Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
Total scalar curvature and rigidity of minimal hypersurfaces in Euclidean space
- Part of
-
- Journal:
- Mathematika / Volume 48 / Issue 1-2 / December 2001
- Published online by Cambridge University Press:
- 26 February 2010, pp. 247-251
- Print publication:
- December 2001
-
- Article
- Export citation
-
Let Mn, n ≥ 3, be a complete oriented minimal hypersurface in Euclidean space Rn+1. It is shown that, if the total scalar curvature on M is less than the n/2 power of 1/2Cs, where Cs is the Sobolev constant for M, and the square norm of the second fundamental form
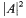 is a L2 function, then M is a hyperplane.
is a L2 function, then M is a hyperplane.
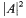 is a
is a Geometry of the gauss map and lattice points in convex domains
- Part of
-
- Journal:
- Mathematika / Volume 48 / Issue 1-2 / December 2001
- Published online by Cambridge University Press:
- 26 February 2010, pp. 107-117
- Print publication:
- December 2001
-
- Article
- Export citation
On sigma-phi numbers
-
- Journal:
- Mathematika / Volume 48 / Issue 1-2 / December 2001
- Published online by Cambridge University Press:
- 26 February 2010, pp. 169-189
- Print publication:
- December 2001
-
- Article
- Export citation
-
Let
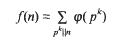
where φ denotes Euler's function. In this memoir we study the set w of sigmaphi numbers, that is, those composite natural numbers n which satisfy
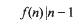
The smallest such number is 65, and they appear to be moderately frequent. There are 290 sigma-phi numbers not exceeding 105 and 1,231 not exceeding 106. By comparison, we observe that the number of primes in these ranges is 9,592 and 78,498, respectively. Since the primes also satisfy the relationship (1.2) a sigma-phi number can be thought of as a kind of pseudo-prime. The motivation for studying sigma-phi numbers is that they should have similar properties to Carmichael numbers but be easier to study. A Carmichael number is a number n such that the least common multiple of the φ(pk) with pk||n divides n-1, i.e., by Korseldt's criterion, a number for which p-1||n-1 whenever p|n. The number of Carmichael numbers not exceeding 105 and 106 is 16 and 43, respectively. It seems that the counting functions for Carmichael and sigma-phi numbers have somewhat similar growth rates. The counts above are skewed by the fact that there are many sigma-phi numbers with exactly two prime factors but there are no Carmichael numbers of this kind.
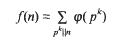
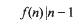
On simultaneous diagonal inequalities, II
- Part of
-
- Journal:
- Mathematika / Volume 48 / Issue 1-2 / December 2001
- Published online by Cambridge University Press:
- 26 February 2010, pp. 191-202
- Print publication:
- December 2001
-
- Article
- Export citation
-
In this paper we continue the investigation begun in [11]. Let λ1…., λs and μ1, …, μs be real numbers, and define the forms
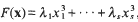
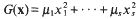
Further, let τ be a positive real number. Our goal is to determine conditions under which the system of inequalities
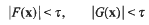
has a non-trivial integral solution. As has frequently been the case in work on systems of diophantine inequalities (see, for example, Brüdern and Cook [6] and Cook [7]), we were forced in [11] to impose a condition requiring certain coefficient ratios to be algebraic. A recent paper of Bentkus and Gotze [4] introduced a method for avoiding such a restriction in the study of positivede finite quadratic forms, and these ideas are in fact flexible enough to be applied to other problems. In particular, Freeman [10] was able to adapt the method to obtain an asymptotic lower bound for the number of solutions of a single diophantine inequality, thus finally providing the expected strengthening of a classical theorem of Davenport and Heilbronn [9]. The purpose of the present note is to apply these new ideas to the system of inequalities (1.1).
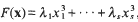
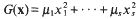
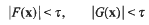
Continuous and discrete boundary value problems on the infinite interval: existence theory
- Part of
-
- Journal:
- Mathematika / Volume 48 / Issue 1-2 / December 2001
- Published online by Cambridge University Press:
- 26 February 2010, pp. 273-292
- Print publication:
- December 2001
-
- Article
- Export citation
Difference polynomials and their generalizations
- Part of
-
- Journal:
- Mathematika / Volume 48 / Issue 1-2 / December 2001
- Published online by Cambridge University Press:
- 26 February 2010, pp. 293-299
- Print publication:
- December 2001
-
- Article
- Export citation
27 - Difference sets and automorphisms
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 369-382
-
- Chapter
- Export citation
32 - Graph connectivity
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 451-458
-
- Chapter
- Export citation
35 - Embeddings of graphs on surfaces
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 491-506
-
- Chapter
- Export citation
13 - Elementary counting; Stirling numbers
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 119-128
-
- Chapter
- Export citation
36 - Electrical networks and squared squares
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 507-521
-
- Chapter
- Export citation
26 - Combinatorial designs and projective geometries
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 351-368
-
- Chapter
- Export citation
Preface to the second edition
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp xiii-xiv
-
- Chapter
- Export citation
3 - Colorings of graphs and Ramsey's theorem
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 24-36
-
- Chapter
- Export citation
Contents
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp v-x
-
- Chapter
- Export citation
9 - Two (0, 1, ⋆) problems: addressing for graphs and a hash-coding scheme
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 77-88
-
- Chapter
- Export citation
19 - Designs
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 215-243
-
- Chapter
- Export citation
29 - Codes and symmetric designs
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 396-404
-
- Chapter
- Export citation
25 - Lattices and Möbius inversion
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 333-350
-
- Chapter
- Export citation
8 - De Bruijn sequences
-
- Book:
- A Course in Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 22 November 2001, pp 71-76
-
- Chapter
- Export citation
