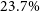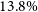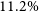Refine search
Actions for selected content:
28356 results in Astrophysics
Mode identification and period fitting in six pulsating hot subdwarfs
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 16 May 2024, e041
-
- Article
- Export citation
On bursty star formation during cosmological reionisation – how does it influence the baryon mass content of dark matter halos?
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 13 May 2024, e049
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The baryon mass content (i.e. stellar and gas mass) of dark matter halos in the early Universe depends on both global factors – for example, ionising ultraviolet (UV) radiation background – and local factors – for example, star formation efficiency and assembly history. We use a lightweight semi-analytical model to investigate how both local and global factors impact the halo baryon mass content at redshifts of
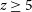 $z\geq 5$. Our model incorporates a time delay between when stars form and when they produce feedback of
$z\geq 5$. Our model incorporates a time delay between when stars form and when they produce feedback of 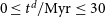 $0\leq t^d/\mathrm{Myr} \leq 30$, which can drive bursts of star formation, and a mass and redshift-dependent UV background, which captures the influence of cosmological reionisation on gas accretion onto halos. We use statistically representative halo assembly histories and assume that the cosmological gas accretion rate is proportional to the halo mass accretion rate. Delayed (
$0\leq t^d/\mathrm{Myr} \leq 30$, which can drive bursts of star formation, and a mass and redshift-dependent UV background, which captures the influence of cosmological reionisation on gas accretion onto halos. We use statistically representative halo assembly histories and assume that the cosmological gas accretion rate is proportional to the halo mass accretion rate. Delayed (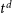 $t^d$>0) feedback leads to oscillations in gas mass with cosmic time, behaviour that cannot be captured with instantaneous feedback (
$t^d$>0) feedback leads to oscillations in gas mass with cosmic time, behaviour that cannot be captured with instantaneous feedback (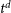 $t^d$=0). Highly efficient star formation drives stronger oscillations, while strong feedback impacts when oscillations occur; in contrast, inefficient star formation and weak feedback produce similar long-term behaviour to that observed in instantaneous feedback models. If the delayed feedback timescale is too long, a halo retains its gas reservoir but the feedback suppresses star formation. Our model predicts that lower mass systems (halo masses
$t^d$=0). Highly efficient star formation drives stronger oscillations, while strong feedback impacts when oscillations occur; in contrast, inefficient star formation and weak feedback produce similar long-term behaviour to that observed in instantaneous feedback models. If the delayed feedback timescale is too long, a halo retains its gas reservoir but the feedback suppresses star formation. Our model predicts that lower mass systems (halo masses 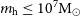 $m_\mathrm{h} \leq 10^7 \mathrm{M}_\odot$) at
$m_\mathrm{h} \leq 10^7 \mathrm{M}_\odot$) at 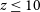 $z \leq 10$ should be strongly gas deficient (
$z \leq 10$ should be strongly gas deficient (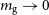 $m_\mathrm{g}\rightarrow 0$), whereas higher mass systems retain their gas reservoirs because they are sufficiently massive to continue accreting gas through cosmological reionisation. Interestingly, in higher mass halos, the median
$m_\mathrm{g}\rightarrow 0$), whereas higher mass systems retain their gas reservoirs because they are sufficiently massive to continue accreting gas through cosmological reionisation. Interestingly, in higher mass halos, the median 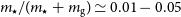 $m_\star/(m_\star+m_\mathrm{g}) \simeq 0.01-0.05$, but is a factor of 3–5 smaller when feedback is delayed. Our model does not include seed supermassive black hole feedback, which is necessary to explain massive quenched galaxies in the early Universe.
$m_\star/(m_\star+m_\mathrm{g}) \simeq 0.01-0.05$, but is a factor of 3–5 smaller when feedback is delayed. Our model does not include seed supermassive black hole feedback, which is necessary to explain massive quenched galaxies in the early Universe.
