Refine search
Actions for selected content:
53194 results in Statistics and Probability
An approach for system analysis with model-based systems engineering and graph data engineering
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Migration data collection and management in a changing Latin American landscape
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Govtech against corruption: What are the integrity dividends of government digitalization?
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predicting politicians’ misconduct: Evidence from Colombia
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 14 November 2022, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk factors for SARS-CoV-2 infection in healthcare workers following an identified nosocomial COVID-19 exposure during waves 1–3 of the pandemic in Ireland
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 13 November 2022, e186
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Characterisation of burden of illness measures associated with human (Fluoro)quinolone-resistant Campylobacter spp. infections – a scoping review
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 11 November 2022, e205
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An elementary approach to component sizes in critical random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 11 November 2022, pp. 1228-1242
- Print publication:
- December 2022
-
- Article
- Export citation
Ruin probabilities in a Markovian shot-noise environment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 11 November 2022, pp. 542-556
- Print publication:
- June 2023
-
- Article
- Export citation
Asymptotic behavior and quasi-limiting distributions on time-fractional birth and death processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 11 November 2022, pp. 1199-1227
- Print publication:
- December 2022
-
- Article
- Export citation
-
In this article we provide new results for the asymptotic behavior of a time-fractional birth and death process
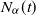 $N_{\alpha}(t)$, whose transition probabilities
$N_{\alpha}(t)$, whose transition probabilities 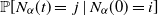 $\mathbb{P}[N_{\alpha}(t)=\,j\mid N_{\alpha}(0)=i]$ are governed by a time-fractional system of differential equations, under the condition that it is not killed. More specifically, we prove that the concepts of quasi-limiting distribution and quasi-stationary distribution do not coincide, which is a consequence of the long-memory nature of the process. In addition, exact formulas for the quasi-limiting distribution and its rate convergence are presented. In the first sections, we revisit the two equivalent characterizations for this process: the first one is a time-changed classic birth and death process, whereas the second one is a Markov renewal process. Finally, we apply our main theorems to the linear model originally introduced by Orsingher and Polito [23].
$\mathbb{P}[N_{\alpha}(t)=\,j\mid N_{\alpha}(0)=i]$ are governed by a time-fractional system of differential equations, under the condition that it is not killed. More specifically, we prove that the concepts of quasi-limiting distribution and quasi-stationary distribution do not coincide, which is a consequence of the long-memory nature of the process. In addition, exact formulas for the quasi-limiting distribution and its rate convergence are presented. In the first sections, we revisit the two equivalent characterizations for this process: the first one is a time-changed classic birth and death process, whereas the second one is a Markov renewal process. Finally, we apply our main theorems to the linear model originally introduced by Orsingher and Polito [23].
Resolving an open problem on the hazard rate ordering of p-spacings
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 11 November 2022, pp. 1020-1028
-
- Article
- Export citation
-
Let
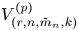 $V_{(r,n,\tilde {m}_n,k)}^{(p)}$ and
$V_{(r,n,\tilde {m}_n,k)}^{(p)}$ and 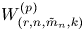 $W_{(r,n,\tilde {m}_n,k)}^{(p)}$ be the
$W_{(r,n,\tilde {m}_n,k)}^{(p)}$ be the 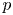 $p$-spacings of generalized order statistics based on absolutely continuous distribution functions
$p$-spacings of generalized order statistics based on absolutely continuous distribution functions 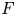 $F$ and
$F$ and 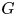 $G$, respectively. Imposing some conditions on
$G$, respectively. Imposing some conditions on 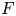 $F$ and
$F$ and 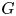 $G$ and assuming that
$G$ and assuming that 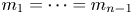 $m_1=\cdots =m_{n-1}$, Hu and Zhuang (2006. Stochastic orderings between p-spacings of generalized order statistics from two samples. Probability in the Engineering and Informational Sciences 20: 475) established
$m_1=\cdots =m_{n-1}$, Hu and Zhuang (2006. Stochastic orderings between p-spacings of generalized order statistics from two samples. Probability in the Engineering and Informational Sciences 20: 475) established 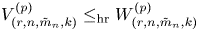 $V_{(r,n,\tilde {m}_n,k)}^{(p)} \leq _{{\rm hr}} W_{(r,n,\tilde {m}_n,k)}^{(p)}$ for
$V_{(r,n,\tilde {m}_n,k)}^{(p)} \leq _{{\rm hr}} W_{(r,n,\tilde {m}_n,k)}^{(p)}$ for 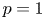 $p=1$ and left the case
$p=1$ and left the case 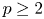 $p\geq 2$ as an open problem. In this article, we not only resolve it but also give the result for unequal
$p\geq 2$ as an open problem. In this article, we not only resolve it but also give the result for unequal 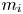 $m_i$'s. It is worth mentioning that this problem has not been proved even for ordinary order statistics so far.
$m_i$'s. It is worth mentioning that this problem has not been proved even for ordinary order statistics so far.
