Refine search
Actions for selected content:
48274 results in Computer Science
3 - The Direction of Causation
-
- Book:
- Time and Causality across the Sciences
- Published online:
- 24 September 2019
- Print publication:
- 26 September 2019, pp 37-48
-
- Chapter
- Export citation

Time and Causality across the Sciences
-
- Published online:
- 24 September 2019
- Print publication:
- 26 September 2019
SOME LIMIT THEOREMS OF DELAYED AVERAGES FOR COUNTABLE NONHOMOGENEOUS MARKOV CHAINS
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 24 September 2019, pp. 297-315
-
- Article
- Export citation
EndNote: Feature-based classification of networks
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 23 September 2019, pp. 438-444
-
- Article
- Export citation
Uncovering the language of wine experts
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 23 September 2019, pp. 511-530
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Statistical evaluation of spectral methods for anomaly detection in static networks
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 23 September 2019, pp. 319-352
-
- Article
- Export citation
Transitivity correlation: A descriptive measure of network transitivity
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 23 September 2019, pp. 353-375
-
- Article
- Export citation
Values in adolescent friendship networks
-
- Journal:
- Network Science / Volume 7 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 23 September 2019, pp. 498-522
-
- Article
- Export citation
Bayesian dynamic modeling and monitoring of network flows
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 23 September 2019, pp. 292-318
-
- Article
- Export citation

Exploring Research Data Management
-
- Published by:
- Facet
- Published online:
- 21 September 2019
- Print publication:
- 11 May 2018
Control-Flow Refinement by Partial Evaluation, and its Application to Termination and Cost Analysis
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 990-1005
-
- Article
- Export citation
Beyond NP: Quantifying over Answer Sets
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 705-721
-
- Article
- Export citation
-
Answer Set Programming (ASP) is a logic programming paradigm featuring a purely declarative language with comparatively high modeling capabilities. Indeed, ASP can model problems in NP in a compact and elegant way. However, modeling problems beyond NP with ASP is known to be complicated, on the one hand, and limited to problems in
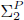 $\[\Sigma _2^P\]$ on the other. Inspired by the way Quantified Boolean Formulas extend SAT formulas to model problems beyond NP, we propose an extension of ASP that introduces quantifiers over stable models of programs. We name the new language ASP with Quantifiers (ASP(Q)). In the paper we identify computational properties of ASP(Q); we highlight its modeling capabilities by reporting natural encodings of several complex problems with applications in artificial intelligence and number theory; and we compare ASP(Q) with related languages. Arguably, ASP(Q) allows one to model problems in the Polynomial Hierarchy in a direct way, providing an elegant expansion of ASP beyond the class NP.
$\[\Sigma _2^P\]$ on the other. Inspired by the way Quantified Boolean Formulas extend SAT formulas to model problems beyond NP, we propose an extension of ASP that introduces quantifiers over stable models of programs. We name the new language ASP with Quantifiers (ASP(Q)). In the paper we identify computational properties of ASP(Q); we highlight its modeling capabilities by reporting natural encodings of several complex problems with applications in artificial intelligence and number theory; and we compare ASP(Q) with related languages. Arguably, ASP(Q) allows one to model problems in the Polynomial Hierarchy in a direct way, providing an elegant expansion of ASP beyond the class NP.
Evaluation of the Implementation of an Abstract Interpretation Algorithm using Tabled CLP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 1107-1123
-
- Article
- Export citation
Precomputing Datalog Evaluation Plans in Large-Scale Scenarios
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 1073-1089
-
- Article
- Export citation
PES volume 33 issue 4 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Querying Knowledge via Multi-Hop English Questions
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 636-653
-
- Article
- Export citation
Anti-unification in Constraint Logic Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 773-789
-
- Article
- Export citation
The Expressive Power of Higher-Order Datalog
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 925-940
-
- Article
- Export citation
Bridging Commonsense Reasoning and Probabilistic Planning via a Probabilistic Action Language
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 5-6 / September 2019
- Published online by Cambridge University Press:
- 20 September 2019, pp. 1090-1106
-
- Article
- Export citation