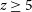
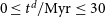
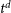
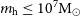
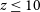
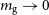
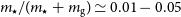
MOSEL survey: Unwrapping the Epoch of Reionisation through mimic galaxies at Cosmic Noon
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 09 May 2024, e040
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The nature of the first galaxies that reionised the universe during the Epoch of Reionisation (EoR) remains unclear. Attempts to directly determine spectral properties of these early galaxies are affected by both limited photometric constraints across the spectrum and by the opacity of the intergalactic medium to the Lyman Continuum (LyC) at high redshift. We approach this by analysing properties of analogous extreme emission line galaxies (EELGs, [OIII]+Hbeta EW
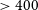 $\gt 400$) at
$\gt 400$) at 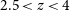 $2.5\lt z\lt 4$ from the ZFOURGE survey using the Multi-wavelength Analysis of Galaxy Physical Properties (MAGPHYS) SED fitting code. We compare these to galaxies at
$2.5\lt z\lt 4$ from the ZFOURGE survey using the Multi-wavelength Analysis of Galaxy Physical Properties (MAGPHYS) SED fitting code. We compare these to galaxies at 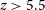 $z \gt 5.5$ observed with the James Webb Space Telesope with self-consistent spectral energy distribution fitting methodology. This work focuses on the comparison of their UV slopes (
$z \gt 5.5$ observed with the James Webb Space Telesope with self-consistent spectral energy distribution fitting methodology. This work focuses on the comparison of their UV slopes (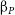 ${\unicode{x03B2}}_P$), ionising photon production efficiencies
${\unicode{x03B2}}_P$), ionising photon production efficiencies 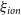 $\xi_{ion}$, star formation rates and dust properties to determine the effectiveness of this analogue selection technique. We report the median ionising photon production efficiencies as log
$\xi_{ion}$, star formation rates and dust properties to determine the effectiveness of this analogue selection technique. We report the median ionising photon production efficiencies as log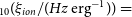 $_{10}(\xi_{ion}/(Hz\ {\rm erg}^{-1}))=$
$_{10}(\xi_{ion}/(Hz\ {\rm erg}^{-1}))=$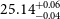 $25.14^{+0.06}_{-0.04}$,
$25.14^{+0.06}_{-0.04}$, 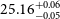 $25.16^{+0.06}_{-0.05}$,
$25.16^{+0.06}_{-0.05}$, 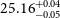 $25.16^{+0.04}_{-0.05}$,
$25.16^{+0.04}_{-0.05}$, 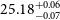 $25.18^{+0.06}_{-0.07}$ for our ZFOURGE control, ZFOURGE EELG, JADES, and CEERS samples, respectively. ZFOURGE EELGs are 0.57 dex lower in stellar mass and have half the dust extinction, compared to their ZFOURGE control counterparts. They also have a similar specific star formation rates and
$25.18^{+0.06}_{-0.07}$ for our ZFOURGE control, ZFOURGE EELG, JADES, and CEERS samples, respectively. ZFOURGE EELGs are 0.57 dex lower in stellar mass and have half the dust extinction, compared to their ZFOURGE control counterparts. They also have a similar specific star formation rates and 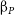 ${\unicode{x03B2}}_P$ to the
${\unicode{x03B2}}_P$ to the 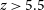 $z\gt 5.5$ samples. We find that EELGs at low redshift (
$z\gt 5.5$ samples. We find that EELGs at low redshift (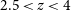 $2.5\lt z\lt 4$) are analogous to EoR galaxies in their dust attenuation and specific star formation rates. Their extensive photometric coverage and the accessibility of their LyC region opens pathways to infer stellar population properties in the EoR.
$2.5\lt z\lt 4$) are analogous to EoR galaxies in their dust attenuation and specific star formation rates. Their extensive photometric coverage and the accessibility of their LyC region opens pathways to infer stellar population properties in the EoR.
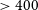
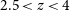
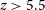
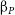
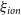
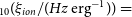
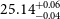
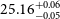
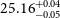
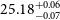
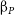
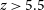
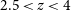
Reduced-resolution beamforming: Lowering the computational cost for pulsar and technosignature surveys
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 07 May 2024, e037
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Verifying the Australian MWA EoR pipeline I: 21-cm sky model and correlated measurement density
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e067
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
System design and validation of Central Redundant Array Mega-tile (CRAM)
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e034
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Exploration of the 21cm signal during the Cosmic Dawn and the Epoch of Reionisation (EoR) can unravel the mysteries of the early Universe when the first stars and galaxies were born and ionised, respectively. However, the 21 cm signal is exceptionally weak, and thus, the detection amidst the bright foregrounds is extremely challenging. The Murchison Widefield Array (MWA) aims to measure the brightness temperature fluctuations of neutral hydrogen from the early Universe. The MWA telescope observes the radio sky with a large field of view (FoV) that causes the bright galaxies, especially near the horizon, to contaminate the measurements. These foregrounds contaminating the EoR datasets must be meticulously removed or treated to detect the signal successfully. The Central Redundant Array Mega-tile (CRAM) is a zenith-pointing new instrument, installed at the centre of the MWA Phase II southern hexagonal configuration, comprising of 64 dipoles in an
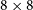 $8 \times 8$ configuration with a FoV half the width of the MWA’s at every frequency under consideration. The primary objective of this new instrument is to mitigate the impact of bright radio sources near the field centre in accordance with the reduced primary beamshape and to reduce the contamination of foreground sources near the horizon with the reduced sidelobe response of the larger array configuration. In this paper, we introduce the new instrument to the community and present the system architecture and characteristics of the instrument. Using the first light observations, we determine the CRAM system temperature and system performance.
$8 \times 8$ configuration with a FoV half the width of the MWA’s at every frequency under consideration. The primary objective of this new instrument is to mitigate the impact of bright radio sources near the field centre in accordance with the reduced primary beamshape and to reduce the contamination of foreground sources near the horizon with the reduced sidelobe response of the larger array configuration. In this paper, we introduce the new instrument to the community and present the system architecture and characteristics of the instrument. Using the first light observations, we determine the CRAM system temperature and system performance.
