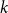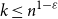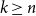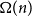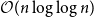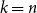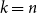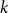Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
6 - Laurent series, amoebas, and convex geometry
- from Part II - Mathematical Background
-
- Book:
- Analytic Combinatorics in Several Variables
- Published online:
- 08 February 2024
- Print publication:
- 15 February 2024, pp 134-166
-
- Chapter
- Export citation
2 - Generating functions
- from Part I - Combinatorial Enumeration
-
- Book:
- Analytic Combinatorics in Several Variables
- Published online:
- 08 February 2024
- Print publication:
- 15 February 2024, pp 17-59
-
- Chapter
- Export citation
Dedication
-
- Book:
- Analytic Combinatorics in Several Variables
- Published online:
- 08 February 2024
- Print publication:
- 15 February 2024, pp v-vi
-
- Chapter
- Export citation
8 - Effective computations and ACSV
- from Part III - Multivariate Enumeration
-
- Book:
- Analytic Combinatorics in Several Variables
- Published online:
- 08 February 2024
- Print publication:
- 15 February 2024, pp 221-244
-
- Chapter
- Export citation
10 - Multiple point asymptotics
- from Part III - Multivariate Enumeration
-
- Book:
- Analytic Combinatorics in Several Variables
- Published online:
- 08 February 2024
- Print publication:
- 15 February 2024, pp 291-338
-
- Chapter
- Export citation

Analytic Combinatorics in Several Variables
-
- Published online:
- 08 February 2024
- Print publication:
- 15 February 2024

Algebraic Combinatorics and the Monster Group
-
- Published online:
- 05 January 2024
- Print publication:
- 17 August 2023
Percolation on irregular high-dimensional product graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 20 December 2023, pp. 377-403
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider bond percolation on high-dimensional product graphs
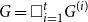 $G=\square _{i=1}^tG^{(i)}$, where
$G=\square _{i=1}^tG^{(i)}$, where  $\square$ denotes the Cartesian product. We call the
$\square$ denotes the Cartesian product. We call the 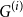 $G^{(i)}$ the base graphs and the product graph
$G^{(i)}$ the base graphs and the product graph 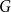 $G$ the host graph. Very recently, Lichev (J. Graph Theory, 99(4):651–670, 2022) showed that, under a mild requirement on the isoperimetric properties of the base graphs, the component structure of the percolated graph
$G$ the host graph. Very recently, Lichev (J. Graph Theory, 99(4):651–670, 2022) showed that, under a mild requirement on the isoperimetric properties of the base graphs, the component structure of the percolated graph 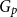 $G_p$ undergoes a phase transition when
$G_p$ undergoes a phase transition when 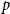 $p$ is around
$p$ is around 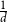 $\frac{1}{d}$, where
$\frac{1}{d}$, where 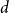 $d$ is the average degree of the host graph.
$d$ is the average degree of the host graph.In the supercritical regime, we strengthen Lichev’s result by showing that the giant component is in fact unique, with all other components of order
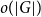 $o(|G|)$, and determining the sharp asymptotic order of the giant. Furthermore, we answer two questions posed by Lichev (J. Graph Theory, 99(4):651–670, 2022): firstly, we provide a construction showing that the requirement of bounded degree is necessary for the likely emergence of a linear order component; secondly, we show that the isoperimetric requirement on the base graphs can be, in fact, super-exponentially small in the dimension. Finally, in the subcritical regime, we give an example showing that in the case of irregular high-dimensional product graphs, there can be a polynomially large component with high probability, very much unlike the quantitative behaviour seen in the Erdős-Rényi random graph and in the percolated hypercube, and in fact in any regular high-dimensional product graphs, as shown by the authors in a companion paper (Percolation on high-dimensional product graphs. arXiv:2209.03722, 2022).
$o(|G|)$, and determining the sharp asymptotic order of the giant. Furthermore, we answer two questions posed by Lichev (J. Graph Theory, 99(4):651–670, 2022): firstly, we provide a construction showing that the requirement of bounded degree is necessary for the likely emergence of a linear order component; secondly, we show that the isoperimetric requirement on the base graphs can be, in fact, super-exponentially small in the dimension. Finally, in the subcritical regime, we give an example showing that in the case of irregular high-dimensional product graphs, there can be a polynomially large component with high probability, very much unlike the quantitative behaviour seen in the Erdős-Rényi random graph and in the percolated hypercube, and in fact in any regular high-dimensional product graphs, as shown by the authors in a companion paper (Percolation on high-dimensional product graphs. arXiv:2209.03722, 2022).
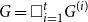

