Refine search
Actions for selected content:
53194 results in Statistics and Probability
An outbreak of hepatitis A virus infection in a secondary school in England with no undetected asymptomatic transmission among students
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 11 December 2022, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On extremes of random clusters and marked renewal cluster processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 09 December 2022, pp. 367-381
- Print publication:
- June 2023
-
- Article
- Export citation
-
This article describes the limiting distribution of the extremes of observations that arrive in clusters. We start by studying the tail behaviour of an individual cluster, and then we apply the developed theory to determine the limiting distribution of
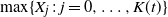 $\max\{X_j\,:\, j=0,\ldots, K(t)\}$, where K(t) is the number of independent and identically distributed observations
$\max\{X_j\,:\, j=0,\ldots, K(t)\}$, where K(t) is the number of independent and identically distributed observations 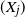 $(X_j)$ arriving up to the time t according to a general marked renewal cluster process. The results are illustrated in the context of some commonly used Poisson cluster models such as the marked Hawkes process.
$(X_j)$ arriving up to the time t according to a general marked renewal cluster process. The results are illustrated in the context of some commonly used Poisson cluster models such as the marked Hawkes process.
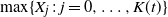
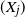
A bipartite version of the Erdős–McKay conjecture
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 09 December 2022, pp. 465-477
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
An old conjecture of Erdős and McKay states that if all homogeneous sets in an
 $n$-vertex graph are of order
$n$-vertex graph are of order 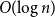 $O(\!\log n)$ then the graph contains induced subgraphs of each size from
$O(\!\log n)$ then the graph contains induced subgraphs of each size from 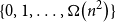 $\{0,1,\ldots, \Omega \big(n^2\big)\}$. We prove a bipartite analogue of the conjecture: if all balanced homogeneous sets in an
$\{0,1,\ldots, \Omega \big(n^2\big)\}$. We prove a bipartite analogue of the conjecture: if all balanced homogeneous sets in an 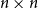 $n \times n$ bipartite graph are of order
$n \times n$ bipartite graph are of order 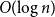 $O(\!\log n)$, then the graph contains induced subgraphs of each size from
$O(\!\log n)$, then the graph contains induced subgraphs of each size from 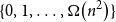 $\{0,1,\ldots, \Omega \big(n^2\big)\}$.
$\{0,1,\ldots, \Omega \big(n^2\big)\}$.

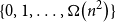
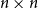
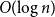
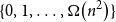
The frequency and content of televised UK gambling advertising during the men’s 2020 Euro soccer tournament
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 09 December 2022, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Portfolio management under drawdown constraint in discrete-time financial markets
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 09 December 2022, pp. 127-147
- Print publication:
- March 2023
-
- Article
- Export citation
On the splitting and aggregating of Hawkes processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 09 December 2022, pp. 676-692
- Print publication:
- June 2023
-
- Article
- Export citation
Fluctuations of subgraph counts in graphon based random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 09 December 2022, pp. 428-464
-
- Article
- Export citation
-
Given a graphon
 $W$ and a finite simple graph
$W$ and a finite simple graph 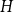 $H$, with vertex set
$H$, with vertex set 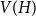 $V(H)$, denote by
$V(H)$, denote by 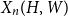 $X_n(H, W)$ the number of copies of
$X_n(H, W)$ the number of copies of 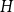 $H$ in a
$H$ in a 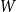 $W$-random graph on
$W$-random graph on  $n$ vertices. The asymptotic distribution of
$n$ vertices. The asymptotic distribution of 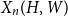 $X_n(H, W)$ was recently obtained by Hladký, Pelekis, and Šileikis [17] in the case where
$X_n(H, W)$ was recently obtained by Hladký, Pelekis, and Šileikis [17] in the case where 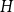 $H$ is a clique. In this paper, we extend this result to any fixed graph
$H$ is a clique. In this paper, we extend this result to any fixed graph 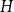 $H$. Towards this we introduce a notion of
$H$. Towards this we introduce a notion of 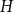 $H$-regularity of graphons and show that if the graphon
$H$-regularity of graphons and show that if the graphon 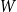 $W$ is not
$W$ is not 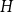 $H$-regular, then
$H$-regular, then 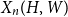 $X_n(H, W)$ has Gaussian fluctuations with scaling