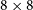
Galaxy 3D shape recovery using mixture density network
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 18 April 2024, e033
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Low-frequency pulse-jitter measurement with the uGMRT I: PSR J0437–4715
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 16 April 2024, e036
-
- Article
- Export citation
-
High-precision pulsar timing observations are limited in their accuracy by the jitter noise that appears in the arrival time of pulses. Therefore, it is important to systematically characterise the amplitude of the jitter noise and its variation with frequency. In this paper, we provide jitter measurements from low-frequency wideband observations of PSR J0437
 $-$4715 using data obtained as part of the Indian Pulsar Timing Array experiment. We were able to detect jitter in both the 300–500 MHz and 1 260–1 460 MHz observations of the upgraded Giant Metrewave Radio Telescope (uGMRT). The former is the first jitter measurement for this pulsar below 700 MHz, and the latter is in good agreement with results from previous studies. In addition, at 300–500 MHz, we investigated the frequency dependence of the jitter by calculating the jitter for each sub-banded arrival time of pulses. We found that the jitter amplitude increases with frequency. This trend is opposite as compared to previous studies, indicating that there is a turnover at intermediate frequencies. It will be possible to investigate this in more detail with uGMRT observations at 550–750 MHz and future high-sensitive wideband observations from next generation telescopes, such as the Square Kilometre Array. We also explored the effect of jitter on the high precision dispersion measure (DM) measurements derived from short duration observations. We find that even though the DM precision will be better at lower frequencies due to the smaller amplitude of jitter noise, it will limit the DM precision for high signal-to-noise observations, which are of short durations. This limitation can be overcome by integrating for a long enough duration optimised for a given pulsar.
$-$4715 using data obtained as part of the Indian Pulsar Timing Array experiment. We were able to detect jitter in both the 300–500 MHz and 1 260–1 460 MHz observations of the upgraded Giant Metrewave Radio Telescope (uGMRT). The former is the first jitter measurement for this pulsar below 700 MHz, and the latter is in good agreement with results from previous studies. In addition, at 300–500 MHz, we investigated the frequency dependence of the jitter by calculating the jitter for each sub-banded arrival time of pulses. We found that the jitter amplitude increases with frequency. This trend is opposite as compared to previous studies, indicating that there is a turnover at intermediate frequencies. It will be possible to investigate this in more detail with uGMRT observations at 550–750 MHz and future high-sensitive wideband observations from next generation telescopes, such as the Square Kilometre Array. We also explored the effect of jitter on the high precision dispersion measure (DM) measurements derived from short duration observations. We find that even though the DM precision will be better at lower frequencies due to the smaller amplitude of jitter noise, it will limit the DM precision for high signal-to-noise observations, which are of short durations. This limitation can be overcome by integrating for a long enough duration optimised for a given pulsar.

Some findings from the longitudinal migration of starspots
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 11 April 2024, e031
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present results regarding the longitudinal migrations of cool stellar spots that exhibit remarkable oscillations and explore their possible causes. We conducted analyses using high-quality data from nine target systems of various spectral types, spanning from F to M, which were observed by the Kepler Satellite. The systems in which the behaviour of the spots was examined are as follows: KIC 4357272, KIC 6025466, KIC 6058875, KIC 6962018, KIC 7798259, KIC 9210828, KIC 11706658, KIC 12599700, and KIC 8669092. Basic stellar parameters were calculated from light curve analysis using the PHOEBE V.0.32 software, and light curves were modelled to obtain sinusoidal variations occurring out-of-eclipses phases, induced by rotational modulation. Subsequently, we calculated the minimum times of the obtained sinusoidal variations using the Fourier transform. The distributions of
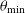 ${\theta}_{\min}$ corresponding to these minimum times over time were computed using linear fits to determine the longitudinal migrations of the spotted areas. We then compared the longitudinal migration periods with the stellar parameters found in the literature. In addition, we also found a secondary variation in the spot migrations apart from the linear models. Our results revealed that the longitudinal migration periods vary in relation to the
${\theta}_{\min}$ corresponding to these minimum times over time were computed using linear fits to determine the longitudinal migrations of the spotted areas. We then compared the longitudinal migration periods with the stellar parameters found in the literature. In addition, we also found a secondary variation in the spot migrations apart from the linear models. Our results revealed that the longitudinal migration periods vary in relation to the 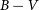 $B-V$ colour index of the stars.
$B-V$ colour index of the stars.