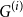
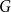
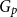
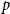
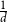
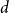
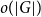

Product structure of graph classes with bounded treewidth
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 07 December 2023, pp. 351-376
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that many graphs with bounded treewidth can be described as subgraphs of the strong product of a graph with smaller treewidth and a bounded-size complete graph. To this end, define the underlying treewidth of a graph class
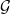 $\mathcal{G}$ to be the minimum non-negative integer
$\mathcal{G}$ to be the minimum non-negative integer  $c$ such that, for some function
$c$ such that, for some function 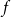 $f$, for every graph
$f$, for every graph 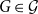 $G \in \mathcal{G}$ there is a graph
$G \in \mathcal{G}$ there is a graph 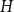 $H$ with
$H$ with 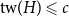 $\textrm{tw}(H) \leqslant c$ such that
$\textrm{tw}(H) \leqslant c$ such that 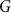 $G$ is isomorphic to a subgraph of
$G$ is isomorphic to a subgraph of 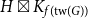 $H \boxtimes K_{f(\textrm{tw}(G))}$. We introduce disjointed coverings of graphs and show they determine the underlying treewidth of any graph class. Using this result, we prove that the class of planar graphs has underlying treewidth
$H \boxtimes K_{f(\textrm{tw}(G))}$. We introduce disjointed coverings of graphs and show they determine the underlying treewidth of any graph class. Using this result, we prove that the class of planar graphs has underlying treewidth 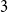 $3$; the class of
$3$; the class of 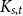 $K_{s,t}$-minor-free graphs has underlying treewidth
$K_{s,t}$-minor-free graphs has underlying treewidth  $s$ (for
$s$ (for 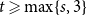 $t \geqslant \max \{s,3\}$); and the class of
$t \geqslant \max \{s,3\}$); and the class of 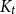 $K_t$-minor-free graphs has underlying treewidth
$K_t$-minor-free graphs has underlying treewidth  $t-2$. In general, we prove that a monotone class has bounded underlying treewidth if and only if it excludes some fixed topological minor. We also study the underlying treewidth of graph classes defined by an excluded subgraph or excluded induced subgraph. We show that the class of graphs with no
$t-2$. In general, we prove that a monotone class has bounded underlying treewidth if and only if it excludes some fixed topological minor. We also study the underlying treewidth of graph classes defined by an excluded subgraph or excluded induced subgraph. We show that the class of graphs with no 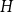 $H$ subgraph has bounded underlying treewidth if and only if every component of
$H$ subgraph has bounded underlying treewidth if and only if every component of 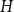 $H$ is a subdivided star, and that the class of graphs with no induced
$H$ is a subdivided star, and that the class of graphs with no induced 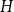 $H$ subgraph has bounded underlying treewidth if and only if every component of
$H$ subgraph has bounded underlying treewidth if and only if every component of 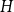 $H$ is a star.
$H$ is a star.

