Refine search
Actions for selected content:
53194 results in Statistics and Probability
Chapter Three - Graphs and Networks
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 56-75
-
- Chapter
- Export citation
Chapter Eight - Models of Network Evolution and Growth
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 182-217
-
- Chapter
- Export citation
Chapter Seven - The Topology of Networks
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 161-181
-
- Chapter
- Export citation
References
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 441-474
-
- Chapter
- Export citation
Chapter Thirteen - Graph Partitioning: III. Spectral Clustering
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 346-361
-
- Chapter
- Export citation
Chapter One - Introduction and Preview
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 1-15
-
- Chapter
- Export citation
Chapter Seventeen - Dynamic Networks
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp 411-440
-
- Chapter
- Export citation
Reviews
-
- Book:
- Network Models for Data Science
- Published online:
- 22 March 2023
- Print publication:
- 05 January 2023, pp ii-ii
-
- Chapter
- Export citation
On some properties of distributions possessing a bathtub-shaped failure rate average
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 04 January 2023, pp. 693-708
- Print publication:
- June 2023
-
- Article
- Export citation
-
The life distribution of a device subject to shocks governed by a homogeneous Poisson process is shown to have a bathtub failure rate average (BFRA) when the probabilities
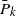 $\bar{P}_k$ of surviving k shocks possess the corresponding discrete property. We prove closure under the formation of weak limits for BFRA distributions and explore related moment convergence issues within the BFRA family. Similar results for increasing and decreasing failure rate average distributions are obtained either independently or as consequences of our results. We also establish some results outlining the positions of various non-monotonic ageing classes such as bathtub failure rate, increasing initially then decreasing mean residual life, new worse then better than used in expectation, and increasing initially then decreasing mean time to failure in the hierarchy. Finally, an open problem is posed and a partial solution provided.
$\bar{P}_k$ of surviving k shocks possess the corresponding discrete property. We prove closure under the formation of weak limits for BFRA distributions and explore related moment convergence issues within the BFRA family. Similar results for increasing and decreasing failure rate average distributions are obtained either independently or as consequences of our results. We also establish some results outlining the positions of various non-monotonic ageing classes such as bathtub failure rate, increasing initially then decreasing mean residual life, new worse then better than used in expectation, and increasing initially then decreasing mean time to failure in the hierarchy. Finally, an open problem is posed and a partial solution provided.
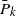
Analysis of a non-reversible Markov chain speedup by a single edge
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 04 January 2023, pp. 642-660
- Print publication:
- June 2023
-
- Article
- Export citation
-
We present a Markov chain example where non-reversibility and an added edge jointly improve mixing time. When a random edge is added to a cycle of n vertices and a Markov chain with a drift is introduced, we get a mixing time of
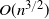 $O(n^{3/2})$ with probability bounded away from 0. If only one of the two modifications were performed, the mixing time would stay
$O(n^{3/2})$ with probability bounded away from 0. If only one of the two modifications were performed, the mixing time would stay 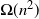 $\Omega(n^2)$.
$\Omega(n^2)$.
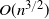
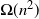
Associations between reported post-COVID-19 symptoms and subjective well-being, Israel, July 2021 – April 2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 04 January 2023, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distributionally robust reinsurance with expectile
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 16 February 2023, pp. 129-148
- Print publication:
- January 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal consumption, investment, and insurance under state-dependent risk aversion
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 23 January 2023, pp. 104-128
- Print publication:
- January 2023
-
- Article
- Export citation
Target benefit pension plan with longevity risk and intergenerational equity
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 12 January 2023, pp. 84-103
- Print publication:
- January 2023
-
- Article
- Export citation
ASB volume 53 issue 1 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 06 March 2023, pp. f1-f2
- Print publication:
- January 2023
-
- Article
-
- You have access
- Export citation
ASB volume 53 issue 1 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 06 March 2023, pp. b1-b4
- Print publication:
- January 2023
-
- Article
-
- You have access
- Export citation
Portfolio performance under benchmarking relative loss and portfolio insurance: From omega ratio to loss aversion
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 16 January 2023, pp. 149-183
- Print publication:
- January 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotics of a time bounded cylinder model
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 27 December 2022, pp. 1063-1083
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
One way to model telecommunication networks are static Boolean models. However, dynamics such as node mobility have a significant impact on the performance evaluation of such networks. Consider a Boolean model in
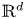 $\mathbb {R}^d$ and a random direction movement scheme. Given a fixed time horizon
$\mathbb {R}^d$ and a random direction movement scheme. Given a fixed time horizon 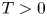 $T>0$, we model these movements via cylinders in
$T>0$, we model these movements via cylinders in 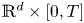 $\mathbb {R}^d \times [0,T]$. In this work, we derive central limit theorems for functionals of the union of these cylinders. The volume and the number of isolated cylinders and the Euler characteristic of the random set are considered and give an answer to the achievable throughput, the availability of nodes, and the topological structure of the network.
$\mathbb {R}^d \times [0,T]$. In this work, we derive central limit theorems for functionals of the union of these cylinders. The volume and the number of isolated cylinders and the Euler characteristic of the random set are considered and give an answer to the achievable throughput, the availability of nodes, and the topological structure of the network.
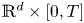
Risk factors for Leptospira seropositivity in rural Northern Germany, 2019
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 December 2022, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Valuation of vulnerable European options with market liquidity risk
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 27 December 2022, pp. 65-81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