VaTEST III: Validation of eight potential super-earths from TESS data
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 11 April 2024, e030
-
- Article
- Export citation
-
NASA’s all-sky survey mission, the Transiting Exoplanet Survey Satellite (TESS), is specifically engineered to detect exoplanets that transit bright stars. Thus far, TESS has successfully identified approximately 400 transiting exoplanets, in addition to roughly 6 000 candidate exoplanets pending confirmation. In this study, we present the results of our ongoing project, the Validation of Transiting Exoplanets using Statistical Tools (VaTEST). Our dedicated effort is focused on the confirmation and characterisation of new exoplanets through the application of statistical validation tools. Through a combination of ground-based telescope data, high-resolution imaging, and the utilisation of the statistical validation tool known as TRICERATOPS, we have successfully discovered eight potential super-Earths. These planets bear the designations: TOI-238b (1.61
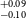 $^{+0.09} _{-0.10}$ R
$^{+0.09} _{-0.10}$ R $_\oplus$), TOI-771b (1.42
$_\oplus$), TOI-771b (1.42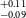 $^{+0.11} _{-0.09}$ R
$^{+0.11} _{-0.09}$ R $_\oplus$), TOI-871b (1.66
$_\oplus$), TOI-871b (1.66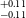 $^{+0.11} _{-0.11}$ R
$^{+0.11} _{-0.11}$ R $_\oplus$), TOI-1467b (1.83
$_\oplus$), TOI-1467b (1.83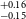 $^{+0.16} _{-0.15}$ R
$^{+0.16} _{-0.15}$ R $_\oplus$), TOI-1739b (1.69
$_\oplus$), TOI-1739b (1.69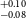 $^{+0.10} _{-0.08}$ R
$^{+0.10} _{-0.08}$ R $_\oplus$), TOI-2068b (1.82
$_\oplus$), TOI-2068b (1.82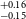 $^{+0.16} _{-0.15}$ R
$^{+0.16} _{-0.15}$ R $_\oplus$), TOI-4559b (1.42
$_\oplus$), TOI-4559b (1.42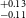 $^{+0.13} _{-0.11}$ R
$^{+0.13} _{-0.11}$ R $_\oplus$), and TOI-5799b (1.62
$_\oplus$), and TOI-5799b (1.62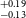 $^{+0.19} _{-0.13}$ R
$^{+0.19} _{-0.13}$ R $_\oplus$). Among all these planets, six of them fall within the region known as ‘keystone planets’, which makes them particularly interesting for study. Based on the location of TOI-771b and TOI-4559b below the radius valley we characterised them as likely super-Earths, though radial velocity mass measurements for these planets will provide more details about their characterisation. It is noteworthy that planets within the size range investigated herein are absent from our own solar system, making their study crucial for gaining insights into the evolutionary stages between Earth and Neptune.
$_\oplus$). Among all these planets, six of them fall within the region known as ‘keystone planets’, which makes them particularly interesting for study. Based on the location of TOI-771b and TOI-4559b below the radius valley we characterised them as likely super-Earths, though radial velocity mass measurements for these planets will provide more details about their characterisation. It is noteworthy that planets within the size range investigated herein are absent from our own solar system, making their study crucial for gaining insights into the evolutionary stages between Earth and Neptune.








RFI detection with spiking neural networks
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 04 April 2024, e028
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Classification of compact radio sources in the Galactic plane with supervised machine learning
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e029
-
- Article
- Export citation
-
Generation of science-ready data from processed data products is one of the major challenges in next-generation radio continuum surveys with the Square Kilometre Array (SKA) and its precursors, due to the expected data volume and the need to achieve a high degree of automated processing. Source extraction, characterization, and classification are the major stages involved in this process. In this work we focus on the classification of compact radio sources in the Galactic plane using both radio and infrared images as inputs. To this aim, we produced a curated dataset of
 $\sim$20 000 images of compact sources of different astronomical classes, obtained from past radio and infrared surveys, and novel radio data from pilot surveys carried out with the Australian SKA Pathfinder. Radio spectral index information was also obtained for a subset of the data. We then trained two different classifiers on the produced dataset. The first model uses gradient-boosted decision trees and is trained on a set of pre-computed features derived from the data, which include radio-infrared colour indices and the radio spectral index. The second model is trained directly on multi-channel images, employing convolutional neural networks. Using a completely supervised procedure, we obtained a high classification accuracy (F1-score > 90%) for separating Galactic objects from the extragalactic background. Individual class discrimination performances, ranging from 60% to 75%, increased by 10% when adding far-infrared and spectral index information, with extragalactic objects, PNe and Hii regions identified with higher accuracies. The implemented tools and trained models were publicly released and made available to the radioastronomical community for future application on new radio data.
$\sim$20 000 images of compact sources of different astronomical classes, obtained from past radio and infrared surveys, and novel radio data from pilot surveys carried out with the Australian SKA Pathfinder. Radio spectral index information was also obtained for a subset of the data. We then trained two different classifiers on the produced dataset. The first model uses gradient-boosted decision trees and is trained on a set of pre-computed features derived from the data, which include radio-infrared colour indices and the radio spectral index. The second model is trained directly on multi-channel images, employing convolutional neural networks. Using a completely supervised procedure, we obtained a high classification accuracy (F1-score > 90%) for separating Galactic objects from the extragalactic background. Individual class discrimination performances, ranging from 60% to 75%, increased by 10% when adding far-infrared and spectral index information, with extragalactic objects, PNe and Hii regions identified with higher accuracies. The implemented tools and trained models were publicly released and made available to the radioastronomical community for future application on new radio data.