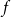
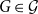
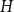
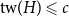
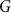
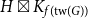
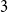
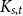

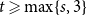
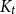

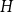
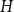
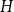
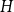
On minimum spanning trees for random Euclidean bipartite graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 30 November 2023, pp. 319-350
-
- Article
- Export citation
-
We consider the minimum spanning tree problem on a weighted complete bipartite graph
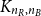 $K_{n_R, n_B}$ whose
$K_{n_R, n_B}$ whose 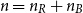 $n=n_R+n_B$ vertices are random, i.i.d. uniformly distributed points in the unit cube in
$n=n_R+n_B$ vertices are random, i.i.d. uniformly distributed points in the unit cube in 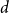 $d$ dimensions and edge weights are the
$d$ dimensions and edge weights are the 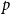 $p$-th power of their Euclidean distance, with
$p$-th power of their Euclidean distance, with 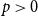 $p\gt 0$. In the large
$p\gt 0$. In the large  $n$ limit with
$n$ limit with 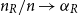 $n_R/n \to \alpha _R$ and
$n_R/n \to \alpha _R$ and 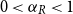 $0\lt \alpha _R\lt 1$, we show that the maximum vertex degree of the tree grows logarithmically, in contrast with the classical, non-bipartite, case, where a uniform bound holds depending on
$0\lt \alpha _R\lt 1$, we show that the maximum vertex degree of the tree grows logarithmically, in contrast with the classical, non-bipartite, case, where a uniform bound holds depending on 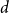 $d$ only. Despite this difference, for
$d$ only. Despite this difference, for 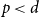 $p\lt d$, we are able to prove that the total edge costs normalized by the rate
$p\lt d$, we are able to prove that the total edge costs normalized by the rate 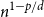 $n^{1-p/d}$ converge to a limiting constant that can be represented as a series of integrals, thus extending a classical result of Avram and Bertsimas to the bipartite case and confirming a conjecture of Riva, Caracciolo and Malatesta.
$n^{1-p/d}$ converge to a limiting constant that can be represented as a series of integrals, thus extending a classical result of Avram and Bertsimas to the bipartite case and confirming a conjecture of Riva, Caracciolo and Malatesta.
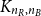
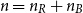
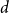
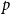
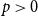

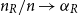
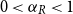
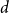
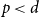
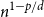
Threshold graphs maximise homomorphism densities
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 29 November 2023, pp. 300-318
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a fixed graph
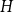 $H$ and a constant
$H$ and a constant 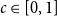 $c \in [0,1]$, we can ask what graphs
$c \in [0,1]$, we can ask what graphs 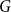 $G$ with edge density
$G$ with edge density  $c$ asymptotically maximise the homomorphism density of
$c$ asymptotically maximise the homomorphism density of 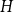 $H$ in
$H$ in 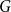 $G$. For all
$G$. For all 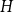 $H$ for which this problem has been solved, the maximum is always asymptotically attained on one of two kinds of graphs: the quasi-star or the quasi-clique. We show that for any
$H$ for which this problem has been solved, the maximum is always asymptotically attained on one of two kinds of graphs: the quasi-star or the quasi-clique. We show that for any 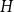 $H$ the maximising
$H$ the maximising 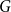 $G$ is asymptotically a threshold graph, while the quasi-clique and the quasi-star are the simplest threshold graphs, having only two parts. This result gives us a unified framework to derive a number of results on graph homomorphism maximisation, some of which were also found quite recently and independently using several different approaches. We show that there exist graphs
$G$ is asymptotically a threshold graph, while the quasi-clique and the quasi-star are the simplest threshold graphs, having only two parts. This result gives us a unified framework to derive a number of results on graph homomorphism maximisation, some of which were also found quite recently and independently using several different approaches. We show that there exist graphs 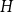 $H$ and densities
$H$ and densities  $c$ such that the optimising graph
$c$ such that the optimising graph 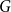 $G$ is neither the quasi-star nor the quasi-clique (Day and Sarkar, SIAM J. Discrete Math. 35(1), 294–306, 2021). We also show that for
$G$ is neither the quasi-star nor the quasi-clique (Day and Sarkar, SIAM J. Discrete Math. 35(1), 294–306, 2021). We also show that for  $c$ large enough all graphs
$c$ large enough all graphs 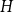 $H$ maximise on the quasi-clique (Gerbner et al., J. Graph Theory 96(1), 34–43, 2021), and for any
$H$ maximise on the quasi-clique (Gerbner et al., J. Graph Theory 96(1), 34–43, 2021), and for any 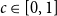 $c \in [0,1]$ the density of
$c \in [0,1]$ the density of 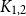 $K_{1,2}$ is always maximised on either the quasi-star or the quasi-clique (Ahlswede and Katona, Acta Math. Hung. 32(1–2), 97–120, 1978). Finally, we extend our results to uniform hypergraphs.
$K_{1,2}$ is always maximised on either the quasi-star or the quasi-clique (Ahlswede and Katona, Acta Math. Hung. 32(1–2), 97–120, 1978). Finally, we extend our results to uniform hypergraphs.
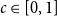
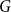

