Refine search
Actions for selected content:
49448 results in Computer Science

Introduction to Homotopy Type Theory
-
- Published online:
- 23 October 2025
- Print publication:
- 06 November 2025
Function modeling in model-based systems engineering using flow heuristics
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What is livingness? From natural matter to a programmable one
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 22 October 2025, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Public data sharing legislation, privacy and sharing of health and social welfare data in Australia: a legal and policy document analysis
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 22 October 2025, e72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring EU public opinion with cognitive mapping
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 22 October 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Insight-Driven Problem Solving
- Analytics Science to Improve the World
-
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025

Wireless Communications and Machine Learning
-
- Published online:
- 21 October 2025
- Print publication:
- 03 July 2025
-
- Textbook
- Export citation
Educational background’s impact on designers’ ideation: brain, behavior, and stress
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI and generational amnesia: An ecological approach to ‘new memory’ regimes
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 20 October 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lost in translation: why digital twins thrive in research but falter in politics and public administration
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 20 October 2025, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Quantum Information
- A First Course
-
- Published online:
- 17 October 2025
- Print publication:
- 26 June 2025
-
- Textbook
- Export citation
Anticipating human mobility: Methods, data, and policy in forecasting and foresight
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 October 2025, e70
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interactive mechatronic system for improving upper limb rehabilitation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Smart Expansion Techniques for ASP-Based Interactive Configuration
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 17 October 2025, pp. 473-488
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Splitting a Disjunctive Logic Program
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 17 October 2025, pp. 507-521
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A note on the computational complexity of weak saturation
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 16 October 2025, pp. 83-88
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that determining the weak saturation number of a host graph
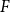 $F$ with respect to a pattern graph
$F$ with respect to a pattern graph 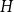 $H$ is computationally hard, even when
$H$ is computationally hard, even when 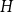 $H$ is the triangle. Our main tool establishes a connection between weak saturation and the shellability of simplicial complexes.
$H$ is the triangle. Our main tool establishes a connection between weak saturation and the shellability of simplicial complexes.
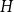
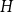
Part II - A different category of categories
-
- Book:
- Polynomial Functors
- Published online:
- 27 September 2025
- Print publication:
- 16 October 2025, pp 231-232
-
- Chapter
- Export citation
