Refine search
Actions for selected content:
28356 results in Astrophysics
Improvement to the Epoch of Reionisation power spectrum using simulations with the Central Redundant Array Mega-tile (CRAM)
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 September 2024, e060
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Detection of the 21 cm signal from the Epoch of Reionisation (EoR) (
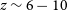 $z \sim 6 - 10$) amidst the dominant foregrounds, which are 3–4 orders of magnitude greater than the weak cosmological signal, is a challenging task for the existing 21 cm experiments. The detection is further challenged by the large Field of View (FoV) of the instrument used for observation, as it becomes necessary to excise foregrounds present within the FoV to make a successful detection. In response to the challenges faced, in our previous work, we developed and installed a new instrument – the Central Redundant Array Mega-tile (CRAM) – and integrated it within the MWA Phase II configuration. It is a larger antenna tile configuration (
$z \sim 6 - 10$) amidst the dominant foregrounds, which are 3–4 orders of magnitude greater than the weak cosmological signal, is a challenging task for the existing 21 cm experiments. The detection is further challenged by the large Field of View (FoV) of the instrument used for observation, as it becomes necessary to excise foregrounds present within the FoV to make a successful detection. In response to the challenges faced, in our previous work, we developed and installed a new instrument – the Central Redundant Array Mega-tile (CRAM) – and integrated it within the MWA Phase II configuration. It is a larger antenna tile configuration ( $8\times 8$ dipoles) with a smaller FoV at every frequency under consideration and has multiple sidelobes of reduced response when compared with the existing Murchison Widefield Array (MWA) tiles. In this paper, we aim to demonstrate through power spectrum simulations that using the larger tile, such as the CRAM, can reduce the impact of bright radio foregrounds near the field edge. For the pedagogical approach aimed with this work, we developed a power spectrum pipeline to estimate the cylindrically averaged power spectrum. The power spectrum is estimated for MWA-MWA baselines and CRAM-MWA baselines using analytical beams, simulated diffuse sky maps and a semi-numerical 21 cm signal. Employing a drift scanning strategy, we estimate 1D and 2D power spectra for a series of two-minute observations spanning 24 hrs using the diffuse sky maps. Our simulations predict a power reduction at the edge of the EoR wedge. The reduction in foreground power is confirmed with the Fisher analysis of the expected signal-to-noise ratio (SNR) improvement, which reports a higher SNR with the power estimations from CRAM baselines when compared with the regular MWA baselines. The reduced power obtained with the CRAM baselines is consistent with the fact that the larger tile configuration has reduced the impact of foregrounds from near the horizon.
$8\times 8$ dipoles) with a smaller FoV at every frequency under consideration and has multiple sidelobes of reduced response when compared with the existing Murchison Widefield Array (MWA) tiles. In this paper, we aim to demonstrate through power spectrum simulations that using the larger tile, such as the CRAM, can reduce the impact of bright radio foregrounds near the field edge. For the pedagogical approach aimed with this work, we developed a power spectrum pipeline to estimate the cylindrically averaged power spectrum. The power spectrum is estimated for MWA-MWA baselines and CRAM-MWA baselines using analytical beams, simulated diffuse sky maps and a semi-numerical 21 cm signal. Employing a drift scanning strategy, we estimate 1D and 2D power spectra for a series of two-minute observations spanning 24 hrs using the diffuse sky maps. Our simulations predict a power reduction at the edge of the EoR wedge. The reduction in foreground power is confirmed with the Fisher analysis of the expected signal-to-noise ratio (SNR) improvement, which reports a higher SNR with the power estimations from CRAM baselines when compared with the regular MWA baselines. The reduced power obtained with the CRAM baselines is consistent with the fact that the larger tile configuration has reduced the impact of foregrounds from near the horizon.