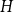
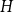
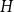
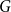
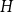

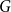

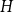
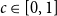
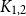
Spread-out limit of the critical points for lattice trees and lattice animals in dimensions
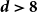 $\boldsymbol{d}\boldsymbol\gt \textbf{8}$
$\boldsymbol{d}\boldsymbol\gt \textbf{8}$
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 20 November 2023, pp. 238-269
-
- Article
- Export citation
-
A spread-out lattice animal is a finite connected set of edges in
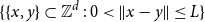 $\{\{x,y\}\subset \mathbb{Z}^d\;:\;0\lt \|x-y\|\le L\}$. A lattice tree is a lattice animal with no loops. The best estimate on the critical point
$\{\{x,y\}\subset \mathbb{Z}^d\;:\;0\lt \|x-y\|\le L\}$. A lattice tree is a lattice animal with no loops. The best estimate on the critical point 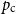 $p_{\textrm{c}}$ so far was achieved by Penrose (J. Stat. Phys. 77, 3–15, 1994) :
$p_{\textrm{c}}$ so far was achieved by Penrose (J. Stat. Phys. 77, 3–15, 1994) : 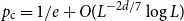 $p_{\textrm{c}}=1/e+O(L^{-2d/7}\log L)$ for both models for all
$p_{\textrm{c}}=1/e+O(L^{-2d/7}\log L)$ for both models for all 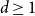 $d\ge 1$. In this paper, we show that
$d\ge 1$. In this paper, we show that 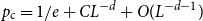 $p_{\textrm{c}}=1/e+CL^{-d}+O(L^{-d-1})$ for all
$p_{\textrm{c}}=1/e+CL^{-d}+O(L^{-d-1})$ for all 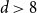 $d\gt 8$, where the model-dependent constant
$d\gt 8$, where the model-dependent constant 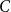 $C$ has the random-walk representationwhere
$C$ has the random-walk representationwhere \begin{align*} C_{\textrm{LT}}=\sum _{n=2}^\infty \frac{n+1}{2e}U^{*n}(o),&& C_{\textrm{LA}}=C_{\textrm{LT}}-\frac 1{2e^2}\sum _{n=3}^\infty U^{*n}(o), \end{align*}
\begin{align*} C_{\textrm{LT}}=\sum _{n=2}^\infty \frac{n+1}{2e}U^{*n}(o),&& C_{\textrm{LA}}=C_{\textrm{LT}}-\frac 1{2e^2}\sum _{n=3}^\infty U^{*n}(o), \end{align*}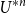 $U^{*n}$ is the
$U^{*n}$ is the  $n$-fold convolution of the uniform distribution on the
$n$-fold convolution of the uniform distribution on the 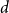 $d$-dimensional ball
$d$-dimensional ball 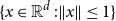 $\{x\in{\mathbb R}^d\;: \|x\|\le 1\}$. The proof is based on a novel use of the lace expansion for the 2-point function and detailed analysis of the 1-point function at a certain value of
$\{x\in{\mathbb R}^d\;: \|x\|\le 1\}$. The proof is based on a novel use of the lace expansion for the 2-point function and detailed analysis of the 1-point function at a certain value of 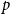 $p$ that is designed to make the analysis extremely simple.
$p$ that is designed to make the analysis extremely simple.
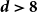
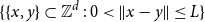
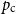
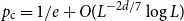
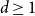
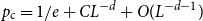
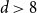
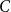

