. 89-100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For
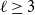 $\ell \geq 3$, an
$\ell \geq 3$, an 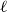 $\ell$-uniform hypergraph is disperse if the number of edges induced by any set of
$\ell$-uniform hypergraph is disperse if the number of edges induced by any set of 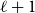 $\ell +1$ vertices is 0, 1,
$\ell +1$ vertices is 0, 1, 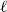 $\ell$, or
$\ell$, or 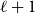 $\ell +1$. We show that every disperse
$\ell +1$. We show that every disperse 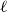 $\ell$-uniform hypergraph on
$\ell$-uniform hypergraph on  $n$ vertices contains a clique or independent set of size
$n$ vertices contains a clique or independent set of size 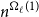 $n^{\Omega _{\ell }(1)}$, answering a question of the first author and Tomon. To this end, we prove several structural properties of disperse hypergraphs.
$n^{\Omega _{\ell }(1)}$, answering a question of the first author and Tomon. To this end, we prove several structural properties of disperse hypergraphs.
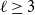
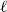
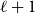
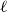

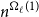
Handling the hype: Demystifying artificial intelligence for memory studies
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 27 October 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Domain anchorage in LLMs: Lexicon profiling and unintended information leakage
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 27 October 2025, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tail recursion modulo context: An equational approach (extended version)
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 35 / 2025
- Published online by Cambridge University Press:
- 24 October 2025, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Who would ask whom for health advice? The structural anatomy of health advice networks among middle-aged and older adults
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 24 October 2025, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