Constraining the physical parameters of blazars using the seed factor approach
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 September 2024, e062
-
- Article
- Export citation
-
The discovery that blazars dominate the extra-galactic
 $\gamma$-ray sky is a triumph in the Fermi era. However, the exact location of
$\gamma$-ray sky is a triumph in the Fermi era. However, the exact location of 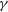 $\gamma$-ray emission region still remains in debate. Low-synchrotron-peaked blazars (LSPs) are estimated to produce high-energy radiation through the external Compton process, thus their emission regions are closely related to the external photon fields. We employed the seed factor approach proposed by Georganopoulos et al. It directly matches the observed seed factor of each LSP with the characteristic seed factors of external photon fields to locate the
$\gamma$-ray emission region still remains in debate. Low-synchrotron-peaked blazars (LSPs) are estimated to produce high-energy radiation through the external Compton process, thus their emission regions are closely related to the external photon fields. We employed the seed factor approach proposed by Georganopoulos et al. It directly matches the observed seed factor of each LSP with the characteristic seed factors of external photon fields to locate the 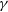 $\gamma$-ray emission region. A sample of 1 138 LSPs with peak frequencies and peak luminosities was adopted to plot a histogram distribution of observed seed factors. We also collected some spectral energy distributions (SEDs) of historical flare states to investigate the variation of
$\gamma$-ray emission region. A sample of 1 138 LSPs with peak frequencies and peak luminosities was adopted to plot a histogram distribution of observed seed factors. We also collected some spectral energy distributions (SEDs) of historical flare states to investigate the variation of  $\gamma$-ray emission region. Those SEDs were fitted by both quadratic and cubic functions using the Markov-chain Monte Carlo method. Furthermore, we derived some physical parameters of blazars and compared them with the constraint of internal
$\gamma$-ray emission region. Those SEDs were fitted by both quadratic and cubic functions using the Markov-chain Monte Carlo method. Furthermore, we derived some physical parameters of blazars and compared them with the constraint of internal  $\gamma\gamma$-absorption. We find that dusty torus dominates the soft photon fields of LSPs and most
$\gamma\gamma$-absorption. We find that dusty torus dominates the soft photon fields of LSPs and most  $\gamma$-ray emission regions of LSPs are located at 1–10 pc. The soft photon fields could also transition from dusty torus to broad line region and cosmic microwave background in different flare states. Our results suggest that the cubic function is better than the quadratic function to fit the SEDs.
$\gamma$-ray emission regions of LSPs are located at 1–10 pc. The soft photon fields could also transition from dusty torus to broad line region and cosmic microwave background in different flare states. Our results suggest that the cubic function is better than the quadratic function to fit the SEDs.

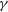



Weather conditions at Timau National Observatory from ERA5
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 September 2024, e058
-
- Article
- Export citation
-
A new observatory site should be investigated for its local climate conditions to see its potential and limitations. In this respect, we examine several meteorological parameters at the site of Timau National Observatory, Indonesia using the ERA5 dataset from 2002 to 2021. Based on this dataset, we conclude that the surface temperature at Timau is around
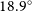 $18.9^{\circ}$C with relatively small temperature variation (
$18.9^{\circ}$C with relatively small temperature variation ( $\sim$
$\sim$ $1.5^{\circ}$C) over the day. This temperature stability is expected to give advantages to the observatory. In terms of humidity and water vapour, Timau is poor for infrared observations as the median precipitable water vapour exceeds 18 mm, even during the dry season. However, near-infrared observations are feasible. Even though our cloud cover analysis confirms the span of the observing season in the region, we find a significant discrepancy between the clear sky fraction derived from the ERA5 dataset and the one estimated using satellite imagery. Aside from the indicated bias, our results provide insights and directions for the operation and future development of the observatory.
$1.5^{\circ}$C) over the day. This temperature stability is expected to give advantages to the observatory. In terms of humidity and water vapour, Timau is poor for infrared observations as the median precipitable water vapour exceeds 18 mm, even during the dry season. However, near-infrared observations are feasible. Even though our cloud cover analysis confirms the span of the observing season in the region, we find a significant discrepancy between the clear sky fraction derived from the ERA5 dataset and the one estimated using satellite imagery. Aside from the indicated bias, our results provide insights and directions for the operation and future development of the observatory.


Converting the ANU 2.3 telescope to fully automated operation
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 September 2024, e057
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The operation of the ANU 2.3 m telescope transitioned from classically scheduled remote observing to fully autonomous queue scheduled observing in March 2023. The instrument currently supported is WiFeS, a visible-light low-resolution image-slicing integral field spectrograph with a
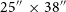 $25^{\prime\prime}\,\times38^{\prime\prime}$ field of view (offering precision spectrophotometry free from aperture effects). It is highly suitable for rapid spectroscopic follow-up of astronomical transient events and regular cadence observations. The new control system implements flexible queue scheduling and supports rapid response override for target-of-opportunity observations. The ANU 2.3 m is the largest optical telescope to have been retro-fitted for autonomous operation to date, and it remains a national facility servicing a broad range of science cases. We present an overview of the automated control system and report on the first six months of continuous operation.