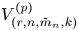
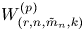
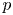
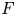
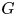
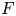
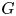
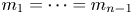
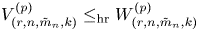
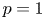
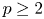
Strong couplings for static locally tree-like random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 11 November 2022, pp. 1261-1285
- Print publication:
- December 2022
-
- Article
- Export citation
JPR volume 59 issue 4 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 11 November 2022, pp. f1-f2
- Print publication:
- December 2022
-
- Article
-
- You have access
- Export citation
JPR volume 59 issue 4 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 11 November 2022, pp. b1-b2
- Print publication:
- December 2022
-
- Article
-
- You have access
- Export citation
A JACKKNIFE LAGRANGE MULTIPLIER TEST WITH MANY WEAK INSTRUMENTS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 11 November 2022, pp. 447-470
-
- Article
- Export citation
John’s walk
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 10 November 2022, pp. 473-491
- Print publication:
- June 2023
-
- Article
- Export citation
-
We present an affine-invariant random walk for drawing uniform random samples from a convex body
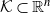 $\mathcal{K} \subset \mathbb{R}^n$ that uses maximum-volume inscribed ellipsoids, known as John’s ellipsoids, for the proposal distribution. Our algorithm makes steps using uniform sampling from the John’s ellipsoid of the symmetrization of
$\mathcal{K} \subset \mathbb{R}^n$ that uses maximum-volume inscribed ellipsoids, known as John’s ellipsoids, for the proposal distribution. Our algorithm makes steps using uniform sampling from the John’s ellipsoid of the symmetrization of 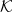 $\mathcal{K}$ at the current point. We show that from a warm start, the random walk mixes in
$\mathcal{K}$ at the current point. We show that from a warm start, the random walk mixes in 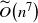 ${\widetilde{O}}\!\left(n^7\right)$ steps, where the log factors hidden in the
${\widetilde{O}}\!\left(n^7\right)$ steps, where the log factors hidden in the 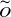 ${\widetilde{O}}$ depend only on constants associated with the warm start and desired total variation distance to uniformity. We also prove polynomial mixing bounds starting from any fixed point x such that for any chord pq of
${\widetilde{O}}$ depend only on constants associated with the warm start and desired total variation distance to uniformity. We also prove polynomial mixing bounds starting from any fixed point x such that for any chord pq of 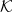 $\mathcal{K}$ containing x,
$\mathcal{K}$ containing x, 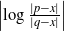 $\left|\log \frac{|p-x|}{|q-x|}\right|$ is bounded above by a polynomial in n.
$\left|\log \frac{|p-x|}{|q-x|}\right|$ is bounded above by a polynomial in n.
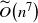
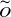
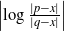
EXPONENTIAL REALIZED GARCH-ITÔ VOLATILITY MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 10 November 2022, pp. 790-826
-
- Article
- Export citation
Analyzing a single hyper-exponential working vacation queue from its governing difference equation
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 10 November 2022, pp. 997-1019
-
- Article
- Export citation
INSTRUMENTAL VARIABLES INFERENCE IN A SMALL-DIMENSIONAL VAR MODEL WITH DYNAMIC LATENT FACTORS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 10 November 2022, pp. 705-751
-
- Article
- Export citation
HIGHER-ORDER APPROXIMATION OF IV ESTIMATORS WITH INVALID INSTRUMENTS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 10 November 2022, pp. 752-789
-
- Article
- Export citation
-
This paper analyzes the higher-order approximation of instrumental variable (IV) estimators in a linear homoskedastic IV regression model when a large set of instruments with potential invalidity is present. We establish theoretical results on the higher-order mean-squared error (MSE) approximation of the two-stage least-squares (2SLS), the limited information maximum likelihood (LIML), the Fuller (FULL), the bias-adjusted 2SLS, and jackknife version of the LIML and FULL estimators by allowing for local violations of the instrument exogeneity conditions. Based on the approximation to the higher-order MSE, we consider the instrument selection criteria that can be used to choose among the set of available instruments. We demonstrate the asymptotic optimality of the instrument selection procedure proposed by Donald and Newey (2001, Econometrica 69, 1161–1191) in the presence of locally (faster than
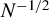 $N^{-1/2}$) invalid instruments in the sense that the dominant term in the MSE with the chosen instrument is asymptotically equivalent to the infeasible optimum. Furthermore, we propose instrument selection procedures to choose instruments among the sets of conservative (known) valid instruments and potentially locally (
$N^{-1/2}$) invalid instruments in the sense that the dominant term in the MSE with the chosen instrument is asymptotically equivalent to the infeasible optimum. Furthermore, we propose instrument selection procedures to choose instruments among the sets of conservative (known) valid instruments and potentially locally (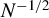 $N^{-1/2}$) invalid instruments based on the higher-order MSE of the IV estimators by considering the bias-variance trade-off.
$N^{-1/2}$) invalid instruments based on the higher-order MSE of the IV estimators by considering the bias-variance trade-off.
IFoA Presidential Address 2022: “Flourishing in Challenging Times: How the actuarial profession can grow, influence and lead in a rapidly changing world” by Matt Saker
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 09 November 2022, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
