Refine listing
Actions for selected content:
189 results in 93Exx
Some diffusion models for the mabinogion sheep problem of williams
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 28 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 01 July 2016, pp. 763-783
- Print publication:
- September 1996
-
- Article
- Export citation
General necessary conditions for partially observed optimal stochastic controls
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 32 / Issue 4 / December 1995
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1118-1137
- Print publication:
- December 1995
-
- Article
- Export citation
Finite-dimensional models for hidden Markov chains
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 27 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 01 July 2016, pp. 146-160
- Print publication:
- March 1995
-
- Article
- Export citation
Detecting optimal and non-optimal actions in average-cost Markov decision processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 31 / Issue 4 / December 1994
- Published online by Cambridge University Press:
- 14 July 2016, pp. 979-990
- Print publication:
- December 1994
-
- Article
- Export citation
A general recursive discrete-time filter
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 30 / Issue 3 / September 1993
- Published online by Cambridge University Press:
- 14 July 2016, pp. 575-588
- Print publication:
- September 1993
-
- Article
- Export citation
Discretizations for the average impulse control of piecewise deterministic processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 30 / Issue 2 / June 1993
- Published online by Cambridge University Press:
- 14 July 2016, pp. 405-420
- Print publication:
- June 1993
-
- Article
- Export citation
Optimality of index policies for stochastic scheduling with switching penalties
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 29 / Issue 4 / December 1992
- Published online by Cambridge University Press:
- 14 July 2016, pp. 957-966
- Print publication:
- December 1992
-
- Article
- Export citation
A bang-bang strategy for a finite fuel stochastic control problem
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 24 / Issue 3 / September 1992
- Published online by Cambridge University Press:
- 01 July 2016, pp. 589-603
- Print publication:
- September 1992
-
- Article
- Export citation
-
The problem treated is that of controlling a process
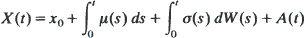 with values in [0, a]. The non-anticipative controls (µ(t), σ(t)) are selected from a set C(x) whenever X(t–) = x and the non-decreasing process A(t) is chosen by the controller subject to the condition
with values in [0, a]. The non-anticipative controls (µ(t), σ(t)) are selected from a set C(x) whenever X(t–) = x and the non-decreasing process A(t) is chosen by the controller subject to the condition 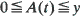 where y is a constant representing the initial amount of fuel. The object is to maximize the probability that X(t) reaches a. The optimal process is determined when the function
where y is a constant representing the initial amount of fuel. The object is to maximize the probability that X(t) reaches a. The optimal process is determined when the function 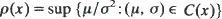 has a unique minimum on [0, a] and satisfies certain regularity conditions. The optimal process is a combination of ‘timid play' in which fuel is used gradually in the form of local time at 0, and ‘bold play' in which all the fuel is used at once.
has a unique minimum on [0, a] and satisfies certain regularity conditions. The optimal process is a combination of ‘timid play' in which fuel is used gradually in the form of local time at 0, and ‘bold play' in which all the fuel is used at once.
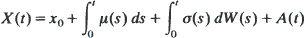
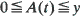 where
where 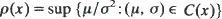 has a unique minimum on [0,
has a unique minimum on [0, Asymptotic properties of the least-squares method for estimating transfer functions and disturbance spectra
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 24 / Issue 2 / June 1992
- Published online by Cambridge University Press:
- 01 July 2016, pp. 412-440
- Print publication:
- June 1992
-
- Article
- Export citation