$25^{\prime\prime}\,\times38^{\prime\prime}$ field of view (offering precision spectrophotometry free from aperture effects). It is highly suitable for rapid spectroscopic follow-up of astronomical transient events and regular cadence observations. The new control system implements flexible queue scheduling and supports rapid response override for target-of-opportunity observations. The ANU 2.3 m is the largest optical telescope to have been retro-fitted for autonomous operation to date, and it remains a national facility servicing a broad range of science cases. We present an overview of the automated control system and report on the first six months of continuous operation.
The dusty aftermath of a rapid nova: V5579 Sgr
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 20 September 2024, e051
-
- Article
- Export citation
-
V5579 Sgr was a fast nova discovered in 2008 April 18.784 UT. We present the optical spectroscopic observations of the nova observed from the Castanet Tolosan, SMARTS, and CTIO observatories spanning over 2008 April 23 to 2015 May 11. The spectra are dominated by hydrogen Balmer, Fe II, and O I lines with P-Cygni profiles in the early phase, typical of an Fe II class nova. The spectra show He I and He II lines along with forbidden lines from N, Ar, S, and O in the nebular phase. The nova showed a pronounced dust formation episode that began about 20 days after the outburst. The dust temperature and mass were estimated using the WISE data from spectral energy distribution (SED) fits. The PAH-like features are also seen in the nova ejecta in the mid-infrared Gemini spectra taken 522 d after the discovery. Analysis of the light curve indicates values of
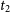 $t_2$ and
$t_2$ and  $t_3$ about 9 and 13 days, respectively, placing the nova in the category of fast nova. The best-fit cloudy model of the early decline phase JHK spectra obtained on 2008 May 3 and the nebular optical spectrum obtained on 2011 June 2 shows a hot white dwarf source with
$t_3$ about 9 and 13 days, respectively, placing the nova in the category of fast nova. The best-fit cloudy model of the early decline phase JHK spectra obtained on 2008 May 3 and the nebular optical spectrum obtained on 2011 June 2 shows a hot white dwarf source with  $T_{BB}$
$T_{BB}$ 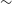 $\sim$ 2.6
$\sim$ 2.6  $\times$ 10
$\times$ 10 $^5$ K having a luminosity of 9.8
$^5$ K having a luminosity of 9.8  $\times$ 10
$\times$ 10 $^{36}$ ergs s
$^{36}$ ergs s $^{-1}$. Our abundance analysis shows that the ejecta is significantly enhanced relative to solar, O/H = 32.2, C/H = 15.5, and N/H = 40.0 in the early decline phase and O/H = 5.8, He/H = 1.5, and N/H = 22.0 in the nebular phase.
$^{-1}$. Our abundance analysis shows that the ejecta is significantly enhanced relative to solar, O/H = 32.2, C/H = 15.5, and N/H = 40.0 in the early decline phase and O/H = 5.8, He/H = 1.5, and N/H = 22.0 in the nebular phase.
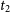







Increasing the detectability of long-period and nulling pulsars in next-generation pulsar surveys
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 19 September 2024, e046
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent discoveries of multiple long-period pulsars (periods
 ${\sim}10\,$s or larger) are starting to challenge the conventional notion that coherent radio emission cannot be produced by objects that are below the many theorised death lines. Many of the past pulsar surveys and software have been prone to selection effects that restricted their sensitivities towards long-period and sporadically emitting objects. Pulsar surveys using new-generation low-frequency facilities are starting to employ longer dwell times, which makes them significantly more sensitive in detecting long-period or nulling pulsars. There have also been software advancements to aid more sensitive searches towards long-period objects. Furthermore, recent discoveries suggest that nulling may be a key aspect of the long-period pulsar population. We simulate both long-period and nulling pulsar signals, using the Southern-sky MWA Rapid Two-meter (SMART) survey data as reference and explore the detection efficacy of popular search methods such as the fast Fourier transform (FFT), fast-folding algorithm (FFA) and single pulse search (SPS). For FFT-based search and SPS, we make use of the PRESTO implementation, and for FFA we use RIPTIDE. We find RIPTIDE’s FFA to be more sensitive; however, it is also the slowest algorithm. PRESTO’s FFT, although faster than others, also shows some unexpected inaccuracies in detection properties. SPS is highly sensitive to long-period and nulling signals, but only for pulses with high intrinsic signal-to-noise ratios. We use these findings to inform current and future pulsar surveys that aim to uncover a large population of long-period or nulling objects and comment on how to make optimal use of these methods in unison.
