Refine search
Actions for selected content:
53194 results in Statistics and Probability
Critical branching as a pure death process coming down from infinity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 18 January 2023, pp. 607-628
- Print publication:
- June 2023
-
- Article
- Export citation
Use of portable air purifiers to reduce aerosols in hospital settings and cut down the clinical backlog
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 18 January 2023, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Parking functions: interdisciplinary connections
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 17 January 2023, pp. 768-792
- Print publication:
- September 2023
-
- Article
- Export citation
-
Suppose that m drivers each choose a preferred parking space in a linear car park with n spots. In order, each driver goes to their chosen spot and parks there if possible, and otherwise takes the next available spot if it exists. If all drivers park successfully, the sequence of choices is called a parking function. Classical parking functions correspond to the case
 $m=n$.
$m=n$.We investigate various probabilistic properties of a uniform parking function. Through a combinatorial construction termed a parking function multi-shuffle, we give a formula for the law of multiple coordinates in the generic situation
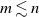 $m \lesssim n$. We further deduce all possible covariances: between two coordinates, between a coordinate and an unattempted spot, and between two unattempted spots. This asymptotic scenario in the generic situation
$m \lesssim n$. We further deduce all possible covariances: between two coordinates, between a coordinate and an unattempted spot, and between two unattempted spots. This asymptotic scenario in the generic situation 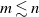 $m \lesssim n$ is in sharp contrast with that of the special situation
$m \lesssim n$ is in sharp contrast with that of the special situation  $m=n$.
$m=n$.A generalization of parking functions called interval parking functions is also studied, in which each driver is willing to park only in a fixed interval of spots. We construct a family of bijections between interval parking functions with n cars and n spots and edge-labeled spanning trees with
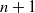 $n+1$ vertices and a specified root.
$n+1$ vertices and a specified root.

