Refine search
Actions for selected content:
48274 results in Computer Science
Index
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 201-203
-
- Chapter
- Export citation
9 - Information and Behavior Diffusion
- from PART III - DYNAMICAL PROCESSES
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 149-166
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp i-iv
-
- Chapter
- Export citation
Glossary
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 179-182
-
- Chapter
- Export citation
1 - Moving Out of Flatland
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 1-12
-
- Chapter
- Export citation
PART IV - CONCLUSION
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 167-168
-
- Chapter
- Export citation
10 - Future Directions
- from PART IV - CONCLUSION
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 169-178
-
- Chapter
- Export citation
3 - Measuring Multilayer Social Networks
- from PART I - MODELS AND MEASURES
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 38-64
-
- Chapter
- Export citation
PART I - MODELS AND MEASURES
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 13-14
-
- Chapter
- Export citation
PART II - MINING MULTILAYER NETWORKS
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 65-66
-
- Chapter
- Export citation
list of abbreviations
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp ix-x
-
- Chapter
- Export citation
4 - Data Collection and Preprocessing
- from PART II - MINING MULTILAYER NETWORKS
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 67-78
-
- Chapter
- Export citation
8 - Formation of Multilayer Social Networks
- from PART III - DYNAMICAL PROCESSES
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 133-148
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 183-200
-
- Chapter
- Export citation
Asymptotic behavior of the node degrees in the ensemble average of adjacency matrix
-
- Journal:
- Network Science / Volume 4 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 18 July 2016, pp. 385-399
-
- Article
-
- You have access
- Open access
- Export citation
6 - Community Detection
- from PART II - MINING MULTILAYER NETWORKS
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 96-118
-
- Chapter
- Export citation
THE LOGIC OF LEIBNIZ’S GENERALES INQUISITIONES DE ANALYSI NOTIONUM ET VERITATUM
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 4 / December 2016
- Published online by Cambridge University Press:
- 18 July 2016, pp. 686-751
- Print publication:
- December 2016
-
- Article
- Export citation
PART III - DYNAMICAL PROCESSES
-
- Book:
- Multilayer Social Networks
- Published online:
- 05 July 2016
- Print publication:
- 18 July 2016, pp 131-132
-
- Chapter
- Export citation
Skeleton composition versus stable process systems in Eden
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 26 / 2016
- Published online by Cambridge University Press:
- 15 July 2016, e11
-
- Article
-
- You have access
- Export citation
Distinct Distances on Algebraic Curves in the Plane
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 15 July 2016, pp. 99-117
-
- Article
- Export citation
-
Let S be a set of n points in
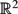 ${\mathbb R}^{2}$ contained in an algebraic curve C of degree d. We prove that the number of distinct distances determined by S is at least cdn 4/3, unless C contains a line or a circle.
${\mathbb R}^{2}$ contained in an algebraic curve C of degree d. We prove that the number of distinct distances determined by S is at least cdn 4/3, unless C contains a line or a circle.We also prove the lower bound cd ′ min{m 2/3 n 2/3, m 2, n 2} for the number of distinct distances between m points on one irreducible plane algebraic curve and n points on another, unless the two curves are parallel lines, orthogonal lines, or concentric circles. This generalizes a result on distances between lines of Sharir, Sheffer and Solymosi in [19].