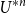

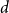
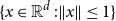
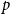
The Bernoulli clock: probabilistic and combinatorial interpretations of the Bernoulli polynomials by circular convolution
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 16 November 2023, pp. 210-237
-
- Article
- Export citation
-
The factorially normalized Bernoulli polynomials
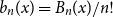 $b_n(x) = B_n(x)/n!$ are known to be characterized by
$b_n(x) = B_n(x)/n!$ are known to be characterized by 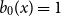 $b_0(x) = 1$ and
$b_0(x) = 1$ and 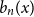 $b_n(x)$ for
$b_n(x)$ for 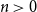 $n \gt 0$ is the anti-derivative of
$n \gt 0$ is the anti-derivative of 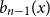 $b_{n-1}(x)$ subject to
$b_{n-1}(x)$ subject to 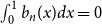 $\int _0^1 b_n(x) dx = 0$. We offer a related characterization:
$\int _0^1 b_n(x) dx = 0$. We offer a related characterization: 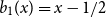 $b_1(x) = x - 1/2$ and
$b_1(x) = x - 1/2$ and 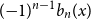 $({-}1)^{n-1} b_n(x)$ for
$({-}1)^{n-1} b_n(x)$ for 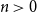 $n \gt 0$ is the
$n \gt 0$ is the  $n$-fold circular convolution of
$n$-fold circular convolution of 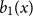 $b_1(x)$ with itself. Equivalently,
$b_1(x)$ with itself. Equivalently, 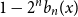 $1 - 2^n b_n(x)$ is the probability density at
$1 - 2^n b_n(x)$ is the probability density at 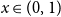 $x \in (0,1)$ of the fractional part of a sum of
$x \in (0,1)$ of the fractional part of a sum of  $n$ independent random variables, each with the beta
$n$ independent random variables, each with the beta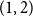 $(1,2)$ probability density
$(1,2)$ probability density 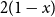 $2(1-x)$ at
$2(1-x)$ at 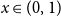 $x \in (0,1)$. This result has a novel combinatorial analog, the Bernoulli clock: mark the hours of a
$x \in (0,1)$. This result has a novel combinatorial analog, the Bernoulli clock: mark the hours of a 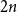 $2 n$ hour clock by a uniformly random permutation of the multiset
$2 n$ hour clock by a uniformly random permutation of the multiset 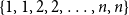 $\{1,1, 2,2, \ldots, n,n\}$, meaning pick two different hours uniformly at random from the
$\{1,1, 2,2, \ldots, n,n\}$, meaning pick two different hours uniformly at random from the 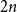 $2 n$ hours and mark them
$2 n$ hours and mark them 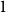 $1$, then pick two different hours uniformly at random from the remaining
$1$, then pick two different hours uniformly at random from the remaining 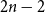 $2 n - 2$ hours and mark them
$2 n - 2$ hours and mark them 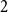 $2$, and so on. Starting from hour
$2$, and so on. Starting from hour 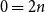 $0 = 2n$, move clockwise to the first hour marked
$0 = 2n$, move clockwise to the first hour marked 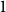 $1$, continue clockwise to the first hour marked
$1$, continue clockwise to the first hour marked 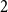 $2$, and so on, continuing clockwise around the Bernoulli clock until the first of the two hours marked
$2$, and so on, continuing clockwise around the Bernoulli clock until the first of the two hours marked  $n$ is encountered, at a random hour
$n$ is encountered, at a random hour 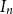 $I_n$ between
$I_n$ between 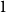 $1$ and
$1$ and 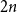 $2n$. We show that for each positive integer
$2n$. We show that for each positive integer  $n$, the event
$n$, the event 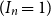 $( I_n = 1)$ has probability
$( I_n = 1)$ has probability 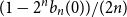 $(1 - 2^n b_n(0))/(2n)$, where
$(1 - 2^n b_n(0))/(2n)$, where 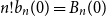 $n! b_n(0) = B_n(0)$ is the
$n! b_n(0) = B_n(0)$ is the  $n$th Bernoulli number. For
$n$th Bernoulli number. For 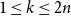 $ 1 \le k \le 2 n$, the difference
$ 1 \le k \le 2 n$, the difference 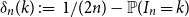 $\delta _n(k)\,:\!=\, 1/(2n) -{\mathbb{P}}( I_n = k)$ is a polynomial function of
$\delta _n(k)\,:\!=\, 1/(2n) -{\mathbb{P}}( I_n = k)$ is a polynomial function of 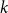 $k$ with the surprising symmetry
$k$ with the surprising symmetry 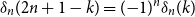 $\delta _n( 2 n + 1 - k) = ({-}1)^n \delta _n(k)$, which is a combinatorial analog of the well-known symmetry of Bernoulli polynomials
$\delta _n( 2 n + 1 - k) = ({-}1)^n \delta _n(k)$, which is a combinatorial analog of the well-known symmetry of Bernoulli polynomials 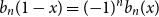 $b_n(1-x) = ({-}1)^n b_n(x)$.
$b_n(1-x) = ({-}1)^n b_n(x)$.
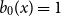
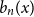
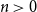
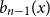
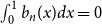
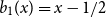
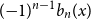
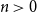

