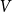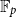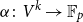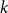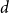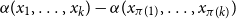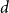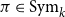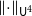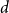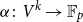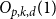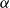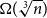Refine search
Actions for selected content:
53194 results in Statistics and Probability
10 - Examples
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 143-153
-
- Chapter
- Export citation
5 - Necessary Conditions: Bounds on the Rate Function, Invariant Measures, Irreducibility, and Recurrence
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 68-78
-
- Chapter
- Export citation
Preface
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp xi-xii
-
- Chapter
- Export citation
6 - Upper Bounds II: Equivalent Analytic Conditions
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 79-93
-
- Chapter
- Export citation
Subject Index
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 248-249
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp i-iv
-
- Chapter
- Export citation
Appendix D - Approximation of P by Pt
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 219-222
-
- Chapter
- Export citation
Incidence and predictors of Escherichia coli producing extended-spectrum beta-lactamase (ESBL-Ec) in Queensland, Australia from 2010 to 2019: a population-based spatial analysis
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 26 October 2022, e178
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prescribing for different antibiotic classes across age groups in the Kaiser Permanente Northern California population in association with influenza incidence, 2010–2018
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 26 October 2022, e180
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Impact of the COVID-19 pandemic on racial and ethnic minorities in Japan
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 26 October 2022, e202
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mistrust of government within authoritarian states hindering user acceptance and adoption of digital IDs in Africa: The Nigerian context
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 25 October 2022, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Foodborne illness outbreaks linked to unpasteurised milk and relationship to changes in state laws – United States, 1998–2018
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 25 October 2022, e183
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contesting border artificial intelligence: Applying the guidance-ethics approach as a responsible design lens
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 24 October 2022, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generalizations of forest fires with ignition at the origin
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 24 October 2022, pp. 418-434
- Print publication:
- June 2023
-
- Article
- Export citation
-
We study generalizations of the forest fire model introduced in [4] and [10] by allowing the rates at which the trees grow to depend on their location, introducing long-range burning, as well as a continuous-space generalization of the model. We establish that in all the models in consideration the expected time required to reach a site at distance x from the origin is of order
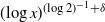 $(\!\log x)^{(\!\log2)^{-1}+\delta}$ for any
$(\!\log x)^{(\!\log2)^{-1}+\delta}$ for any 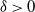 $\delta>0$.
$\delta>0$.
A note related to the CS decomposition and the BK inequality for discrete determinantal processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 24 October 2022, pp. 189-203
- Print publication:
- March 2023
-
- Article
- Export citation
SARS-CoV-2 seroepidemiology in paediatric population during Delta and Omicron predominance
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 19 October 2022, e177
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Guillain-Barré syndrome outbreak in Tapachula temporally associated with the Zika virus introduction in Southern Mexico
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 19 October 2022, e181
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Observing non-uniform, non-Lüders yielding in a cold-rolled medium manganese steel with digital image correlation
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 19 October 2022, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Socio-spatial aspects of creativity and their role in the planning and design of university campuses’ public spaces: A practitioners’ perspective
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 18 October 2022, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Approximately symmetric forms far from being exactly symmetric
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 18 October 2022, pp. 299-315
-
- Article
- Export citation
-
Let
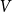 $V$ be a finite-dimensional vector space over
$V$ be a finite-dimensional vector space over 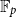 $\mathbb{F}_p$. We say that a multilinear form
$\mathbb{F}_p$. We say that a multilinear form 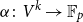 $\alpha \colon V^k \to \mathbb{F}_p$ in
$\alpha \colon V^k \to \mathbb{F}_p$ in 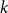 $k$ variables is
$k$ variables is 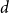 $d$-approximately symmetric if the partition rank of difference
$d$-approximately symmetric if the partition rank of difference 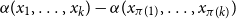 $\alpha (x_1, \ldots, x_k) - \alpha (x_{\pi (1)}, \ldots, x_{\pi (k)})$ is at most
$\alpha (x_1, \ldots, x_k) - \alpha (x_{\pi (1)}, \ldots, x_{\pi (k)})$ is at most 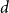 $d$ for every permutation
$d$ for every permutation 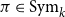 $\pi \in \textrm{Sym}_k$. In a work concerning the inverse theorem for the Gowers uniformity
$\pi \in \textrm{Sym}_k$. In a work concerning the inverse theorem for the Gowers uniformity 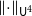 $\|\!\cdot\! \|_{\mathsf{U}^4}$ norm in the case of low characteristic, Tidor conjectured that any
$\|\!\cdot\! \|_{\mathsf{U}^4}$ norm in the case of low characteristic, Tidor conjectured that any 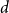 $d$-approximately symmetric multilinear form
$d$-approximately symmetric multilinear form 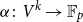 $\alpha \colon V^k \to \mathbb{F}_p$ differs from a symmetric multilinear form by a multilinear form of partition rank at most
$\alpha \colon V^k \to \mathbb{F}_p$ differs from a symmetric multilinear form by a multilinear form of partition rank at most 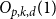 $O_{p,k,d}(1)$ and proved this conjecture in the case of trilinear forms. In this paper, somewhat surprisingly, we show that this conjecture is false. In fact, we show that approximately symmetric forms can be quite far from the symmetric ones, by constructing a multilinear form
$O_{p,k,d}(1)$ and proved this conjecture in the case of trilinear forms. In this paper, somewhat surprisingly, we show that this conjecture is false. In fact, we show that approximately symmetric forms can be quite far from the symmetric ones, by constructing a multilinear form 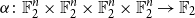 $\alpha \colon \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \to \mathbb{F}_2$ which is 3-approximately symmetric, while the difference between
$\alpha \colon \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \to \mathbb{F}_2$ which is 3-approximately symmetric, while the difference between 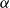 $\alpha$ and any symmetric multilinear form is of partition rank at least
$\alpha$ and any symmetric multilinear form is of partition rank at least 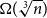 $\Omega (\sqrt [3]{n})$.
$\Omega (\sqrt [3]{n})$.