Refine search
Actions for selected content:
48282 results in Computer Science
Founded (Auto)Epistemic Equilibrium Logic Satisfies Epistemic Splitting
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 671-687
-
- Article
-
- You have access
- Open access
- Export citation
Abstract Solvers for Computing Cautious Consequences of ASP programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 740-756
-
- Article
- Export citation
Resource Analysis driven by (Conditional) Termination Proofs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 722-739
-
- Article
- Export citation
Enhancing Magic Sets with an Application to Ontological Reasoning
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 654-670
-
- Article
- Export citation
About Epistemic Negation and World Views in Epistemic Logic Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 790-807
-
- Article
- Export citation
On the Equivalence Between Abstract Dialectical Frameworks and Logic Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 941-956
-
- Article
- Export citation
Partial Compilation of ASP Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 857-873
-
- Article
- Export citation
Online Event Recognition from Moving Vehicles: Application Paper
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 841-856
-
- Article
- Export citation
On Uniform Equivalence of Epistemic Logic Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 826-840
-
- Article
- Export citation
Inconsistency Proofs for ASP: The ASP - DRUPE Format
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 891-907
-
- Article
- Export citation
Better Paracoherent Answer Sets with Less Resources
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 757-772
-
- Article
- Export citation
Relating Two Dialects of Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 1006-1020
-
- Article
- Export citation
Paracoherent Answer Set Semantics meets Argumentation Frameworks
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 688-704
-
- Article
- Export citation
Twenty-five years of information extraction
-
- Journal:
- Natural Language Engineering / Volume 25 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 677-692
-
- Article
- Export citation
Positive contagion and the macrostructures of generalized balance
-
- Journal:
- Network Science / Volume 7 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 445-458
-
- Article
-
- You have access
- Open access
- Export citation
Automatic summarisation: 25 years On
-
- Journal:
- Natural Language Engineering / Volume 25 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 19 September 2019, pp. 735-751
-
- Article
- Export citation
Stars, holes, or paths across your Facebook friends: A graphlet-based characterization of many networks
-
- Journal:
- Network Science / Volume 7 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 19 September 2019, pp. 476-497
-
- Article
- Export citation
Pure iso-type systems
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 29 / 2019
- Published online by Cambridge University Press:
- 17 September 2019, e14
-
- Article
-
- You have access
- Export citation
Tenure trumps title: Assessing the logic of informant selection in inter-organizational network research
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 17 September 2019, pp. 402-421
-
- Article
- Export citation
SUBSTITUTION IN RELEVANT LOGICS
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 17 September 2019, pp. 655-680
- Print publication:
- September 2020
-
- Article
- Export citation
-
This essay discusses rules and semantic clauses relating to Substitution—Leibniz’s law in the conjunctive-implicational form
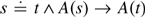 $s\dot{ = }t \wedge A\left( s \right) \to A\left( t \right)$—as these are put forward in Priest’s books In Contradiction and An Introduction to Non-Classical Logic: From If to Is. The stated rules and clauses are shown to be too weak in some cases and too strong in others. New ones are presented and shown to be correct. Justification for the various rules is probed and it is argued that Substitution ought to fail.
$s\dot{ = }t \wedge A\left( s \right) \to A\left( t \right)$—as these are put forward in Priest’s books In Contradiction and An Introduction to Non-Classical Logic: From If to Is. The stated rules and clauses are shown to be too weak in some cases and too strong in others. New ones are presented and shown to be correct. Justification for the various rules is probed and it is argued that Substitution ought to fail.