Refine search
Actions for selected content:
49448 results in Computer Science
Introduction
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 1-11
-
- Chapter
-
- You have access
- HTML
- Export citation
References
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 160-182
-
- Chapter
- Export citation
6 - Dynamic Programming and Sequential Decision-Making
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 188-206
-
- Chapter
- Export citation
Index
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp 561-564
-
- Chapter
- Export citation
7 - Random Walks on Graphs and Markov Chains
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp 421-493
-
- Chapter
- Export citation
2 - Least Squares: Geometric, Algebraic, and Numerical Aspects
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp 67-127
-
- Chapter
- Export citation
Contents
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp v-vi
-
- Chapter
- Export citation
3 - AI in the Classroom
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 38-59
-
- Chapter
- Export citation
8 - Neural Networks, Backpropagation, and Stochastic Gradient Descent
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp 494-559
-
- Chapter
- Export citation
Notes
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 281-296
-
- Chapter
- Export citation
A quantitative approach to global state composition
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 30 October 2025, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that recent approaches to quantitative analysis based on non-idempotent typing systems can be extended to programming languages with effects. In particular, we consider two cases: the weak open call-by-name (CBN) and call-by-value (CBV) variants of the
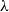 $\lambda$-calculus, equipped with operations to write and read from a global state. In order to capture quantitative information with respect to time and space for both CBN and CBV, we design for each of them a quantitative type system based on a (tight) multi-type system. One key observation of this work is how CBN and CBV influence the composition of state types. That is, each type system is developed by taking into account how each language manages the global state: in CBN, the composition of state types is almost straightforward, since function application does not require evaluation of its argument; in CBV, however, the interaction between functions and arguments makes the composition of state types more subtle since only values can be passed as actual arguments. The main contribution of this paper is the design of type systems capturing quantitative information about effectful CBN and CBV programming languages. Indeed, we develop type systems that are qualitatively and quantitatively sound and complete.
$\lambda$-calculus, equipped with operations to write and read from a global state. In order to capture quantitative information with respect to time and space for both CBN and CBV, we design for each of them a quantitative type system based on a (tight) multi-type system. One key observation of this work is how CBN and CBV influence the composition of state types. That is, each type system is developed by taking into account how each language manages the global state: in CBN, the composition of state types is almost straightforward, since function application does not require evaluation of its argument; in CBV, however, the interaction between functions and arguments makes the composition of state types more subtle since only values can be passed as actual arguments. The main contribution of this paper is the design of type systems capturing quantitative information about effectful CBN and CBV programming languages. Indeed, we develop type systems that are qualitatively and quantitatively sound and complete.
2 - AI in Education
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 24-37
-
- Chapter
- Export citation
Index
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 183-184
-
- Chapter
- Export citation
3 - Optimization Theory and Algorithms
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp 128-199
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Mathematical Methods in Data Science
- Published online:
- 04 November 2025
- Print publication:
- 30 October 2025, pp iv-iv
-
- Chapter
- Export citation
4 - Game Theory and Mechanism Design
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 140-166
-
- Chapter
- Export citation
6 - The Human Advantage
-
- Book:
- Artificial Intelligence in Schools
- Published online:
- 24 December 2025
- Print publication:
- 30 October 2025, pp 149-159
-
- Chapter
- Export citation
8 - Graph Theory, Combinatorial Optimization, and Supply Chains
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 250-278
-
- Chapter
- Export citation
3 - Queueing Theory and Resource Allocation
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 111-139
-
- Chapter
- Export citation
7 - Data Analysis
-
- Book:
- Insight-Driven Problem Solving
- Published online:
- 21 October 2025
- Print publication:
- 30 October 2025, pp 207-249
-
- Chapter
- Export citation