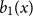
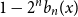
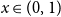

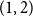
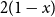
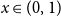
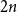
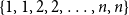
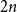
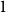
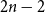
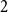
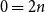
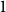
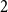

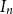
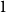
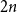

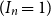
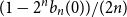
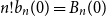

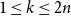
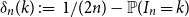
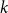
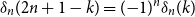
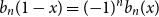
Large cliques or cocliques in hypergraphs with forbidden order-size pairs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 16 November 2023, pp. 286-299
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The well-known Erdős-Hajnal conjecture states that for any graph
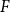 $F$, there exists
$F$, there exists 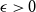 $\epsilon \gt 0$ such that every
$\epsilon \gt 0$ such that every  $n$-vertex graph
$n$-vertex graph 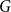 $G$ that contains no induced copy of
$G$ that contains no induced copy of 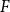 $F$ has a homogeneous set of size at least
$F$ has a homogeneous set of size at least 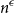 $n^{\epsilon }$. We consider a variant of the Erdős-Hajnal problem for hypergraphs where we forbid a family of hypergraphs described by their orders and sizes. For graphs, we observe that if we forbid induced subgraphs on
$n^{\epsilon }$. We consider a variant of the Erdős-Hajnal problem for hypergraphs where we forbid a family of hypergraphs described by their orders and sizes. For graphs, we observe that if we forbid induced subgraphs on 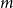 $m$ vertices and
$m$ vertices and 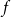 $f$ edges for any positive
$f$ edges for any positive 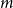 $m$ and
$m$ and 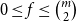 $0\leq f \leq \binom{m}{2}$, then we obtain large homogeneous sets. For triple systems, in the first nontrivial case
$0\leq f \leq \binom{m}{2}$, then we obtain large homogeneous sets. For triple systems, in the first nontrivial case 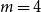 $m=4$, for every
$m=4$, for every 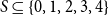 $S \subseteq \{0,1,2,3,4\}$, we give bounds on the minimum size of a homogeneous set in a triple system where the number of edges spanned by every four vertices is not in
$S \subseteq \{0,1,2,3,4\}$, we give bounds on the minimum size of a homogeneous set in a triple system where the number of edges spanned by every four vertices is not in 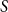 $S$. In most cases the bounds are essentially tight. We also determine, for all
$S$. In most cases the bounds are essentially tight. We also determine, for all 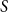 $S$, whether the growth rate is polynomial or polylogarithmic. Some open problems remain.
$S$, whether the growth rate is polynomial or polylogarithmic. Some open problems remain.
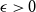