Localisation of gamma-ray bursts from the combined SpIRIT+HERMES-TP/SP nano-satellite constellation – CORRIGENDUM
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e017
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RG-CAT: Detection pipeline and catalogue of radio galaxies in the EMU pilot survey
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e027
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present source detection and catalogue construction pipelines to build the first catalogue of radio galaxies from the 270
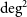 $\rm deg^2$ pilot survey of the Evolutionary Map of the Universe (EMU-PS) conducted with the Australian Square Kilometre Array Pathfinder (ASKAP) telescope. The detection pipeline uses Gal-DINO computer vision networks (Gupta et al. 2024, PASA, 41, e001) to predict the categories of radio morphology and bounding boxes for radio sources, as well as their potential infrared host positions. The Gal-DINO network is trained and evaluated on approximately 5 000 visually inspected radio galaxies and their infrared hosts, encompassing both compact and extended radio morphologies. We find that the Intersection over Union (IoU) for the predicted and ground-truth bounding boxes is larger than 0.5 for 99% of the radio sources, and 98% of predicted host positions are within
$\rm deg^2$ pilot survey of the Evolutionary Map of the Universe (EMU-PS) conducted with the Australian Square Kilometre Array Pathfinder (ASKAP) telescope. The detection pipeline uses Gal-DINO computer vision networks (Gupta et al. 2024, PASA, 41, e001) to predict the categories of radio morphology and bounding boxes for radio sources, as well as their potential infrared host positions. The Gal-DINO network is trained and evaluated on approximately 5 000 visually inspected radio galaxies and their infrared hosts, encompassing both compact and extended radio morphologies. We find that the Intersection over Union (IoU) for the predicted and ground-truth bounding boxes is larger than 0.5 for 99% of the radio sources, and 98% of predicted host positions are within 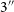 $3^{\prime \prime}$ of the ground-truth infrared host in the evaluation set. The catalogue construction pipeline uses the predictions of the trained network on the radio and infrared image cutouts based on the catalogue of radio components identified using the Selavy source finder algorithm. Confidence scores of the predictions are then used to prioritise Selavy components with higher scores and incorporate them first into the catalogue. This results in identifications for a total of 211 625 radio sources, with 201 211 classified as compact and unresolved. The remaining 10 414 are categorised as extended radio morphologies, including 582 FR-I, 5 602 FR-II, 1 494 FR-x (uncertain whether FR-I or FR-II), 2 375 R (single-peak resolved) radio galaxies, and 361 with peculiar and other rare morphologies. Each source in the catalogue includes a confidence score. We cross-match the radio sources in the catalogue with the infrared and optical catalogues, finding infrared cross-matches for 73% and photometric redshifts for 36% of the radio galaxies. The EMU-PS catalogue and the detection pipelines presented here will be used towards constructing catalogues for the main EMU survey covering the full southern sky.
$3^{\prime \prime}$ of the ground-truth infrared host in the evaluation set. The catalogue construction pipeline uses the predictions of the trained network on the radio and infrared image cutouts based on the catalogue of radio components identified using the Selavy source finder algorithm. Confidence scores of the predictions are then used to prioritise Selavy components with higher scores and incorporate them first into the catalogue. This results in identifications for a total of 211 625 radio sources, with 201 211 classified as compact and unresolved. The remaining 10 414 are categorised as extended radio morphologies, including 582 FR-I, 5 602 FR-II, 1 494 FR-x (uncertain whether FR-I or FR-II), 2 375 R (single-peak resolved) radio galaxies, and 361 with peculiar and other rare morphologies. Each source in the catalogue includes a confidence score. We cross-match the radio sources in the catalogue with the infrared and optical catalogues, finding infrared cross-matches for 73% and photometric redshifts for 36% of the radio galaxies. The EMU-PS catalogue and the detection pipelines presented here will be used towards constructing catalogues for the main EMU survey covering the full southern sky.
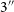
Evolutionary Map of the Universe (EMU): A pilot search for diffuse, non-thermal radio emission in galaxy clusters with the Australian SKA Pathfinder
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Clusters of galaxies have been found to host Mpc-scale diffuse, non-thermal radio emission in the form of central radio halos and peripheral relics. Turbulence and shock-related processes in the intra-cluster medium are generally considered responsible for the emission, though details of these processes are still not clear. The low surface brightness makes detection of the emission a challenge, but with recent surveys with high-sensitivity radio telescopes we are beginning to build large samples of these sources. The Evolutionary Map of the Universe (EMU) is a Southern Sky survey being performed by the Australian SKA Pathfinder (ASKAP) over the next few years and is well-suited to detect and characterise such emission. To assess prospects of the full survey, we have performed a pilot search of diffuse sources in 71 clusters from the Planck Sunyaev–Zeldovich (SZ) cluster catalogue (PSZ2) found in archival ASKAP observations. After re-imaging the archival data and performing both (u, v)-plane and image-plane angular scale filtering, we detect 21 radio halos (12 for the first time, excluding an additional six candidates), 11 relics (in seven clusters, and six for the first time, excluding a further five candidate relics), along with 12 other, unclassified diffuse radio sources. From these detections, we predict the full EMU survey will uncover up to
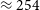 $\approx 254$ radio halos and
$\approx 254$ radio halos and 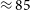 $\approx 85$ radio relics in the 858 PSZ2 clusters that will be covered by EMU. The percentage of clusters found to host diffuse emission in this work is similar to the number reported in recent cluster surveys with the LOw Frequency ARray (LOFAR) Two-metre Sky Survey [Botteon, et al. 2022a, A&A, 660, A78], suggesting EMU will complement similar searches being performed in the Northern Sky and provide us with statistically significant samples of halos and relics at the completion of the full survey. This work presents the first step towards large samples of the diffuse radio sources in Southern Sky clusters with ASKAP and eventually the SKA.