${\sim}10\,$s or larger) are starting to challenge the conventional notion that coherent radio emission cannot be produced by objects that are below the many theorised death lines. Many of the past pulsar surveys and software have been prone to selection effects that restricted their sensitivities towards long-period and sporadically emitting objects. Pulsar surveys using new-generation low-frequency facilities are starting to employ longer dwell times, which makes them significantly more sensitive in detecting long-period or nulling pulsars. There have also been software advancements to aid more sensitive searches towards long-period objects. Furthermore, recent discoveries suggest that nulling may be a key aspect of the long-period pulsar population. We simulate both long-period and nulling pulsar signals, using the Southern-sky MWA Rapid Two-meter (SMART) survey data as reference and explore the detection efficacy of popular search methods such as the fast Fourier transform (FFT), fast-folding algorithm (FFA) and single pulse search (SPS). For FFT-based search and SPS, we make use of the PRESTO implementation, and for FFA we use RIPTIDE. We find RIPTIDE’s FFA to be more sensitive; however, it is also the slowest algorithm. PRESTO’s FFT, although faster than others, also shows some unexpected inaccuracies in detection properties. SPS is highly sensitive to long-period and nulling signals, but only for pulses with high intrinsic signal-to-noise ratios. We use these findings to inform current and future pulsar surveys that aim to uncover a large population of long-period or nulling objects and comment on how to make optimal use of these methods in unison.

Multi-band optical variability on diverse timescales of blazar 1E 1458.8+2249
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 19 September 2024, e052
-
- Article
- Export citation
-
This study presents an analysis of the optical variability of the blazar 1E 1458.8+2249 on diverse timescales using multi-band observations, including observations in the optical BVRI bands carried out with the T60 and T100 telescopes from 2020 to 2023 and ZTF gri data from 2018 to 2023. On seven nights, we searched for intraday variability using the power-enhanced F-test and the nested ANOVA test, but no significant variability was found. The long-term light curve shows a variability behaviour in the optical BVRI bands with amplitudes of
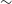 $\sim$100% and in the gri bands with amplitudes of
$\sim$100% and in the gri bands with amplitudes of 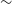 $\sim$120%, including short-term variability of up to
$\sim$120%, including short-term variability of up to  $\sim$1.1 mag. Correlation analysis revealed a strong correlation between the optical multi-band emissions without any time lag. From 62 nightly spectral energy distributions, we obtained spectral indices between 0.826 and 1.360, with an average of
$\sim$1.1 mag. Correlation analysis revealed a strong correlation between the optical multi-band emissions without any time lag. From 62 nightly spectral energy distributions, we obtained spectral indices between 0.826 and 1.360, with an average of  $1.128\pm0.063$. The relationships of both spectral indices and colour with respect to brightness indicate a mild BWB trend throughout the observation period, both intraday and long-term. We also performed a periodicity search using the weighted wavelet Z-transform and Lomb–Scargle methods. A recurrent optical emission pattern with a quasi-periodicity of
$1.128\pm0.063$. The relationships of both spectral indices and colour with respect to brightness indicate a mild BWB trend throughout the observation period, both intraday and long-term. We also performed a periodicity search using the weighted wavelet Z-transform and Lomb–Scargle methods. A recurrent optical emission pattern with a quasi-periodicity of  $\sim$340 days is detected in the combined V- and R-band light curves. The observational results indicate that the blazar 1E 1458.8+2249 has a complex variability, while emphasising the need for future observations to unravel its underlying mechanisms.
$\sim$340 days is detected in the combined V- and R-band light curves. The observational results indicate that the blazar 1E 1458.8+2249 has a complex variability, while emphasising the need for future observations to unravel its underlying mechanisms.