$X_n(H, W)$ has Gaussian fluctuations with scaling 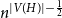 $n^{|V(H)|-\frac{1}{2}}$. On the other hand, if
$n^{|V(H)|-\frac{1}{2}}$. On the other hand, if 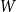 $W$ is
$W$ is 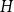 $H$-regular, then the fluctuations are of order
$H$-regular, then the fluctuations are of order 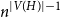 $n^{|V(H)|-1}$ and the limiting distribution of
$n^{|V(H)|-1}$ and the limiting distribution of 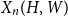 $X_n(H, W)$ can have both Gaussian and non-Gaussian components, where the non-Gaussian component is a (possibly) infinite weighted sum of centred chi-squared random variables with the weights determined by the spectral properties of a graphon derived from
$X_n(H, W)$ can have both Gaussian and non-Gaussian components, where the non-Gaussian component is a (possibly) infinite weighted sum of centred chi-squared random variables with the weights determined by the spectral properties of a graphon derived from 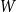 $W$. Our proofs use the asymptotic theory of generalised
$W$. Our proofs use the asymptotic theory of generalised 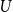 $U$-statistics developed by Janson and Nowicki [22]. We also investigate the structure of
$U$-statistics developed by Janson and Nowicki [22]. We also investigate the structure of 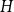 $H$-regular graphons for which either the Gaussian or the non-Gaussian component of the limiting distribution (but not both) is degenerate. Interestingly, there are also
$H$-regular graphons for which either the Gaussian or the non-Gaussian component of the limiting distribution (but not both) is degenerate. Interestingly, there are also 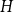 $H$-regular graphons
$H$-regular graphons 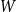 $W$ for which both the Gaussian or the non-Gaussian components are degenerate, that is,
$W$ for which both the Gaussian or the non-Gaussian components are degenerate, that is, 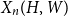 $X_n(H, W)$ has a degenerate limit even under the scaling
$X_n(H, W)$ has a degenerate limit even under the scaling 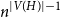 $n^{|V(H)|-1}$. We give an example of this degeneracy with
$n^{|V(H)|-1}$. We give an example of this degeneracy with 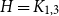 $H=K_{1, 3}$ (the 3-star) and also establish non-degeneracy in a few examples. This naturally leads to interesting open questions on higher order degeneracies.
$H=K_{1, 3}$ (the 3-star) and also establish non-degeneracy in a few examples. This naturally leads to interesting open questions on higher order degeneracies.
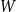
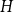
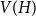
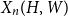
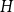
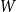

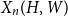
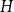
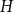
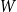
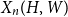
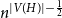
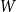
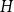
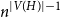
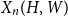
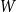
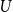
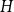
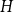
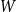
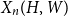
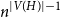
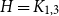
5 - Sex and the Single Patient
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 97-120
-
- Chapter
- Export citation
Dedication
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp v-v
-
- Chapter
- Export citation
2 - The Diceman Cometh
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 28-53
-
- Chapter
- Export citation
7 - Time’s Tables
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 135-156
-
- Chapter
- Export citation
Index
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 317-322
-
- Chapter
- Export citation
10 - The Law Is a Ass
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 206-233
-
- Chapter
- Export citation
1 - Circling the Square
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 1-27
-
- Chapter
-
- You have access
- HTML
- Export citation
6 - A Hale View of Pills (and Other Matters)
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 121-134
-
- Chapter
- Export citation
Contents
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp vii-viii
-
- Chapter
- Export citation
Epigraph
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp vi-vi
-
- Chapter
- Export citation
4 - Of Dice and Men*
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 74-96
-
- Chapter
- Export citation
Preface to the First Edition
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp xiii-xv
-
- Chapter
- Export citation
Preface to the Second Edition
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp ix-xii
-
- Chapter
- Export citation
