Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
On the choosability of
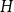 $H$-minor-free graphs
$H$-minor-free graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 03 November 2023, pp. 129-142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a graph
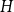 $H$, let us denote by
$H$, let us denote by 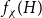 $f_\chi (H)$ and
$f_\chi (H)$ and 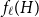 $f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of
$f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of 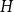 $H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that
$H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that 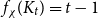 $f_\chi (K_t)=t-1$ for every
$f_\chi (K_t)=t-1$ for every 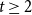 $t \ge 2$. A closely related problem that has received significant attention in the past concerns
$t \ge 2$. A closely related problem that has received significant attention in the past concerns 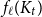 $f_\ell (K_t)$, for which it is known that
$f_\ell (K_t)$, for which it is known that 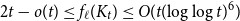 $2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus,
$2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus, 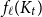 $f_\ell (K_t)$ is bounded away from the conjectured value
$f_\ell (K_t)$ is bounded away from the conjectured value 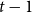 $t-1$ for
$t-1$ for 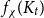 $f_\chi (K_t)$ by at least a constant factor. The so-called
$f_\chi (K_t)$ by at least a constant factor. The so-called 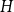 $H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that
$H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that 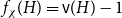 $f_\chi (H)={\textrm{v}}(H)-1$ for a given graph
$f_\chi (H)={\textrm{v}}(H)-1$ for a given graph 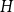 $H$ (which would be implied by Hadwiger’s conjecture).
$H$ (which would be implied by Hadwiger’s conjecture).In this paper, we prove several new lower bounds on
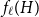 $f_\ell (H)$, thus exploring the limits of a list colouring extension of
$f_\ell (H)$, thus exploring the limits of a list colouring extension of 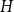 $H$-Hadwiger’s conjecture. Our main results are:
$H$-Hadwiger’s conjecture. Our main results are:For every
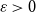 $\varepsilon \gt 0$ and all sufficiently large graphs
$\varepsilon \gt 0$ and all sufficiently large graphs 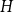 $H$ we have
$H$ we have 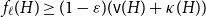 $f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where
$f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where 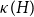 $\kappa (H)$ denotes the vertex-connectivity of
$\kappa (H)$ denotes the vertex-connectivity of 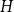 $H$.
$H$.For every
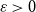 $\varepsilon \gt 0$ there exists
$\varepsilon \gt 0$ there exists 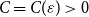 $C=C(\varepsilon )\gt 0$ such that asymptotically almost every
$C=C(\varepsilon )\gt 0$ such that asymptotically almost every  $n$-vertex graph
$n$-vertex graph 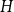 $H$ with
$H$ with 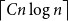 $\left \lceil C n\log n\right \rceil$ edges satisfies
$\left \lceil C n\log n\right \rceil$ edges satisfies 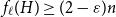 $f_\ell (H)\ge (2-\varepsilon )n$.
$f_\ell (H)\ge (2-\varepsilon )n$.
The first result generalizes recent results on complete and complete bipartite graphs and shows that the list chromatic number of
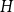 $H$-minor-free graphs is separated from the desired value of
$H$-minor-free graphs is separated from the desired value of 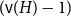 $({\textrm{v}}(H)-1)$ by a constant factor for all large graphs
$({\textrm{v}}(H)-1)$ by a constant factor for all large graphs 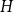 $H$ of linear connectivity. The second result tells us that for almost all graphs
$H$ of linear connectivity. The second result tells us that for almost all graphs 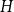 $H$ with superlogarithmic average degree
$H$ with superlogarithmic average degree 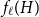 $f_\ell (H)$ is separated from
$f_\ell (H)$ is separated from 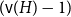 $({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to
$({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to 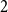 $2$. Conceptually these results indicate that the graphs
$2$. Conceptually these results indicate that the graphs 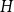 $H$ for which
$H$ for which 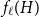 $f_\ell (H)$ is close to the conjectured value
$f_\ell (H)$ is close to the conjectured value 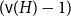 $({\textrm{v}}(H)-1)$ for
$({\textrm{v}}(H)-1)$ for 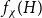 $f_\chi (H)$ are typically rather sparse.
$f_\chi (H)$ are typically rather sparse.
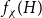
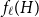
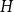
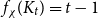
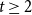
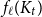
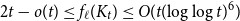
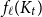
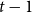
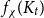
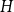
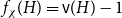
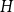
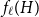
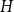
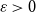
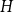
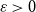
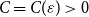

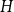
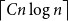
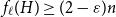
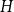
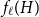
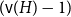
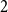
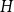
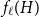
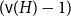
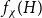
19 - Structure Constants
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 350-369
-
- Chapter
- Export citation
15 - Homogeneous Varieties
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 265-289
-
- Chapter
- Export citation
14 - Symplectic Schubert Polynomials
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 240-264
-
- Chapter
- Export citation
Appendix A - Algebraic Topology
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 370-387
-
- Chapter
- Export citation
2 - Defining Equivariant Cohomology
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 9-25
-
- Chapter
- Export citation
Preface
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp xi-xvi
-
- Chapter
- Export citation
11 - Degeneracy Loci
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 182-207
-
- Chapter
- Export citation
6 - Conics
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 79-92
-
- Chapter
- Export citation
9 - Schubert Calculus on Grassmannians
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 126-151
-
- Chapter
- Export citation
16 - The Algebra of Divided Difference Operators
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 290-310
-
- Chapter
- Export citation
17 - Equivariant Homology
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 311-325
-
- Chapter
- Export citation
8 - Toric Varieties
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 113-125
-
- Chapter
- Export citation
12 - Infinite-Dimensional Flag Varieties
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 208-225
-
- Chapter
- Export citation
Appendix C - Pfaffians and Q-polynomials
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 392-405
-
- Chapter
- Export citation
Appendix E - Characteristic Classes and Equivariant Cohomology
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 415-419
-
- Chapter
- Export citation
7 - Localization II
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 93-112
-
- Chapter
- Export citation
1 - Preview
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 1-8
-
- Chapter
- Export citation
13 - Symplectic Flag Varieties
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 226-239
-
- Chapter
- Export citation
Subject Index
-
- Book:
- Equivariant Cohomology in Algebraic Geometry
- Published online:
- 07 October 2023
- Print publication:
- 26 October 2023, pp 435-446
-
- Chapter
- Export citation