Imaging pulsar census of the galactic plane using MWA VCS data
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 18 September 2024, e045
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Traditional pulsar surveys have primarily employed time-domain periodicity searches. However, these methods are susceptible to effects like scattering, eclipses, and orbital motion. At lower radio frequencies (
 $\lesssim$300 MHz), factors such as dispersion measure and pulse broadening become more prominent, reducing the detection sensitivity. On the other hand, image domain searches for pulsars are not limited by these effects and can extend the parameter space to regions inaccessible to traditional search techniques. Therefore, we have developed a pipeline to form 1-second full Stokes images from offline correlated high time-resolution data from the Murchison Widefield Array (MWA). This led to the development of image-based methodologies to identify new pulsar candidates. In this paper, we applied these methodologies to perform a low-frequency image-based pulsar census of the galactic plane (12 MWA observations, covering
$\lesssim$300 MHz), factors such as dispersion measure and pulse broadening become more prominent, reducing the detection sensitivity. On the other hand, image domain searches for pulsars are not limited by these effects and can extend the parameter space to regions inaccessible to traditional search techniques. Therefore, we have developed a pipeline to form 1-second full Stokes images from offline correlated high time-resolution data from the Murchison Widefield Array (MWA). This led to the development of image-based methodologies to identify new pulsar candidates. In this paper, we applied these methodologies to perform a low-frequency image-based pulsar census of the galactic plane (12 MWA observations, covering  $\sim$6 000
$\sim$6 000 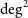 $\textrm{deg}^\textrm{2}$ sky). This work focuses on the detection of the known pulsar population which were present in the observed region of the sky using both image-based and beamformed methods. This resulted in the detection of 83 known pulsars, with 16 pulsars found only in Stokes I images but not in periodicity searches applied in beamformed data. Notably, for 14 pulsars these are the first reported low-frequency detections. This underscores the importance of image-based searches for pulsars that may be undetectable in time-series data, due to scattering and/or dispersive smearing at low frequencies. This highlights the importance of low-frequency flux density measurements in refining pulsar spectral models and investigating the spectral turnover of pulsars at low frequencies.
$\textrm{deg}^\textrm{2}$ sky). This work focuses on the detection of the known pulsar population which were present in the observed region of the sky using both image-based and beamformed methods. This resulted in the detection of 83 known pulsars, with 16 pulsars found only in Stokes I images but not in periodicity searches applied in beamformed data. Notably, for 14 pulsars these are the first reported low-frequency detections. This underscores the importance of image-based searches for pulsars that may be undetectable in time-series data, due to scattering and/or dispersive smearing at low frequencies. This highlights the importance of low-frequency flux density measurements in refining pulsar spectral models and investigating the spectral turnover of pulsars at low frequencies.


High-time resolution GPU imager for FRB searches at low radio frequencies
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 18 September 2024, e042
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Fast Radio Bursts (FRBs) are millisecond dispersed radio pulses of predominately extra-galactic origin. Although originally discovered at GHz frequencies, most FRBs have been detected between 400 and 800 MHz. Nevertheless, only a handful of FRBs were detected at radio frequencies
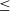 $\le$400 MHz. Searching for FRBs at low frequencies is computationally challenging due to increased dispersive delay that must be accounted for. Nevertheless, the wide field of view (FoV) of low-frequency telescopes – such as the the Murchison Widefield Array (MWA), and prototype stations of the low-frequency Square Kilometre Array (SKA-Low) – makes them promising instruments to open a low-frequency window on FRB event rates, and constrain FRB emission models. The standard approach, inherited from high-frequencies, is to form multiple tied-array beams to tessellate the entire FoV and perform the search on the resulting time series. This approach, however, may not be optimal for low-frequency interferometers due to their large FoVs and high spatial resolutions leading to a large number of beams. Consequently, there are regions of parameter space in terms of number of antennas and resolution elements (pixels) where interferometric imaging is computationally more efficient. Here we present a new high-time resolution imager BLINK implemented on modern graphical processing units (GPUs) and intended for radio astronomy data. The main goal for this imager is to become part of a fully GPU-accelerated FRB search pipeline. We describe the imager and present its verification on real and simulated data processed to form all-sky and widefield images from the MWA and prototype SKA-Low stations. We also present and compare benchmarks of the GPU and CPU code executed on laptops, desktop computers, and Australian supercomputers. The code is publicly available at https://github.com/PaCER-BLINK-Project/imager and can be applied to data from any radio telescope.
