Refine search
Actions for selected content:
9085 results in Discrete Mathematics, Information Theory and Coding
4 - Hilbert modules
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp 79-102
-
- Chapter
- Export citation
Index
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp 289-290
-
- Chapter
- Export citation
Preface
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp vii-viii
-
- Chapter
- Export citation
Notation
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp ix-x
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp i-iv
-
- Chapter
- Export citation
Contents
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp v-vi
-
- Chapter
- Export citation
2 - Preliminaries
-
- Book:
- Quantum Stochastic Processes and Noncommutative Geometry
- Published online:
- 19 January 2010
- Print publication:
- 25 January 2007, pp 7-32
-
- Chapter
- Export citation
Topics in Algebraic Graph Theory, by Lowell W. Beineke and Robin J. Wilson (Academic Consultant: Peter J. Cameron), Encyclopedia of Mathematics and its Applications 102, CUP 2005, 257pp., £ 50.00/$95.00
-
- Journal:
- Combinatorics, Probability and Computing / Volume 16 / Issue 1 / January 2007
- Published online by Cambridge University Press:
- 12 December 2006, pp. 171-172
-
- Article
- Export citation
On Second-Order Characteristics of Germ-Grain Models with Convex Grains
- Part of
-
- Journal:
- Mathematika / Volume 53 / Issue 2 / December 2006
- Published online by Cambridge University Press:
- 21 December 2009, pp. 255-285
- Print publication:
- December 2006
-
- Article
- Export citation
A Large Deviations Approach to the Geometry of Random Polytopes
- Part of
-
- Journal:
- Mathematika / Volume 53 / Issue 2 / December 2006
- Published online by Cambridge University Press:
- 21 December 2009, pp. 173-210
- Print publication:
- December 2006
-
- Article
- Export citation
-
The aim of this article is to present a general “large deviations approach” to the geometry of polytopes spanned by random points with independent coordinates. The origin of our work is in the study of the structure of ±1-polytopes, the convex hulls of subsets of the combinatorial cube
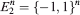 . Understanding the complexity of this class of polytopes is important for the “polyhedral combinatorics” approach to combinatorial optimization, and was put forward by Ziegler in [20]. Many natural questions regarding the behaviour of ±1-polytopes in high dimensions are open, since, for many important geometric parameters, low-dimensional intuition does not help to identify the extremal ±1-polytopes. The study of random ±1-polytopes sheds light to some of these questions, the main reason being that random behaviour is often the extremal one.
. Understanding the complexity of this class of polytopes is important for the “polyhedral combinatorics” approach to combinatorial optimization, and was put forward by Ziegler in [20]. Many natural questions regarding the behaviour of ±1-polytopes in high dimensions are open, since, for many important geometric parameters, low-dimensional intuition does not help to identify the extremal ±1-polytopes. The study of random ±1-polytopes sheds light to some of these questions, the main reason being that random behaviour is often the extremal one.
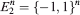 . Understanding the complexity of this class of polytopes is important for the “polyhedral combinatorics” approach to combinatorial optimization, and was put forward by Ziegler in [
. Understanding the complexity of this class of polytopes is important for the “polyhedral combinatorics” approach to combinatorial optimization, and was put forward by Ziegler in [The Exact Distribution of the Number of Vertices of a Random Convex Chain
- Part of
-
- Journal:
- Mathematika / Volume 53 / Issue 2 / December 2006
- Published online by Cambridge University Press:
- 21 December 2009, pp. 247-254
- Print publication:
- December 2006
-
- Article
- Export citation
-
Assume that n points P1,…,Pn are distributed independently and uniformly in the triangle with vertices (0, 1), (0, 0), and (1, 0). Consider the convex hull of (0, 1), P1,…,Pn, and (1, 0). The vertices of the convex hull form a convex chain. Let
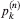 be the probability that the convex chain consists – apart from the points (0, 1) and (1, 0) – of exactly k of the points P1,…,Pn. Bárány, Rote, Steiger, and Zhang [3] proved that
be the probability that the convex chain consists – apart from the points (0, 1) and (1, 0) – of exactly k of the points P1,…,Pn. Bárány, Rote, Steiger, and Zhang [3] proved that 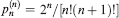 . The values of are determined for k = 1,…,n − 1, and thus the distribution of the number of vertices of a random convex chain is obtained. Knowing this distribution provides the key to the answer of some long-standing questions in geometrical probability.
. The values of are determined for k = 1,…,n − 1, and thus the distribution of the number of vertices of a random convex chain is obtained. Knowing this distribution provides the key to the answer of some long-standing questions in geometrical probability.
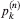 be the probability that the convex chain consists – apart from the points (0, 1) and (1, 0) – of exactly
be the probability that the convex chain consists – apart from the points (0, 1) and (1, 0) – of exactly 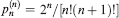 . The values of
. The values of Connection Between Strong and Norming Markushevich Bases in Non-Separable Banach Spaces
- Part of
-
- Journal:
- Mathematika / Volume 53 / Issue 2 / December 2006
- Published online by Cambridge University Press:
- 21 December 2009, pp. 321-328
- Print publication:
- December 2006
-
- Article
- Export citation
The Lower Dimensional Busemann-Petty Problem with Weights
- Part of
-
- Journal:
- Mathematika / Volume 53 / Issue 2 / December 2006
- Published online by Cambridge University Press:
- 21 December 2009, pp. 235-245
- Print publication:
- December 2006
-
- Article
- Export citation
Volume Inequalities and Additive Maps of Convex Bodies
- Part of
-
- Journal:
- Mathematika / Volume 53 / Issue 2 / December 2006
- Published online by Cambridge University Press:
- 21 December 2009, pp. 211-234
- Print publication:
- December 2006
-
- Article
- Export citation
6 - Random Walks
-
- Book:
- Random Graph Dynamics
- Published online:
- 18 August 2009
- Print publication:
- 23 October 2006, pp 153-186
-
- Chapter
- Export citation
5 - Small Worlds
-
- Book:
- Random Graph Dynamics
- Published online:
- 18 August 2009
- Print publication:
- 23 October 2006, pp 132-152
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Random Graph Dynamics
- Published online:
- 18 August 2009
- Print publication:
- 23 October 2006, pp i-iv
-
- Chapter
- Export citation
7 - CHKNS Model
-
- Book:
- Random Graph Dynamics
- Published online:
- 18 August 2009
- Print publication:
- 23 October 2006, pp 187-202
-
- Chapter
- Export citation
Graphs on Surfaces and Their Applications, by Sergei K. Lando and Alexander K. Zvonkin, Encyclopaedia of Mathematical Sciences 141, Springer-Verlag, 2004, 455pp., £73.00/$109.00/94.95 Euros
-
- Journal:
- Combinatorics, Probability and Computing / Volume 15 / Issue 6 / November 2006
- Published online by Cambridge University Press:
- 23 October 2006, pp. 939-941
-
- Article
- Export citation
Contents
-
- Book:
- Random Graph Dynamics
- Published online:
- 18 August 2009
- Print publication:
- 23 October 2006, pp v-vi
-
- Chapter
- Export citation
