Refine search
Actions for selected content:
48229 results in Computer Science
Moving object detection in the H.264/AVC compressed domain
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 21 November 2016, e18
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Occlusion-aware temporal frame interpolation in a highly scalable video coding setting
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 01 April 2016, e8
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Nested Gibbs sampling for mixture-of-mixture model and its application to speaker clustering
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 31 August 2016, e16
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multi-modal sensing and analysis of poster conversations with smart posterboard
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 02 March 2016, e2
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lossless image coding using hierarchical decomposition and recursive partitioning
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 09 September 2016, e17
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Deep neural networks – a developmental perspective
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 01 April 2016, e7
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the sum of the square of a prime and a square-free number
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue 1 / 2016
- Published online by Cambridge University Press:
- 01 January 2016, pp. 16-24
-
- Article
-
- You have access
- Export citation
-
We prove that every integer
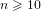 $n\geqslant 10$ such that
$n\geqslant 10$ such that 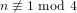 $n\not \equiv 1\text{ mod }4$ can be written as the sum of the square of a prime and a square-free number. This makes explicit a theorem of Erdős that every sufficiently large integer of this type may be written in such a way. Our proof requires us to construct new explicit results for primes in arithmetic progressions. As such, we use the second author’s numerical computation regarding the generalised Riemann hypothesis to extend the explicit bounds of Ramaré–Rumely.
$n\not \equiv 1\text{ mod }4$ can be written as the sum of the square of a prime and a square-free number. This makes explicit a theorem of Erdős that every sufficiently large integer of this type may be written in such a way. Our proof requires us to construct new explicit results for primes in arithmetic progressions. As such, we use the second author’s numerical computation regarding the generalised Riemann hypothesis to extend the explicit bounds of Ramaré–Rumely.
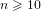
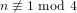
Digital health in the age of The Infinite Network
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 5 / 2016
- Published online by Cambridge University Press:
- 28 March 2016, e5
- Print publication:
- 2016
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Counting and generating terms in the binary lambda calculus*
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 25 / 2015
- Published online by Cambridge University Press:
- 29 December 2015, e24
-
- Article
-
- You have access
- Export citation
Isomorphism theorems between models of mixed choice
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 6 / September 2017
- Published online by Cambridge University Press:
- 28 December 2015, pp. 1032-1067
-
- Article
- Export citation
The Multiple-Orientability Thresholds for Random Hypergraphs†
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 28 December 2015, pp. 870-908
-
- Article
- Export citation
PES volume 30 issue 1 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 23 December 2015, pp. b1-b2
-
- Article
-
- You have access
- Export citation
PES volume 30 issue 1 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 23 December 2015, pp. f1-f2
-
- Article
-
- You have access
- Export citation
NWS volume 3 issue 4 Cover and Back matter
-
- Journal:
- Network Science / Volume 3 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 22 December 2015, pp. b1-b2
-
- Article
-
- You have access
- Export citation
NWS volume 3 issue 4 Cover and Front matter
-
- Journal:
- Network Science / Volume 3 / Issue 4 / December 2015
- Published online by Cambridge University Press:
- 22 December 2015, pp. f1-f3
-
- Article
-
- You have access
- Export citation
ROB volume 34 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
FROM STENIUS’ CONSISTENCY PROOF TO SCHÜTTE’S CUT ELIMINATION FOR ω-ARITHMETIC
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 1 / March 2016
- Published online by Cambridge University Press:
- 22 December 2015, pp. 1-22
- Print publication:
- March 2016
-
- Article
- Export citation
PROPOSITIONAL CONTINGENTISM
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 1 / March 2016
- Published online by Cambridge University Press:
- 22 December 2015, pp. 123-142
- Print publication:
- March 2016
-
- Article
-
- You have access
- Export citation
ROB volume 34 issue 2 Cover and Front matter
-
- Article
-
- You have access
- Export citation