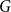
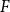
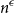
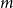
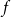
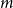
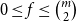
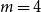
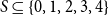
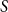
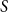
Spanning trees in graphs without large bipartite holes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 14 November 2023, pp. 270-285
-
- Article
-
- You have access
- HTML
- Export citation
-
We show that for any
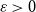 $\varepsilon \gt 0$ and
$\varepsilon \gt 0$ and 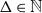 $\Delta \in \mathbb{N}$, there exists
$\Delta \in \mathbb{N}$, there exists 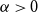 $\alpha \gt 0$ such that for sufficiently large
$\alpha \gt 0$ such that for sufficiently large  $n$, every
$n$, every  $n$-vertex graph
$n$-vertex graph 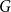 $G$ satisfying that
$G$ satisfying that 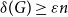 $\delta (G)\geq \varepsilon n$ and
$\delta (G)\geq \varepsilon n$ and 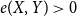 $e(X, Y)\gt 0$ for every pair of disjoint vertex sets
$e(X, Y)\gt 0$ for every pair of disjoint vertex sets 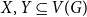 $X, Y\subseteq V(G)$ of size
$X, Y\subseteq V(G)$ of size 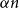 $\alpha n$ contains all spanning trees with maximum degree at most
$\alpha n$ contains all spanning trees with maximum degree at most 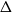 $\Delta$. This strengthens a result of Böttcher, Han, Kohayakawa, Montgomery, Parczyk, and Person.
$\Delta$. This strengthens a result of Böttcher, Han, Kohayakawa, Montgomery, Parczyk, and Person.
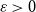
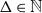
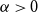


