Refine search
Actions for selected content:
2540 results in Computational Science
Restricting unipotent characters in special orthogonal groups
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 18 / Issue 1 / 2015
- Published online by Cambridge University Press:
- 01 July 2015, pp. 456-488
-
- Article
-
- You have access
- Export citation
-
For all prime powers
 $q$ we restrict the unipotent characters of the special orthogonal groups
$q$ we restrict the unipotent characters of the special orthogonal groups 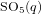 $\text{SO}_{5}(q)$ and
$\text{SO}_{5}(q)$ and 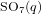 $\text{SO}_{7}(q)$ to a maximal parabolic subgroup. We determine all irreducible constituents of these restrictions for
$\text{SO}_{7}(q)$ to a maximal parabolic subgroup. We determine all irreducible constituents of these restrictions for 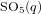 $\text{SO}_{5}(q)$ and a large part of the irreducible constituents for
$\text{SO}_{5}(q)$ and a large part of the irreducible constituents for 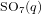 $\text{SO}_{7}(q)$ .
$\text{SO}_{7}(q)$ .

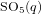
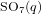
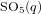
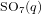
Heuristics on pairing-friendly abelian varieties
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 18 / Issue 1 / 2015
- Published online by Cambridge University Press:
- 01 June 2015, pp. 419-443
-
- Article
-
- You have access
- Export citation
-
We discuss heuristic asymptotic formulae for the number of isogeny classes of pairing-friendly abelian varieties of fixed dimension
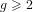 $g\geqslant 2$ over prime finite fields. In each formula, the embedding degree
$g\geqslant 2$ over prime finite fields. In each formula, the embedding degree 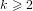 $k\geqslant 2$ is fixed and the rho-value is bounded above by a fixed real
$k\geqslant 2$ is fixed and the rho-value is bounded above by a fixed real 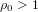 ${\it\rho}_{0}>1$ . The first formula involves families of ordinary abelian varieties whose endomorphism ring contains an order in a fixed CM-field
${\it\rho}_{0}>1$ . The first formula involves families of ordinary abelian varieties whose endomorphism ring contains an order in a fixed CM-field 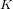 $K$ of degree
$K$ of degree  $g$ and generalizes previous work of the first author when
$g$ and generalizes previous work of the first author when 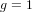 $g=1$ . It suggests that, when
$g=1$ . It suggests that, when 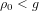 ${\it\rho}_{0}<g$ , there are only finitely many such isogeny classes. On the other hand, there should be infinitely many such isogeny classes when
${\it\rho}_{0}<g$ , there are only finitely many such isogeny classes. On the other hand, there should be infinitely many such isogeny classes when 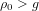 ${\it\rho}_{0}>g$ . The second formula involves families whose endomorphism ring contains an order in a fixed totally real field
${\it\rho}_{0}>g$ . The second formula involves families whose endomorphism ring contains an order in a fixed totally real field 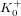 $K_{0}^{+}$ of degree
$K_{0}^{+}$ of degree  $g$ . It suggests that, when
$g$ . It suggests that, when 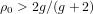 ${\it\rho}_{0}>2g/(g+2)$ (and in particular when
${\it\rho}_{0}>2g/(g+2)$ (and in particular when 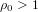 ${\it\rho}_{0}>1$ if
${\it\rho}_{0}>1$ if 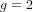 $g=2$ ), there are infinitely many isogeny classes of
$g=2$ ), there are infinitely many isogeny classes of  $g$ -dimensional abelian varieties over prime fields whose endomorphism ring contains an order of
$g$ -dimensional abelian varieties over prime fields whose endomorphism ring contains an order of 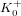 $K_{0}^{+}$ . We also discuss the impact that polynomial families of pairing-friendly abelian varieties has on our heuristics, and review the known cases where they are expected to provide more isogeny classes than predicted by our heuristic formulae.
$K_{0}^{+}$ . We also discuss the impact that polynomial families of pairing-friendly abelian varieties has on our heuristics, and review the known cases where they are expected to provide more isogeny classes than predicted by our heuristic formulae.
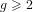
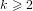
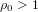
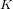

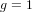
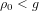
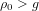
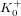

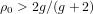
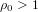
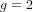

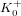
1 - Prologue: how to produce forecasts
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 1-30
-
- Chapter
- Export citation
Index
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 295-297
-
- Chapter
- Export citation
A postscript
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 288-288
-
- Chapter
- Export citation
9 - Dealing with imperfect models
- from Part II - Bayesian Data Assimilation
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 259-287
-
- Chapter
- Export citation
Part I - Quantifying Uncertainty
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 31-32
-
- Chapter
- Export citation
Preface
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp vii-x
-
- Chapter
- Export citation
Contents
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp v-vi
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp i-iv
-
- Chapter
- Export citation
8 - Data assimilation for spatio-temporal processes
- from Part II - Bayesian Data Assimilation
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 229-258
-
- Chapter
- Export citation
6 - Basic data assimilation algorithms
- from Part II - Bayesian Data Assimilation
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 171-199
-
- Chapter
- Export citation
5 - Bayesian inference
- from Part I - Quantifying Uncertainty
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 131-168
-
- Chapter
- Export citation
7 - McKean approach to data assimilation
- from Part II - Bayesian Data Assimilation
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 200-228
-
- Chapter
- Export citation
4 - Stochastic processes
- from Part I - Quantifying Uncertainty
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 96-130
-
- Chapter
- Export citation
Part II - Bayesian Data Assimilation
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 169-170
-
- Chapter
- Export citation
2 - Introduction to probability
- from Part I - Quantifying Uncertainty
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 33-64
-
- Chapter
- Export citation
References
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 289-294
-
- Chapter
- Export citation
3 - Computational statistics
- from Part I - Quantifying Uncertainty
-
- Book:
- Probabilistic Forecasting and Bayesian Data Assimilation
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015, pp 65-95
-
- Chapter
- Export citation

Probabilistic Forecasting and Bayesian Data Assimilation
-
- Published online:
- 05 May 2015
- Print publication:
- 14 May 2015