$\approx 85$ radio relics in the 858 PSZ2 clusters that will be covered by EMU. The percentage of clusters found to host diffuse emission in this work is similar to the number reported in recent cluster surveys with the LOw Frequency ARray (LOFAR) Two-metre Sky Survey [Botteon, et al. 2022a, A&A, 660, A78], suggesting EMU will complement similar searches being performed in the Northern Sky and provide us with statistically significant samples of halos and relics at the completion of the full survey. This work presents the first step towards large samples of the diffuse radio sources in Southern Sky clusters with ASKAP and eventually the SKA.
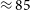
Predicting the scaling relations between the dark matter halo mass and observables from generalised profiles II: Intracluster gas emission
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 26 March 2024, e022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the connection between a cluster’s structural configuration and observable measures of its gas emission that can be obtained in X-ray and Sunyaev–Zeldovich (SZ) surveys. We present an analytic model for the intracluster gas density profile: parameterised by the dark matter halo’s inner logarithmic density slope,
 $\alpha$, the concentration, c, the gas profile’s inner logarithmic density slope,
$\alpha$, the concentration, c, the gas profile’s inner logarithmic density slope,  $\varepsilon$, the dilution, d, and the gas fraction,
$\varepsilon$, the dilution, d, and the gas fraction, 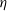 $\eta$, normalised to cosmological content. We predict four probes of the gas emission: the emission-weighted,
$\eta$, normalised to cosmological content. We predict four probes of the gas emission: the emission-weighted, 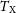 $T_\mathrm{X}$, and mean gas mass-weighted,
$T_\mathrm{X}$, and mean gas mass-weighted, 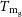 $T_\mathrm{m_g}$, temperatures, and the spherically,
$T_\mathrm{m_g}$, temperatures, and the spherically, 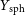 $Y_\mathrm{sph}$, and cylindrically,
$Y_\mathrm{sph}$, and cylindrically, 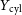 $Y_\mathrm{cyl}$, integrated Compton parameters. Over a parameter space of clusters, we constrain the X-ray temperature scaling relations,
$Y_\mathrm{cyl}$, integrated Compton parameters. Over a parameter space of clusters, we constrain the X-ray temperature scaling relations, 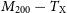 $M_{200} - T_\mathrm{X}$ and
$M_{200} - T_\mathrm{X}$ and 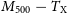 $M_{500} - T_\mathrm{X}$, within
$M_{500} - T_\mathrm{X}$, within 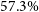 $57.3\%$ and
$57.3\%$ and 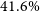 $41.6\%$, and
$41.6\%$, and 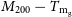 $M_{200} - T_\mathrm{m_g}$ and
$M_{200} - T_\mathrm{m_g}$ and 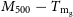 $M_{500} - T_\mathrm{m_g}$, within
$M_{500} - T_\mathrm{m_g}$, within 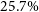 $25.7\%$ and
$25.7\%$ and 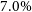 $7.0\%$, all respectively. When excising the cluster’s core, the
$7.0\%$, all respectively. When excising the cluster’s core, the 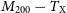 $M_{200} - T_\mathrm{X}$ and
$M_{200} - T_\mathrm{X}$ and 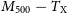 $M_{500} - T_\mathrm{X}$ relations are further constrained, to within
$M_{500} - T_\mathrm{X}$ relations are further constrained, to within 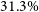 $31.3\%$ and
$31.3\%$ and 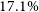 $17.1\%$, respectively. Similarly, we constrain the SZ scaling relations,
$17.1\%$, respectively. Similarly, we constrain the SZ scaling relations, 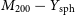 $M_{200} - Y_\mathrm{sph}$ and
$M_{200} - Y_\mathrm{sph}$ and 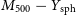 $M_{500} - Y_\mathrm{sph}$, within
$M_{500} - Y_\mathrm{sph}$, within 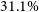 $31.1\%$ and
$31.1\%$ and 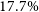 $17.7\%$, and
$17.7\%$, and 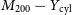 $M_{200} - Y_\mathrm{cyl}$ and
$M_{200} - Y_\mathrm{cyl}$ and 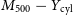 $M_{500} - Y_\mathrm{cyl}$, within
$M_{500} - Y_\mathrm{cyl}$, within 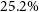 $25.2\%$ and
$25.2\%$ and 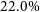 $22.0\%$, all respectively. The temperature observable
$22.0\%$, all respectively. The temperature observable 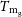 $T_\mathrm{m_g}$ places the strongest constraint on the halo mass, whilst
$T_\mathrm{m_g}$ places the strongest constraint on the halo mass, whilst 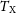 $T_\mathrm{X}$ is more sensitive to the parameter space. The SZ constraints are sensitive to the gas fraction, whilst insensitive to the form of the gas profile itself. In all cases, the halo mass is recovered with an uncertainty that suggests the cluster’s structural profiles only contribute a minor uncertainty in its scaling relations.
