Refine search
Actions for selected content:
53194 results in Statistics and Probability
Notes
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 297-316
-
- Chapter
- Export citation
Permissions
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp xvi-xvi
-
- Chapter
- Export citation
12 - Going Viral
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 255-296
-
- Chapter
- Export citation
3 - Trials of Life
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 54-73
-
- Chapter
- Export citation
8 - A Dip in the Pool
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 157-177
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp iv-iv
-
- Chapter
- Export citation
11 - The Empire of the Sum
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 234-254
-
- Chapter
- Export citation
9 - The Things that Bug Us*
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 178-205
-
- Chapter
- Export citation
Relative contribution of essential and non-essential activities to SARS-CoV-2 transmission following the lifting of public health restrictions in England and Wales
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 07 December 2022, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On intersection probabilities of four lines inside a planar convex domain
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 07 December 2022, pp. 504-527
- Print publication:
- June 2023
-
- Article
- Export citation
-
Let
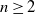 $n\geq 2$ random lines intersect a planar convex domain D. Consider the probabilities
$n\geq 2$ random lines intersect a planar convex domain D. Consider the probabilities 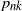 $p_{nk}$,
$p_{nk}$, 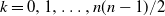 $k=0,1, \ldots, {n(n-1)}/{2}$ that the lines produce exactly k intersection points inside D. The objective is finding
$k=0,1, \ldots, {n(n-1)}/{2}$ that the lines produce exactly k intersection points inside D. The objective is finding 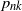 $p_{nk}$ through geometric invariants of D. Using Ambartzumian’s combinatorial algorithm, the known results are instantly reestablished for
$p_{nk}$ through geometric invariants of D. Using Ambartzumian’s combinatorial algorithm, the known results are instantly reestablished for 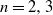 $n=2, 3$. When
$n=2, 3$. When 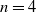 $n=4$, these probabilities are expressed by new invariants of D. When D is a disc of radius r, the simplest forms of all invariants are found. The exact values of
$n=4$, these probabilities are expressed by new invariants of D. When D is a disc of radius r, the simplest forms of all invariants are found. The exact values of 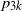 $p_{3k}$ and
$p_{3k}$ and 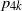 $p_{4k}$ are established.
$p_{4k}$ are established.
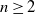
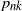
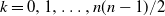
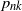
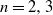
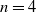
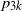
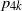
LARGE SAMPLE JUSTIFICATIONS FOR THE BAYESIAN EMPIRICAL LIKELIHOOD
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 05 December 2022, pp. 926-956
-
- Article
- Export citation
COVID-19 isolation/quarantine rules in home care patients
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 05 December 2022, e206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A scoping review of the distribution and frequency of extended-spectrum β-lactamase (ESBL)-producing Enterobacteriaceae in shrimp and salmon
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 05 December 2022, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can we trust trust-based data governance models?
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 05 December 2022, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WEAK CONVERGENCE TO DERIVATIVES OF FRACTIONAL BROWNIAN MOTION
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 05 December 2022, pp. 859-874
-
- Article
- Export citation
-
It is well known that, under suitable regularity conditions, the normalized fractional process with fractional parameter d converges weakly to fractional Brownian motion (fBm) for
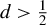 $d>\frac {1}{2}$. We show that, for any nonnegative integer M, derivatives of order
$d>\frac {1}{2}$. We show that, for any nonnegative integer M, derivatives of order 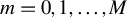 $m=0,1,\dots ,M$ of the normalized fractional process with respect to the fractional parameter d jointly converge weakly to the corresponding derivatives of fBm. As an illustration, we apply the results to the asymptotic distribution of the score vectors in the multifractional vector autoregressive model.
$m=0,1,\dots ,M$ of the normalized fractional process with respect to the fractional parameter d jointly converge weakly to the corresponding derivatives of fBm. As an illustration, we apply the results to the asymptotic distribution of the score vectors in the multifractional vector autoregressive model.
TESTING A CLASS OF SEMI- OR NONPARAMETRIC CONDITIONAL MOMENT RESTRICTION MODELS USING SERIES METHODS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 05 December 2022, pp. 827-858
-
- Article
- Export citation
Quantum computing for data-centric engineering and science
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 02 December 2022, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On mixed fractional stochastic differential equations with discontinuous drift coefficient
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 December 2022, pp. 589-606
- Print publication:
- June 2023
-
- Article
- Export citation
Exponential ergodicity for a class of Markov processes with interactions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 December 2022, pp. 465-478
- Print publication:
- June 2023
-
- Article
- Export citation
A defined benefit pension plan model with stochastic salary and heterogeneous discounting
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 01 December 2022, pp. 62-83
- Print publication:
- January 2023
-
- Article
- Export citation