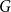
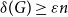
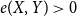
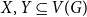
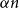
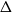
Approximate discrete entropy monotonicity for log-concave sums
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 13 November 2023, pp. 196-209
-
- Article
- Export citation
-
It is proven that a conjecture of Tao (2010) holds true for log-concave random variables on the integers: For every
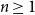 $n \geq 1$, if
$n \geq 1$, if 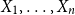 $X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas
$X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas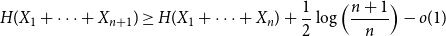 \begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}
\begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}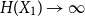 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 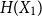 $H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if
$H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if 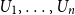 $U_1,\ldots,U_n$ are independent continuous uniforms on
$U_1,\ldots,U_n$ are independent continuous uniforms on 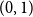 $(0,1)$, thenas
$(0,1)$, thenas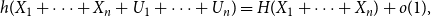 \begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}
\begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}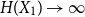 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 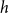 $h$ stands for the differential entropy. Explicit bounds for the
$h$ stands for the differential entropy. Explicit bounds for the 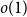 $o(1)$-terms are provided.
$o(1)$-terms are provided.
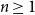
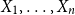
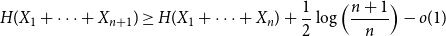
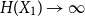
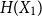
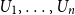
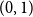
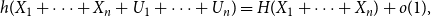
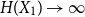
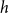
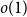
A special case of Vu’s conjecture: colouring nearly disjoint graphs of bounded maximum degree
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 10 November 2023, pp. 179-195
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A collection of graphs is nearly disjoint if every pair of them intersects in at most one vertex. We prove that if
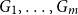 $G_1, \dots, G_m$ are nearly disjoint graphs of maximum degree at most
$G_1, \dots, G_m$ are nearly disjoint graphs of maximum degree at most 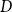 $D$, then the following holds. For every fixed
$D$, then the following holds. For every fixed 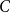 $C$, if each vertex
$C$, if each vertex 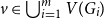 $v \in \bigcup _{i=1}^m V(G_i)$ is contained in at most
$v \in \bigcup _{i=1}^m V(G_i)$ is contained in at most 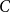 $C$ of the graphs
$C$ of the graphs 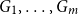 $G_1, \dots, G_m$, then the (list) chromatic number of
$G_1, \dots, G_m$, then the (list) chromatic number of 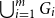 $\bigcup _{i=1}^m G_i$ is at most
$\bigcup _{i=1}^m G_i$ is at most 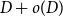 $D + o(D)$. This result confirms a special case of a conjecture of Vu and generalizes Kahn’s bound on the list chromatic index of linear uniform hypergraphs of bounded maximum degree. In fact, this result holds for the correspondence (or DP) chromatic number and thus implies a recent result of Molloy and Postle, and we derive this result from a more general list colouring result in the setting of ‘colour degrees’ that also implies a result of Reed and Sudakov.
$D + o(D)$. This result confirms a special case of a conjecture of Vu and generalizes Kahn’s bound on the list chromatic index of linear uniform hypergraphs of bounded maximum degree. In fact, this result holds for the correspondence (or DP) chromatic number and thus implies a recent result of Molloy and Postle, and we derive this result from a more general list colouring result in the setting of ‘colour degrees’ that also implies a result of Reed and Sudakov.
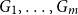
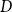
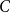
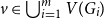
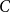
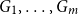
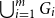
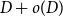
On oriented cycles in randomly perturbed digraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 157-178
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In 2003, Bohman, Frieze, and Martin initiated the study of randomly perturbed graphs and digraphs. For digraphs, they showed that for every
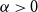 $\alpha \gt 0$, there exists a constant
$\alpha \gt 0$, there exists a constant 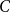 $C$ such that for every
$C$ such that for every  $n$-vertex digraph of minimum semi-degree at least
$n$-vertex digraph of minimum semi-degree at least 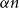 $\alpha n$, if one adds
$\alpha n$, if one adds 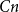 $Cn$ random edges then asymptotically almost surely the resulting digraph contains a consistently oriented Hamilton cycle. We generalize their result, showing that the hypothesis of this theorem actually asymptotically almost surely ensures the existence of every orientation of a cycle of every possible length, simultaneously. Moreover, we prove that we can relax the minimum semi-degree condition to a minimum total degree condition when considering orientations of a cycle that do not contain a large number of vertices of indegree
$Cn$ random edges then asymptotically almost surely the resulting digraph contains a consistently oriented Hamilton cycle. We generalize their result, showing that the hypothesis of this theorem actually asymptotically almost surely ensures the existence of every orientation of a cycle of every possible length, simultaneously. Moreover, we prove that we can relax the minimum semi-degree condition to a minimum total degree condition when considering orientations of a cycle that do not contain a large number of vertices of indegree 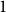 $1$. Our proofs make use of a variant of an absorbing method of Montgomery.
$1$. Our proofs make use of a variant of an absorbing method of Montgomery.
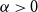

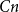
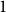
Mastermind with a linear number of queries
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 143-156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Since the 1960s Mastermind has been studied for the combinatorial and information-theoretical interest the game has to offer. Many results have been discovered starting with Erdős and Rényi determining the optimal number of queries needed for two colours. For
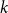 $k$ colours and
$k$ colours and  $n$ positions, Chvátal found asymptotically optimal bounds when
$n$ positions, Chvátal found asymptotically optimal bounds when 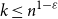 $k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for
$k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for 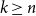 $k\geq n$ colours, the central open question is to resolve the gap between
$k\geq n$ colours, the central open question is to resolve the gap between 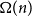 $\Omega (n)$ and
$\Omega (n)$ and 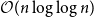 $\mathcal{O}(n\log \log n)$ for
$\mathcal{O}(n\log \log n)$ for 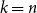 $k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving
$k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving 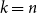 $k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters
$k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters 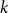 $k$ and
$k$ and  $n$.
$n$.