$T_\mathrm{X}$ is more sensitive to the parameter space. The SZ constraints are sensitive to the gas fraction, whilst insensitive to the form of the gas profile itself. In all cases, the halo mass is recovered with an uncertainty that suggests the cluster’s structural profiles only contribute a minor uncertainty in its scaling relations.


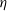
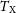
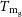
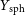
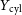
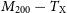
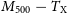
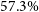
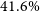
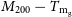
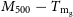
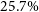
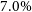
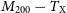
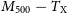
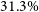
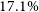
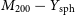
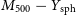
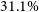
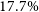
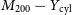
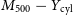
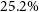
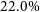
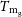
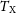
Re. I. Understanding galaxy sizes, associated luminosity densities, and the artificial division of the early-type galaxy population – CORRIGENDUM
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 25 March 2024, e015
-
- Article
-
- You have access
- HTML
- Export citation
Fast as Potoroo: Radio continuum detection of a bow-shock pulsar wind nebula powered by pulsar J1638–4713
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 25 March 2024, e032
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We report the discovery of a bow-shock pulsar wind nebula (PWN), named Potoroo, and the detection of a young pulsar J1638
 $-$4713 that powers the nebula. We present a radio continuum study of the PWN based on 20-cm observations obtained from the Australian Square Kilometre Array Pathfinder (ASKAP) and MeerKAT. PSR J1638
$-$4713 that powers the nebula. We present a radio continuum study of the PWN based on 20-cm observations obtained from the Australian Square Kilometre Array Pathfinder (ASKAP) and MeerKAT. PSR J1638 $-$4713 was identified using Parkes radio telescope observations at frequencies above 3 GHz. The pulsar has the second-highest dispersion measure of all known radio pulsars (1 553 pc cm
$-$4713 was identified using Parkes radio telescope observations at frequencies above 3 GHz. The pulsar has the second-highest dispersion measure of all known radio pulsars (1 553 pc cm $^{-3}$), a spin period of 65.74 ms and a spin-down luminosity of
$^{-3}$), a spin period of 65.74 ms and a spin-down luminosity of 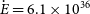 $\dot{E}=6.1\times10^{36}$ erg s
$\dot{E}=6.1\times10^{36}$ erg s $^{-1}$. The PWN has a cometary morphology and one of the greatest projected lengths among all the observed pulsar radio tails, measuring over 21 pc for an assumed distance of 10 kpc. The remarkably long tail and atypically steep radio spectral index are attributed to the interplay of a supernova reverse shock and the PWN. The originating supernova remnant is not known so far. We estimated the pulsar kick velocity to be in the range of 1 000–2 000 km s
$^{-1}$. The PWN has a cometary morphology and one of the greatest projected lengths among all the observed pulsar radio tails, measuring over 21 pc for an assumed distance of 10 kpc. The remarkably long tail and atypically steep radio spectral index are attributed to the interplay of a supernova reverse shock and the PWN. The originating supernova remnant is not known so far. We estimated the pulsar kick velocity to be in the range of 1 000–2 000 km s $^{-1}$ for ages between 23 and 10 kyr. The X-ray counterpart found in Chandra data, CXOU J163802.6
$^{-1}$ for ages between 23 and 10 kyr. The X-ray counterpart found in Chandra data, CXOU J163802.6 $-$471358, shows the same tail morphology as the radio source but is shorter by a factor of 10. The peak of the X-ray emission is offset from the peak of the radio total intensity (Stokes
$-$471358, shows the same tail morphology as the radio source but is shorter by a factor of 10. The peak of the X-ray emission is offset from the peak of the radio total intensity (Stokes 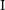 $\rm I$) emission by approximately 4.7
$\rm I$) emission by approximately 4.7 $^{\prime\prime}$, but coincides well with circularly polarised (Stokes
$^{\prime\prime}$, but coincides well with circularly polarised (Stokes 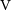 $\rm V$) emission. No infrared counterpart was found.
$\rm V$) emission. No infrared counterpart was found.