$\le$400 MHz. Searching for FRBs at low frequencies is computationally challenging due to increased dispersive delay that must be accounted for. Nevertheless, the wide field of view (FoV) of low-frequency telescopes – such as the the Murchison Widefield Array (MWA), and prototype stations of the low-frequency Square Kilometre Array (SKA-Low) – makes them promising instruments to open a low-frequency window on FRB event rates, and constrain FRB emission models. The standard approach, inherited from high-frequencies, is to form multiple tied-array beams to tessellate the entire FoV and perform the search on the resulting time series. This approach, however, may not be optimal for low-frequency interferometers due to their large FoVs and high spatial resolutions leading to a large number of beams. Consequently, there are regions of parameter space in terms of number of antennas and resolution elements (pixels) where interferometric imaging is computationally more efficient. Here we present a new high-time resolution imager BLINK implemented on modern graphical processing units (GPUs) and intended for radio astronomy data. The main goal for this imager is to become part of a fully GPU-accelerated FRB search pipeline. We describe the imager and present its verification on real and simulated data processed to form all-sky and widefield images from the MWA and prototype SKA-Low stations. We also present and compare benchmarks of the GPU and CPU code executed on laptops, desktop computers, and Australian supercomputers. The code is publicly available at https://github.com/PaCER-BLINK-Project/imager and can be applied to data from any radio telescope.
Measuring the stellar and planetary parameters of the 51 Eridani system
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 18 September 2024, e043
-
- Article
- Export citation
-
In order to study exoplanets, a comprehensive characterisation of the fundamental properties of the host stars – such as angular diameter, temperature, luminosity, and age, is essential, as the formation and evolution of exoplanets are directly influenced by the host stars at various points in time. In this paper, we present interferometric observations taken of directly imaged planet host 51 Eridani at the CHARA Array. We measure the limb-darkened angular diameter of 51 Eridani to be
 $\theta_\mathrm{LD} = 0.450\pm 0.006$ mas and combining with the Gaia zero-point corrected parallax, we get a stellar radius of
$\theta_\mathrm{LD} = 0.450\pm 0.006$ mas and combining with the Gaia zero-point corrected parallax, we get a stellar radius of  $1.45 \pm 0.02$ R
$1.45 \pm 0.02$ R $_{\odot}$. We use the PARSEC isochrones to estimate an age of
$_{\odot}$. We use the PARSEC isochrones to estimate an age of  $23.2^{+1.7}_{-2.0}$ Myr and a mass of
$23.2^{+1.7}_{-2.0}$ Myr and a mass of  $1.550^{+0.006}_{-0.005}$ M
$1.550^{+0.006}_{-0.005}$ M $_{\odot}$. The age and mass agree well with values in the literature, determined through a variety of methods ranging from dynamical age trace-backs to lithium depletion boundary methods. We derive a mass of
$_{\odot}$. The age and mass agree well with values in the literature, determined through a variety of methods ranging from dynamical age trace-backs to lithium depletion boundary methods. We derive a mass of  $4.1\pm0.4$ M
$4.1\pm0.4$ M $_\mathrm{Jup}$ for 51 Eri b using the Sonora Bobcat models, which further supports the possibility of 51 Eri b forming under either the hot-start formation model or the warm-start formation model.
$_\mathrm{Jup}$ for 51 Eri b using the Sonora Bobcat models, which further supports the possibility of 51 Eri b forming under either the hot-start formation model or the warm-start formation model.








3D relativistic MHD simulations of the gamma-ray binaries
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 18 September 2024, e048
-
- Article
- Export citation
-
In gamma-ray binaries neutron star is orbiting a companion that produces a strong stellar wind. We demonstrate that observed properties of ‘stellar wind’–‘pulsar wind’ interaction depend both on the overall wind thrust ratio, as well as more subtle geometrical factors: the relative direction of the pulsar’s spin, the plane of the orbit, the direction of motion, and the instantaneous line of sight. Using fully 3D relativistic magnetohydrodynamical simulations we find that the resulting intrinsic morphologies can be significantly orbital phase-dependent: a given system may change from tailward-open to tailward-closed shapes. As a result, the region of unshocked pulsar wind can change by an order of magnitude over a quarter of the orbit. We calculate radiation maps and synthetic light curves for synchrotron (X-ray) and inverse-Compton emission (GeV-TeV), taking into account
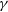 $\gamma $–
$\gamma $–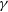 $\gamma $ absorption. Our modelled light curves are in agreement with the phase-dependent observed light curves of LS5039.
