Refine search
Actions for selected content:
53194 results in Statistics and Probability
Preceding anti-spike IgG levels predicted risk and severity of COVID-19 during the Omicron-dominant wave in Santa Fe city, Argentina
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 03 November 2022, e187
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Brownian bridge expansions for Lévy area approximations and particular values of the Riemann zeta function
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 03 November 2022, pp. 370-397
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association between physical activity status and severity of COVID-19 in older adults
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 03 November 2022, e189
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A class of non-zero-sum stochastic differential games between two mean–variance insurers under stochastic volatility
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 02 November 2022, pp. 491-517
-
- Article
- Export citation
Bayesian parameter inference for shallow subsurface modeling using field data and impacts on geothermal planning
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 02 November 2022, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Geographical distribution and space–time clustering of human illnesses with major Salmonella serotypes in Florida, USA, 2017–2018
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 31 October 2022, e175
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal design for network mutual aid
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 31 October 2022, pp. 567-596
-
- Article
-
- You have access
- HTML
- Export citation
An outbreak of Cryptosporidium parvum linked to pasteurised milk from a vending machine in England: a descriptive study, March 2021
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 28 October 2022, e185
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
REGULARIZED ESTIMATION OF DYNAMIC PANEL MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 28 October 2022, pp. 360-418
-
- Article
- Export citation
On stochastic ordering among extreme shock models
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 961-972
-
- Article
- Export citation
-
In the usual shock models, the shocks arrive from a single source. Bozbulut and Eryilmaz [(2020). Generalized extreme shock models and their applications. Communications in Statistics – Simulation and Computation 49(1): 110–120] introduced two types of extreme shock models when the shocks arrive from one of
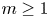 $m\geq 1$ possible sources. In Model 1, the shocks arrive from different sources over time. In Model 2, initially, the shocks randomly come from one of
$m\geq 1$ possible sources. In Model 1, the shocks arrive from different sources over time. In Model 2, initially, the shocks randomly come from one of 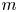 $m$ sources, and shocks continue to arrive from the same source. In this paper, we prove that the lifetime of Model 1 is less than Model 2 in the usual stochastic ordering. We further show that if the inter-arrival times of shocks have increasing failure rate distributions, then the usual stochastic ordering can be generalized to the hazard rate ordering. We study the stochastic behavior of the lifetime of Model 2 with respect to the severity of shocks using the notion of majorization. We apply the new stochastic ordering results to show that the age replacement policy under Model 1 is more costly than Model 2.
$m$ sources, and shocks continue to arrive from the same source. In this paper, we prove that the lifetime of Model 1 is less than Model 2 in the usual stochastic ordering. We further show that if the inter-arrival times of shocks have increasing failure rate distributions, then the usual stochastic ordering can be generalized to the hazard rate ordering. We study the stochastic behavior of the lifetime of Model 2 with respect to the severity of shocks using the notion of majorization. We apply the new stochastic ordering results to show that the age replacement policy under Model 1 is more costly than Model 2.
SUPERCONSISTENCY OF TESTS IN HIGH DIMENSIONS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 3 / June 2024
- Published online by Cambridge University Press:
- 28 October 2022, pp. 688-704
-
- Article
- Export citation
TESTING FOR STRICT STATIONARITY VIA THE DISCRETE FOURIER TRANSFORM
-
- Journal:
- Econometric Theory / Volume 40 / Issue 3 / June 2024
- Published online by Cambridge University Press:
- 28 October 2022, pp. 511-557
-
- Article
- Export citation
-
This paper proposes a model-free test for the strict stationarity of a potentially vector-valued time series using the discrete Fourier transform (DFT) approach. We show that the DFT of a residual process based on the empirical characteristic function weakly converges to a zero spectrum in the frequency domain for a strictly stationary time series and a nonzero spectrum otherwise. The proposed test is powerful against various types of nonstationarity including deterministic trends and smooth or abrupt structural changes. It does not require smoothed nonparametric estimation and, thus, can detect the Pitman sequence of local alternatives at the parametric rate
 $T^{-1/2}$, faster than all existing nonparametric tests. We also design a class of derivative tests based on the characteristic function to test the stationarity in various moments. Monte Carlo studies demonstrate that our test has reasonarble size and excellent power. Our empirical application of exchange rates strongly suggests that both nominal and real exchange rate returns are nonstationary, which the augmented Dickey–Fuller and Kwiatkowski–Phillips–Schmidt–Shin tests may overlook.
$T^{-1/2}$, faster than all existing nonparametric tests. We also design a class of derivative tests based on the characteristic function to test the stationarity in various moments. Monte Carlo studies demonstrate that our test has reasonarble size and excellent power. Our empirical application of exchange rates strongly suggests that both nominal and real exchange rate returns are nonstationary, which the augmented Dickey–Fuller and Kwiatkowski–Phillips–Schmidt–Shin tests may overlook.

TESTING FOR HOMOGENEOUS THRESHOLDS IN THRESHOLD REGRESSION MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 3 / June 2024
- Published online by Cambridge University Press:
- 28 October 2022, pp. 608-651
-
- Article
-
- You have access
- Open access
- Export citation
A negative binomial approximation in group testing
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 973-996
-
- Article
- Export citation
Spillover benefit of pre-exposure prophylaxis for HIV prevention: evaluating the importance of effect modification using an agent-based model
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 28 October 2022, e192
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A MOLLIFIER APPROACH TO THE DECONVOLUTION OF PROBABILITY DENSITIES
-
- Journal:
- Econometric Theory / Volume 40 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 28 October 2022, pp. 320-359
-
- Article
- Export citation
Bose–Einstein condensation for particles with repulsive short-range pair interactions in a Poisson random external potential in
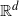 $\mathbb{R}^{d}$
$\mathbb{R}^{d}$
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 382-393
- Print publication:
- June 2023
-
- Article
- Export citation
-
We study Bose gases in
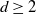 $d \ge 2$ dimensions with short-range repulsive pair interactions at positive temperature, in the canonical ensemble and in the thermodynamic limit. We assume the presence of hard Poissonian obstacles and focus on the non-percolation regime. For sufficiently strong interparticle interactions, we show that almost surely there cannot be Bose–Einstein condensation into a sufficiently localized, normalized one-particle state. The results apply to the canonical eigenstates of the underlying one-particle Hamiltonian.
$d \ge 2$ dimensions with short-range repulsive pair interactions at positive temperature, in the canonical ensemble and in the thermodynamic limit. We assume the presence of hard Poissonian obstacles and focus on the non-percolation regime. For sufficiently strong interparticle interactions, we show that almost surely there cannot be Bose–Einstein condensation into a sufficiently localized, normalized one-particle state. The results apply to the canonical eigenstates of the underlying one-particle Hamiltonian.
Prevalence and surveillance of tuberculosis in Yemen from 2006 to 2018 – ERRATUM
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 28 October 2022, e174
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Introduction
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 1-13
-
- Chapter
- Export citation
7 - Upper Bounds III: Sufficient Conditions
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 94-116
-
- Chapter
- Export citation