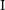

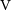
Galaxy spin direction asymmetry in JWST deep fields
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 25 March 2024, e038
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The unprecedented imaging power of James Webb Space Telescope (JWST) provides new abilities to observe the shapes of objects in the early Universe in a way that has not been possible before. Recently, JWST acquired a deep field image inside the same field imaged in the past as the Hubble Space Telescope (HST) Ultra Deep Field. Computer-based quantitative analysis of spiral galaxies in that field shows that among 34 galaxies for which their rotation of direction can be determined by the shapes of the arms, 24 rotate clockwise, and just 10 rotate counterclockwise. The one-tailed binomial distribution probability to have asymmetry equal or stronger than the observed asymmetry by chance is
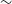 $\sim$0.012. While the analysis is limited by the small size of the data, the observed asymmetry is aligned with all relevant previous large-scale analyses from all premier digital sky surveys, all show a higher number of galaxies rotating clockwise in that part of the sky, and the magnitude of the asymmetry increases as the redshift gets higher. This paper also provides data and analysis to reproduce previous experiments suggesting that the distribution of galaxy rotation in the Universe is random, to show that the exact same data used in these studies in fact show non-random distribution, and in excellent agreement with the results shown here. These findings reinforce consideration of the possibility that the directions of rotation of spiral galaxies as observed from Earth are not necessarily randomly distributed. The explanation can be related to the large-scale structure of the Universe, but can also be related to a possible anomaly in the physics of galaxy rotation.
$\sim$0.012. While the analysis is limited by the small size of the data, the observed asymmetry is aligned with all relevant previous large-scale analyses from all premier digital sky surveys, all show a higher number of galaxies rotating clockwise in that part of the sky, and the magnitude of the asymmetry increases as the redshift gets higher. This paper also provides data and analysis to reproduce previous experiments suggesting that the distribution of galaxy rotation in the Universe is random, to show that the exact same data used in these studies in fact show non-random distribution, and in excellent agreement with the results shown here. These findings reinforce consideration of the possibility that the directions of rotation of spiral galaxies as observed from Earth are not necessarily randomly distributed. The explanation can be related to the large-scale structure of the Universe, but can also be related to a possible anomaly in the physics of galaxy rotation.
Angular momentum and energy transport in disc–jet systems: Unravelling the contribution of saturated thermal conduction
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 21 March 2024, e023
-
- Article
- Export citation
-
This study builds upon our prior work to further explore and unravel the effects of saturated thermal conduction within a viscous resistive MHD framework on the intricate transport mechanisms of angular momentum and energy in disc-jet systems. We conducted a series of 2.5-dimensional non-relativistic time-dependent numerical simulations using the PLUTO code. Employing a saturation parameter spanning [0.002-0.01], our results are consistent with previous investigations that omitted consideration of thermal conduction, affirming the established understanding that kinetic torque plays a predominant role in governing the total accretion angular momentum, surpassing the magnetic contribution within the disc. At the initial time steps of our calculations, we find that thermal conduction enhances this kinetic contribution, while concurrently diminishing the effect of magnetic contribution. In contrast to the prevailing influence of kinetic torque within the disc, we also assert the magnetic torque as the primary contributor to the total ejection angular momentum. We further unveil that doubling the saturation parameter leads to bolstering of approximately
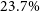 $23.7\%$ in the integral dominance of magnetic torque compared to kinetic torque within the jet. Our findings reveal that doubling the effect of thermal conduction improves the integral total accretion power by approximately 2%, thereby slightly amplifying the energy content within the system and increasing overall energy output. We underscore that as the local energy dissipation within the disc intensifies, the significance of the enthalpy accretion flux increases at the expense of the jet power. We reveal that increasing the saturation parameter mitigates enthalpy accumulation within the disc, and further restricts the jet’s energy extraction from the disc. This limitation is determined in our analysis through the decrease in the integral ratio between the bipolar jet and liberated power of approximately
$23.7\%$ in the integral dominance of magnetic torque compared to kinetic torque within the jet. Our findings reveal that doubling the effect of thermal conduction improves the integral total accretion power by approximately 2%, thereby slightly amplifying the energy content within the system and increasing overall energy output. We underscore that as the local energy dissipation within the disc intensifies, the significance of the enthalpy accretion flux increases at the expense of the jet power. We reveal that increasing the saturation parameter mitigates enthalpy accumulation within the disc, and further restricts the jet’s energy extraction from the disc. This limitation is determined in our analysis through the decrease in the integral ratio between the bipolar jet and liberated power of approximately 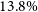 $13.8\%$, for twice the strength of the saturation parameter. We identify the Poynting flux as the primary contributor to total jet power, with thermal conduction exerting minimal influence on magnetic contributions. Additionally, we emphasise the integration of jet enthalpy as another significant factor in determining overall jet power, highlighting a distinct correlation between the rise in saturation parameter and heightened enthalpy contribution. Moreover, we observe the promotion of Poynting flux over kinetic flux at advanced time steps of our simulations, a trend supported by the presence of thermal conduction, which demonstrates an integral increase of approximately
$13.8\%$, for twice the strength of the saturation parameter. We identify the Poynting flux as the primary contributor to total jet power, with thermal conduction exerting minimal influence on magnetic contributions. Additionally, we emphasise the integration of jet enthalpy as another significant factor in determining overall jet power, highlighting a distinct correlation between the rise in saturation parameter and heightened enthalpy contribution. Moreover, we observe the promotion of Poynting flux over kinetic flux at advanced time steps of our simulations, a trend supported by the presence of thermal conduction, which demonstrates an integral increase of approximately 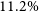 $11.2\%$ when considering a doubling of the saturation parameter.
$11.2\%$ when considering a doubling of the saturation parameter.