$\gamma $ absorption. Our modelled light curves are in agreement with the phase-dependent observed light curves of LS5039.
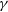
The global structure of astrospheres: Effect of Knudsen number
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 11 July 2024, e074
-
- Article
- Export citation
The Rapid ASKAP Continuum Survey III: Spectra and Polarisation In Cutouts of Extragalactic Sources (SPICE-RACS) first data release – CORRIGENDUM
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 03 June 2024, e039
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Nucleation regions in the Large-Scale Structure I: A catalogue of cores in nearby rich superclusters
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 03 June 2024, e078
-
- Article
- Export citation
Orbital period variation analysis of the HS 0705+6700 post-common envelope binary
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 03 June 2024, e047
-
- Article
- Export citation
-
To detect additional bodies in binary systems, we performed a potent approach of orbital period variation analysis. In this work, we present 90 new mid-eclipse times of a short-period eclipsing binary system. Observations were made using two telescopes from 2014 to 2024, extending the time span of the
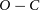 $O-C$ diagram to 24 yr. The data obtained in the last seven years indicate significant deviations in the
$O-C$ diagram to 24 yr. The data obtained in the last seven years indicate significant deviations in the 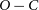 $O-C$ diagram from the models obtained in previous studies. We investigated whether this variation could be explained by mechanisms such as the LTT effect or Applegate. To investigate the cyclic behaviour observed in the system with the light travel time effect, we modelled the updated
$O-C$ diagram from the models obtained in previous studies. We investigated whether this variation could be explained by mechanisms such as the LTT effect or Applegate. To investigate the cyclic behaviour observed in the system with the light travel time effect, we modelled the updated  $O-C$ diagram using different models including linear/quadratic terms and additional bodies. The updated
$O-C$ diagram using different models including linear/quadratic terms and additional bodies. The updated 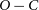 $O-C$ diagram is statistically consistent with the most plausible solutions of models that include multiple brown dwarfs close to each other. However, it has been found that the orbit of the system is unstable on short time scales. Using three different theoretical definitions, we have found that the Applegate mechanism cannot explain the variation in the orbital period except for the model containing the fifth body. Therefore, due to the complex nature of the system, further mid-eclipse time is required before any conclusions can be drawn about the existence of additional bodies.
$O-C$ diagram is statistically consistent with the most plausible solutions of models that include multiple brown dwarfs close to each other. However, it has been found that the orbit of the system is unstable on short time scales. Using three different theoretical definitions, we have found that the Applegate mechanism cannot explain the variation in the orbital period except for the model containing the fifth body. Therefore, due to the complex nature of the system, further mid-eclipse time is required before any conclusions can be drawn about the existence of additional bodies.

Hierarchical hub-filament structures and gas inflows on galaxy-cloud scales
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 03 June 2024, e076
-
- Article
- Export citation
-
We investigated the kinematics and dynamics of gas structures on galaxy-cloud scales in two spiral galaxies NGC5236 (M83) and NGC4321 (M100) using CO (2
 $-$1) line. We utilised the FILFINDER algorithm on integrated intensity maps for the identification of filaments in two galaxies. Clear fluctuations in velocity and density were observed along these filaments, enabling the fitting of velocity gradients around intensity peaks. The variations in velocity gradient across different scales suggest a gradual and consistent increase in velocity gradient from large to small scales, indicative of gravitational collapse, something also revealed by the correlation between velocity dispersion and column density of gas structures. Gas structures at different scales in the galaxy may be organised into hierarchical systems through gravitational coupling. All the features of gas kinematics on galaxy-cloud scale are very similar to that on cloud-clump and clump-core scales studied in previous works. Thus, the interstellar medium from galaxy to dense core scales presents multi-scale/hierarchical hub-filament structures. Like dense core as the hub in clump, clump as the hub in molecular cloud, now we verify that cloud or cloud complex can be the hub in spiral galaxies. Although the scaling relations and the measured velocity gradients support the gravitational collapse of gas structures on galaxy-cloud scales, the collapse is much slower than a pure free-fall gravitational collapse.
