Refine search
Actions for selected content:
48287 results in Computer Science
6 - Design Comes to the Law School
-
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp 109-125
-
- Chapter
- Export citation
4 - Scaling the Gap
-
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp 73-91
-
- Chapter
- Export citation
8 - Same As It Ever Was?
-
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp 147-165
-
- Chapter
- Export citation
Contents
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp v-vi
-
- Chapter
- Export citation
Part I - Mathematical Optimization
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 19-20
-
- Chapter
- Export citation
1 - Do Lawyers Need to Learn to Code?
-
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp 18-37
-
- Chapter
- Export citation
Part III - Nonlinear Learning
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 273-274
-
- Chapter
- Export citation
4 - Mining Data Streams
-
- Book:
- Mining of Massive Datasets
- Published online:
- 16 April 2020
- Print publication:
- 09 January 2020, pp 138-168
-
- Chapter
- Export citation
Figures
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp vii-vii
-
- Chapter
- Export citation
9 - Ludic Legal Education from Cicero to Phoenix Wright
-
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp 166-185
-
- Chapter
- Export citation
Appendix C - Linear Algebra
- from Part IV - Appendices
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 546-563
-
- Chapter
- Export citation
References
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 564-568
-
- Chapter
- Export citation
12 - Large-Scale Machine Learning
-
- Book:
- Mining of Massive Datasets
- Published online:
- 16 April 2020
- Print publication:
- 09 January 2020, pp 441-497
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Modernising Legal Education
- Published online:
- 30 December 2019
- Print publication:
- 09 January 2020, pp iv-iv
-
- Chapter
- Export citation
9 - Feature Engineering and Selection
- from Part II - Linear Learning
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 237-272
-
- Chapter
- Export citation
11 - Principles of Feature Learning
- from Part III - Nonlinear Learning
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 304-382
-
- Chapter
- Export citation
5 - Linear Regression
- from Part II - Linear Learning
-
- Book:
- Machine Learning Refined
- Published online:
- 05 February 2020
- Print publication:
- 09 January 2020, pp 99-124
-
- Chapter
- Export citation
Contents
-
- Book:
- Mining of Massive Datasets
- Published online:
- 16 April 2020
- Print publication:
- 09 January 2020, pp v-viii
-
- Chapter
- Export citation
EXPLICIT SOLUTIONS FOR CONTINUOUS-TIME QBD PROCESSES BY USING RELATIONS BETWEEN MATRIX GEOMETRIC ANALYSIS AND THE PROBABILITY GENERATING FUNCTIONS METHOD
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 03 January 2020, pp. 565-580
-
- Article
- Export citation
-
Two main methods are used to solve continuous-time quasi birth-and-death processes: matrix geometric (MG) and probability generating functions (PGFs). MG requires a numerical solution (via successive substitutions) of a matrix quadratic equation A0 + RA1 + R2A2 = 0. PGFs involve a row vector
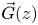 $\vec{G}(z)$ of unknown generating functions satisfying
$\vec{G}(z)$ of unknown generating functions satisfying 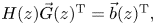 $H(z)\vec{G}{(z)^\textrm{T}} = \vec{b}{(z)^\textrm{T}},$ where the row vector
$H(z)\vec{G}{(z)^\textrm{T}} = \vec{b}{(z)^\textrm{T}},$ where the row vector 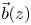 $\vec{b}(z)$ contains unknown “boundary” probabilities calculated as functions of roots of the matrix H(z). We show that: (a) H(z) and
$\vec{b}(z)$ contains unknown “boundary” probabilities calculated as functions of roots of the matrix H(z). We show that: (a) H(z) and 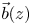 $\vec{b}(z)$ can be explicitly expressed in terms of the triple A0, A1, and A2; (b) when each matrix of the triple is lower (or upper) triangular, then (i) R can be explicitly expressed in terms of roots of
$\vec{b}(z)$ can be explicitly expressed in terms of the triple A0, A1, and A2; (b) when each matrix of the triple is lower (or upper) triangular, then (i) R can be explicitly expressed in terms of roots of 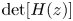 $\det [H(z)]$; and (ii) the stability condition is readily extracted.
$\det [H(z)]$; and (ii) the stability condition is readily extracted.
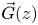
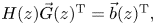
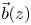
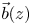
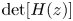
Community structure: A comparative evaluation of community detection methods
-
- Journal:
- Network Science / Volume 8 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 03 January 2020, pp. 1-41
-
- Article
- Export citation
