Refine search
Actions for selected content:
48229 results in Computer Science
Triadic analysis of affiliation networks
-
- Journal:
- Network Science / Volume 3 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 22 December 2015, pp. 480-508
-
- Article
- Export citation
Manipulative Waiters with Probabilistic Intuition
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 21 December 2015, pp. 823-849
-
- Article
- Export citation
-
For positive integers n and q and a monotone graph property
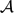 $\mathcal{A}$ , we consider the two-player, perfect information game WC(n, q, $\mathcal{A}$ ), which is defined as follows. The game proceeds in rounds. In each round, the first player, called Waiter, offers the second player, called Client, q + 1 edges of the complete graph Kn which have not been offered previously. Client then chooses one of these edges which he keeps and the remaining q edges go back to Waiter. If, at the end of the game, the graph which consists of the edges chosen by Client satisfies the property $\mathcal{A}$ , then Waiter is declared the winner; otherwise Client wins the game. In this paper we study such games (also known as Picker–Chooser games) for a variety of natural graph-theoretic parameters, such as the size of a largest component or the length of a longest cycle. In particular, we describe a phase transition type phenomenon which occurs when the parameter q is close to n and is reminiscent of phase transition phenomena in random graphs. Namely, we prove that if q ⩾ (1 + ϵ)n, then Client can avoid components of order cϵ−2 ln n for some absolute constant c > 0, whereas for q ⩽ (1 − ϵ)n, Waiter can force a giant, linearly sized component in Client's graph. In the second part of the paper, we prove that Waiter can force Client's graph to be pancyclic for every q ⩽ cn, where c > 0 is an appropriate constant. Note that this behaviour is in stark contrast to the threshold for pancyclicity and Hamiltonicity of random graphs.
$\mathcal{A}$ , we consider the two-player, perfect information game WC(n, q, $\mathcal{A}$ ), which is defined as follows. The game proceeds in rounds. In each round, the first player, called Waiter, offers the second player, called Client, q + 1 edges of the complete graph Kn which have not been offered previously. Client then chooses one of these edges which he keeps and the remaining q edges go back to Waiter. If, at the end of the game, the graph which consists of the edges chosen by Client satisfies the property $\mathcal{A}$ , then Waiter is declared the winner; otherwise Client wins the game. In this paper we study such games (also known as Picker–Chooser games) for a variety of natural graph-theoretic parameters, such as the size of a largest component or the length of a longest cycle. In particular, we describe a phase transition type phenomenon which occurs when the parameter q is close to n and is reminiscent of phase transition phenomena in random graphs. Namely, we prove that if q ⩾ (1 + ϵ)n, then Client can avoid components of order cϵ−2 ln n for some absolute constant c > 0, whereas for q ⩽ (1 − ϵ)n, Waiter can force a giant, linearly sized component in Client's graph. In the second part of the paper, we prove that Waiter can force Client's graph to be pancyclic for every q ⩽ cn, where c > 0 is an appropriate constant. Note that this behaviour is in stark contrast to the threshold for pancyclicity and Hamiltonicity of random graphs.
Local Maxima of Quadratic Boolean Functions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 21 December 2015, pp. 633-640
-
- Article
- Export citation
-
How many strict local maxima can a real quadratic function on {0, 1}n have? Holzman conjectured a maximum of
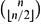 $\binom{n }{ \lfloor n/2 \rfloor}$ . The aim of this paper is to prove this conjecture. Our approach is via a generalization of Sperner's theorem that may be of independent interest.
$\binom{n }{ \lfloor n/2 \rfloor}$ . The aim of this paper is to prove this conjecture. Our approach is via a generalization of Sperner's theorem that may be of independent interest.
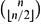
THE RUNNING MAXIMUM OF A LEVEL-DEPENDENT QUASI-BIRTH-DEATH PROCESS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 2 / April 2016
- Published online by Cambridge University Press:
- 21 December 2015, pp. 212-223
-
- Article
- Export citation

Big Data over Networks
-
- Published online:
- 18 December 2015
- Print publication:
- 14 January 2016
Preface
-
-
- Book:
- Design and Deployment of Small Cell Networks
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp xv-xvi
-
- Chapter
- Export citation
14 - The art of deploying small cells: field trial experiments, system design, performance prediction, and deployment feasibility
-
-
- Book:
- Design and Deployment of Small Cell Networks
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp 338-362
-
- Chapter
- Export citation
17 - Factoring finite-state machines
- from Part IV - Synchronous sequential logic
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp 375-397
-
- Chapter
- Export citation
Contents
-
- Book:
- Essentials of Programming in <I>Mathematica</I>®
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp vii-x
-
- Chapter
- Export citation
5 - Functions
-
- Book:
- Essentials of Programming in <I>Mathematica</I>®
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp 133-208
-
- Chapter
- Export citation
10 - Arithmetic circuits
- from Part III - Arithmetic circuits
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp 221-249
-
- Chapter
- Export citation
11 - Game theory and learning techniques for self-organization in small cell networks
-
-
- Book:
- Design and Deployment of Small Cell Networks
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp 242-283
-
- Chapter
- Export citation
21 - System-level design
- from Part VI - System design
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp 467-478
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Essentials of Programming in <I>Mathematica</I>®
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp xi-xvi
-
- Chapter
- Export citation
Preface
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp xv-xix
-
- Chapter
- Export citation
25 - Memory systems
- from Part VI - System design
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp 532-548
-
- Chapter
- Export citation
Appendix A - VHDL coding style
- from Part VIII - Appendix: VHDL coding style and syntax guide
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp 611-621
-
- Chapter
- Export citation
20 - Verification and test
- from Part V - Practical design
-
- Book:
- Digital Design Using VHDL
- Published online:
- 01 February 2019
- Print publication:
- 17 December 2015, pp 453-464
-
- Chapter
- Export citation
Dedication
-
- Book:
- Essentials of Programming in <I>Mathematica</I>®
- Published online:
- 05 December 2015
- Print publication:
- 17 December 2015, pp v-vi
-
- Chapter
- Export citation
Teaching types with a cognitively effective worked example format
-
- Journal:
- Journal of Functional Programming / Volume 25 / 2015
- Published online by Cambridge University Press:
- 17 December 2015, e23
-
- Article
-
- You have access
- Export citation