$-$1) line. We utilised the FILFINDER algorithm on integrated intensity maps for the identification of filaments in two galaxies. Clear fluctuations in velocity and density were observed along these filaments, enabling the fitting of velocity gradients around intensity peaks. The variations in velocity gradient across different scales suggest a gradual and consistent increase in velocity gradient from large to small scales, indicative of gravitational collapse, something also revealed by the correlation between velocity dispersion and column density of gas structures. Gas structures at different scales in the galaxy may be organised into hierarchical systems through gravitational coupling. All the features of gas kinematics on galaxy-cloud scale are very similar to that on cloud-clump and clump-core scales studied in previous works. Thus, the interstellar medium from galaxy to dense core scales presents multi-scale/hierarchical hub-filament structures. Like dense core as the hub in clump, clump as the hub in molecular cloud, now we verify that cloud or cloud complex can be the hub in spiral galaxies. Although the scaling relations and the measured velocity gradients support the gravitational collapse of gas structures on galaxy-cloud scales, the collapse is much slower than a pure free-fall gravitational collapse.

Keck/KCWI spectroscopy of globular clusters in local volume dwarf galaxies
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 May 2024, e044
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rotation of the globular cluster population of the dark matter deficient galaxy NGC 1052-DF4: Implication for the total mass
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 May 2024, e073
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evolutionary map of the universe (EMU): Observations of filamentary structures in the Abell S1136 galaxy cluster
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 23 May 2024, e050
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present radio observations of the galaxy cluster Abell S1136 at 888 MHz, using the Australian Square Kilometre Array Pathfinder radio telescope, as part of the Evolutionary Map of the Universe Early Science program. We compare these findings with data from the Murchison Widefield Array, XMM-Newton, the Wide-field Infrared Survey Explorer, the Digitised Sky Survey, and the Australia Telescope Compact Array. Our analysis shows the X-ray and radio emission in Abell S1136 are closely aligned and centered on the Brightest Cluster Galaxy, while the X-ray temperature profile shows a relaxed cluster with no evidence of a cool core. We find that the diffuse radio emission in the centre of the cluster shows more structure than seen in previous low-resolution observations of this source, which appeared formerly as an amorphous radio blob, similar in appearance to a radio halo; our observations show the diffuse emission in the Abell S1136 galaxy cluster contains three narrow filamentary structures visible at 888 MHz, between
 $\sim$80 and 140 kpc in length; however, the properties of the diffuse emission do not fully match that of a radio (mini-)halo or (fossil) tailed radio source.
$\sim$80 and 140 kpc in length; however, the properties of the diffuse emission do not fully match that of a radio (mini-)halo or (fossil) tailed radio source.

An optical daytime astronomy pathfinder for the Huntsman Telescope
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 20 May 2024, e056
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Observing stars and satellites in optical wavelengths during the day (optical daytime astronomy) has begun a resurgence of interest. The recent dramatic dimming event of Betelgeuse has spurred interest in continuous monitoring of the brightest variable stars, even when an object is only visible during the day due to their proximity to the Sun. In addition, an exponential increase in the number of satellites being launched into low Earth orbit in recent years has driven an interest in optical daytime astronomy for the detection and monitoring of satellites in space situational awareness (SSA) networks. In this paper we explore the use of the Huntsman Telescope as an optical daytime astronomy facility, by conducting an exploratory survey using a pathfinder instrument. We find that an absolute photometric accuracy between 1–10% can be achieved during the day, with a detection limit of V band 4.6 mag at midday in sloan
 $g,$ and
$g,$ and  $r,$ wavelengths. In addition, we characterise the daytime sky brightness, colour, and observing conditions in order to achieve the most reliable and highest signal-to-noise observations within the limitations of the bright sky background. We undertake a 7-month survey of the brightness of Betelgeuse during the day and demonstrate that our results are in agreement with measurements from other observatories. Finally we present our preliminary results that demonstrate obtaining absolute photometric measurements of the International Space Station during the day.
$r,$ wavelengths. In addition, we characterise the daytime sky brightness, colour, and observing conditions in order to achieve the most reliable and highest signal-to-noise observations within the limitations of the bright sky background. We undertake a 7-month survey of the brightness of Betelgeuse during the day and demonstrate that our results are in agreement with measurements from other observatories. Finally we present our preliminary results that demonstrate obtaining absolute photometric measurements of the International Space Station during the day.


