Refine search
Actions for selected content:
48287 results in Computer Science
Multiple feature regularized kernel for hyperspectral imagery classification
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 26 March 2020, e10
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
High dynamic range image compression based on visual saliency
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 27 May 2020, e16
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A study for 2-D indoor localization using multiple leaky coaxial cables
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 25 September 2020, e20
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NLCA-Net: a non-local context attention network for stereo matching
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 07 July 2020, e18
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Accurate disparity prediction is a hot spot in computer vision, and how to efficiently exploit contextual information is the key to improve the performance. In this paper, we propose a simple yet effective non-local context attention network to exploit the global context information by using attention mechanisms and semantic information for stereo matching. First, we develop a 2D geometry feature learning module to get a more discriminative representation by taking advantage of multi-scale features and form them into the variance-based cost volume. Then, we construct a non-local attention matching module by using the non-local block and hierarchical 3D convolutions, which can effectively regularize the cost volume and capture the global contextual information. Finally, we adopt a geometry refinement module to refine the disparity map to further improve the performance. Moreover, we add the warping loss function to help the model learn the matching rule of the non-occluded region. Our experiments show that (1) our approach achieves competitive results on KITTI and SceneFlow datasets in the end-point error and the fraction of erroneous pixels $({D_1})$
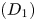 ; (2) our proposed method particularly has superior performance in the reflective regions and occluded areas.
; (2) our proposed method particularly has superior performance in the reflective regions and occluded areas.
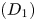
Color-gamut mapping in the non-uniform CIE-1931 space with perceptual hue fidelity constraints for SMPTE ST.2094-40 standard
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 31 March 2020, e12
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Vision and language: from visual perception to content creation
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 30 March 2020, e11
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PortraitGAN for flexible portrait manipulation
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 06 October 2020, e22
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Learning priors for adversarial autoencoders
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 20 January 2020, e4
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Signal denoising using the minimum-probability-of-error criterion
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 20 January 2020, e3
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dimensional speech emotion recognition from speech features and word embeddings by using multitask learning
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 27 May 2020, e17
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
End-to-end recognition of streaming Japanese speech using CTC and local attention
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 23 November 2020, e25
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Theoretical analysis of skip connections and batch normalization from generalization and optimization perspectives
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 27 February 2020, e9
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toward human-centric deep video understanding
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 13 January 2020, e1
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ground-distance segmentation of 3D LiDAR point cloud toward autonomous driving
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 23 November 2020, e24
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
DSNet: an efficient CNN for road scene segmentation
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 26 November 2020, e27
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A multi-branch ResNet with discriminative features for detection of replay speech signals
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 29 December 2020, e28
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Advances in anti-spoofing: from the perspective of ASVspoof challenges
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 15 January 2020, e2
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An Overview of Coding Tools in AV1: the First Video Codec from the Alliance for Open Media
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 24 February 2020, e6
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An overview of ongoing point cloud compression standardization activities: video-based (V-PCC) and geometry-based (G-PCC)
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 03 April 2020, e13
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An SMLB-based OFDM receiver over impulsive noise environment
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 9 / 2020
- Published online by Cambridge University Press:
- 20 November 2020, e23
- Print publication:
- 2020
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