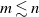

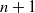
RELEVANT MOMENT SELECTION UNDER MIXED IDENTIFICATION STRENGTH
-
- Journal:
- Econometric Theory / Volume 40 / Issue 5 / October 2024
- Published online by Cambridge University Press:
- 16 January 2023, pp. 1003-1064
-
- Article
-
- You have access
- Open access
- Export citation
Predicting the last zero before an exponential time of a spectrally negative Lévy process
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 16 January 2023, pp. 611-642
- Print publication:
- June 2023
-
- Article
- Export citation
-
Given a spectrally negative Lévy process, we predict, in an
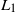 $L_1$ sense, the last passage time of the process below zero before an independent exponential time. This optimal prediction problem generalises [2], where the infinite-horizon problem is solved. Using a similar argument as that in [24], we show that this optimal prediction problem is equivalent to solving an optimal prediction problem in a finite-horizon setting. Surprisingly (unlike the infinite-horizon problem), an optimal stopping time is based on a curve that is killed at the moment the mean of the exponential time is reached. That is, an optimal stopping time is the first time the process crosses above a non-negative, continuous, and non-increasing curve depending on time. This curve and the value function are characterised as a solution of a system of nonlinear integral equations which can be understood as a generalisation of the free boundary equations (see e.g. [21, Chapter IV.14.1]) in the presence of jumps. As an example, we numerically calculate this curve in the Brownian motion case and for a compound Poisson process with exponential-sized jumps perturbed by a Brownian motion.
$L_1$ sense, the last passage time of the process below zero before an independent exponential time. This optimal prediction problem generalises [2], where the infinite-horizon problem is solved. Using a similar argument as that in [24], we show that this optimal prediction problem is equivalent to solving an optimal prediction problem in a finite-horizon setting. Surprisingly (unlike the infinite-horizon problem), an optimal stopping time is based on a curve that is killed at the moment the mean of the exponential time is reached. That is, an optimal stopping time is the first time the process crosses above a non-negative, continuous, and non-increasing curve depending on time. This curve and the value function are characterised as a solution of a system of nonlinear integral equations which can be understood as a generalisation of the free boundary equations (see e.g. [21, Chapter IV.14.1]) in the presence of jumps. As an example, we numerically calculate this curve in the Brownian motion case and for a compound Poisson process with exponential-sized jumps perturbed by a Brownian motion.
Response to COVID-19 in Lebanon: update, challenges and lessons learned
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 16 January 2023, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transition density of an infinite-dimensional diffusion with the jack parameter
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 16 January 2023, pp. 797-811
- Print publication:
- September 2023
-
- Article
- Export citation
Index
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 137-138
-
- Chapter
- Export citation
Glossary
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 131-131
-
- Chapter
- Export citation
Preface
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp xi-xii
-
- Chapter
- Export citation
4 - Averaging
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 41-58
-
- Chapter
- Export citation
5 - Covers and Embeddings
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 59-76
-
- Chapter
- Export citation
3 - Applications
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 20-40
-
- Chapter
- Export citation
References
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 132-136
-
- Chapter
- Export citation
Short-time behavior of solutions to Lévy-driven stochastic differential equations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 12 January 2023, pp. 765-780
- Print publication:
- September 2023
-
- Article
- Export citation
-
We consider solutions of Lévy-driven stochastic differential equations of the form
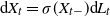 $\textrm{d} X_t=\sigma(X_{t-})\textrm{d} L_t$,
$\textrm{d} X_t=\sigma(X_{t-})\textrm{d} L_t$, 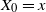 $X_0=x$, where the function
$X_0=x$, where the function  $\sigma$ is twice continuously differentiable and the driving Lévy process
$\sigma$ is twice continuously differentiable and the driving Lévy process 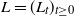 $L=(L_t)_{t\geq0}$ is either vector or matrix valued. While the almost sure short-time behavior of Lévy processes is well known and can be characterized in terms of the characteristic triplet, there is no complete characterization of the behavior of the solution X. Using methods from stochastic calculus, we derive limiting results for stochastic integrals of the form
$L=(L_t)_{t\geq0}$ is either vector or matrix valued. While the almost sure short-time behavior of Lévy processes is well known and can be characterized in terms of the characteristic triplet, there is no complete characterization of the behavior of the solution X. Using methods from stochastic calculus, we derive limiting results for stochastic integrals of the form 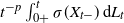 $t^{-p}\int_{0+}^t\sigma(X_{t-})\,\textrm{d} L_t$ to show that the behavior of the quantity
$t^{-p}\int_{0+}^t\sigma(X_{t-})\,\textrm{d} L_t$ to show that the behavior of the quantity 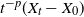 $t^{-p}(X_t-X_0)$ for
$t^{-p}(X_t-X_0)$ for 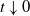 $t\downarrow0$ almost surely reflects the behavior of
$t\downarrow0$ almost surely reflects the behavior of 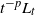 $t^{-p}L_t$. Generalizing
$t^{-p}L_t$. Generalizing 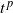 $t^{{\kern1pt}p}$ to a suitable function
$t^{{\kern1pt}p}$ to a suitable function 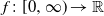 $f\colon[0,\infty)\rightarrow\mathbb{R}$ then yields a tool to derive explicit law of the iterated logarithm type results for the solution from the behavior of the driving Lévy process.
$f\colon[0,\infty)\rightarrow\mathbb{R}$ then yields a tool to derive explicit law of the iterated logarithm type results for the solution from the behavior of the driving Lévy process.
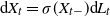
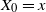

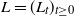
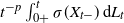
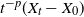
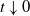
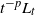
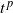
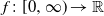
Invariant Galton–Watson trees: metric properties and attraction with respect to generalized dynamical pruning
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 12 January 2023, pp. 643-671
- Print publication:
- June 2023
-
- Article
- Export citation
7 - Shunts
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 98-120
-
- Chapter
- Export citation
8 - 1-Dimensional Walks
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 121-130
-
- Chapter
- Export citation
1 - Grover Search
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 1-10
-
- Chapter
-
- You have access
- Export citation
6 - Vertex-Face Walks
-
- Book:
- Discrete Quantum Walks on Graphs and Digraphs
- Published online:
- 23 December 2022
- Print publication:
- 12 January 2023, pp 77-97
-
- Chapter
- Export citation
