Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
5 - Link polynomials and the Tait conjectures
-
- Book:
- Complexity: Knots, Colourings and Countings
- Published online:
- 05 August 2013
- Print publication:
- 12 August 1993, pp 71-94
-
- Chapter
- Export citation
8 - Approximation and randomisation
-
- Book:
- Complexity: Knots, Colourings and Countings
- Published online:
- 05 August 2013
- Print publication:
- 12 August 1993, pp 124-142
-
- Chapter
- Export citation
3 - Colourings, flows and polynomials
-
- Book:
- Complexity: Knots, Colourings and Countings
- Published online:
- 05 August 2013
- Print publication:
- 12 August 1993, pp 42-53
-
- Chapter
- Export citation
Restricted colorings of graphs
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 1-34
-
- Chapter
- Export citation
On circuit covers, circuit decompositions and Euler tours of graphs
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 191-210
-
- Chapter
- Export citation
Graphs with projective subconstituents which contain short cycles
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 173-190
-
- Chapter
- Export citation
Contents
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp v-vi
-
- Chapter
- Export citation
Combinatorial designs and cryptography
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 257-287
-
- Chapter
- Export citation
Applications of submodular functions
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 85-136
-
- Chapter
- Export citation
Weighted quasigroups
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 137-172
-
- Chapter
- Export citation
Polynomials in finite geometries and combinatorics
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 35-52
-
- Chapter
- Export citation
Slicing the hypercube
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 211-256
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp vii-viii
-
- Chapter
- Export citation
Models of random partial orders
-
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp 53-84
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Surveys in Combinatorics, 1993
- Published online:
- 16 March 2010
- Print publication:
- 29 July 1993, pp i-iv
-
- Chapter
- Export citation
Irregularities of point distribution relative to convex polygons II
- Part of
-
- Journal:
- Mathematika / Volume 40 / Issue 1 / June 1993
- Published online by Cambridge University Press:
- 26 February 2010, pp. 127-136
- Print publication:
- June 1993
-
- Article
- Export citation
-
Suppose that
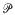 is a distribution of N points in the unit square U = [0, 1]2. For every measurable set B in U, let Z[; B] denote the number of ponts of in B, and write
is a distribution of N points in the unit square U = [0, 1]2. For every measurable set B in U, let Z[; B] denote the number of ponts of in B, and write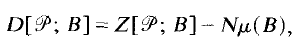
where µ denotes the usual measure in ℝ2
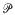 is a distribution of
is a distribution of 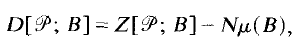
On successive minima and intrinsic volumes
- Part of
-
- Journal:
- Mathematika / Volume 40 / Issue 1 / June 1993
- Published online by Cambridge University Press:
- 26 February 2010, pp. 144-147
- Print publication:
- June 1993
-
- Article
- Export citation
MTK volume 40 issue 2 Cover and Front matter
-
- Journal:
- Mathematika / Volume 40 / Issue 1 / June 1993
- Published online by Cambridge University Press:
- 26 February 2010, pp. f1-f4
- Print publication:
- June 1993
-
- Article
-
- You have access
- Export citation
A bound, and a conjecture, on the maximum lattice-packing density of a superball
- Part of
-
- Journal:
- Mathematika / Volume 40 / Issue 1 / June 1993
- Published online by Cambridge University Press:
- 26 February 2010, pp. 137-143
- Print publication:
- June 1993
-
- Article
- Export citation
-
We obtain explicit lower bounds on the lattice packing densities δL of superballs G of quite a general nature, and we conjecture that as the dimension n approaches infinity, the bounds are asymptotically exact. If the conjecture were true, it would follow that the maximum lattice-packing density of the Iσ-ball
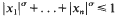 is 2−n(1+σ(1)) for each σ in the interval 1 ≤ σ ≤ 2.
is 2−n(1+σ(1)) for each σ in the interval 1 ≤ σ ≤ 2.
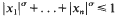 is 2
is 2Resonant generation of finite-amplitude waves by the uniform flow of a uniformly rotating fluid past an obstacle
-
- Journal:
- Mathematika / Volume 40 / Issue 1 / June 1993
- Published online by Cambridge University Press:
- 26 February 2010, pp. 30-50
- Print publication:
- June 1993
-
- Article
- Export citation
