Refine search
Actions for selected content:
53194 results in Statistics and Probability
Poset Ramsey numbers: large Boolean lattice versus a fixed poset
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 17 February 2023, pp. 638-653
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given partially ordered sets (posets)
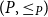 $(P, \leq _P\!)$ and
$(P, \leq _P\!)$ and 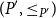 $(P^{\prime}, \leq _{P^{\prime}}\!)$, we say that
$(P^{\prime}, \leq _{P^{\prime}}\!)$, we say that 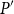 $P^{\prime}$ contains a copy of
$P^{\prime}$ contains a copy of 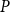 $P$ if for some injective function
$P$ if for some injective function 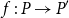 $f\,:\, P\rightarrow P^{\prime}$ and for any
$f\,:\, P\rightarrow P^{\prime}$ and for any 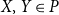 $X, Y\in P$,
$X, Y\in P$, 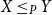 $X\leq _P Y$ if and only if
$X\leq _P Y$ if and only if 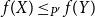 $f(X)\leq _{P^{\prime}} f(Y)$. For any posets
$f(X)\leq _{P^{\prime}} f(Y)$. For any posets 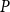 $P$ and
$P$ and 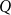 $Q$, the poset Ramsey number
$Q$, the poset Ramsey number 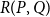 $R(P,Q)$ is the least positive integer
$R(P,Q)$ is the least positive integer 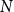 $N$ such that no matter how the elements of an
$N$ such that no matter how the elements of an 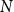 $N$-dimensional Boolean lattice are coloured in blue and red, there is either a copy of
$N$-dimensional Boolean lattice are coloured in blue and red, there is either a copy of 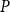 $P$ with all blue elements or a copy of
$P$ with all blue elements or a copy of 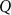 $Q$ with all red elements. We focus on a poset Ramsey number
$Q$ with all red elements. We focus on a poset Ramsey number 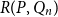 $R(P, Q_n)$ for a fixed poset
$R(P, Q_n)$ for a fixed poset 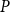 $P$ and an
$P$ and an  $n$-dimensional Boolean lattice
$n$-dimensional Boolean lattice 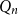 $Q_n$, as
$Q_n$, as  $n$ grows large. We show a sharp jump in behaviour of this number as a function of
$n$ grows large. We show a sharp jump in behaviour of this number as a function of  $n$ depending on whether or not
$n$ depending on whether or not 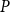 $P$ contains a copy of either a poset
$P$ contains a copy of either a poset 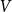 $V$, that is a poset on elements
$V$, that is a poset on elements 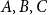 $A, B, C$ such that
$A, B, C$ such that 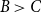 $B\gt C$,
$B\gt C$, 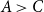 $A\gt C$, and
$A\gt C$, and 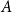 $A$ and
$A$ and 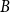 $B$ incomparable, or a poset
$B$ incomparable, or a poset 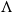 $\Lambda$, its symmetric counterpart. Specifically, we prove that if
$\Lambda$, its symmetric counterpart. Specifically, we prove that if 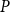 $P$ contains a copy of
$P$ contains a copy of 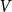 $V$ or
$V$ or 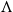 $\Lambda$ then
$\Lambda$ then 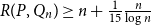 $R(P, Q_n) \geq n +\frac{1}{15} \frac{n}{\log n}$. Otherwise
$R(P, Q_n) \geq n +\frac{1}{15} \frac{n}{\log n}$. Otherwise 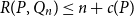 $R(P, Q_n) \leq n + c(P)$ for a constant
$R(P, Q_n) \leq n + c(P)$ for a constant 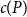 $c(P)$. This gives the first non-marginal improvement of a lower bound on poset Ramsey numbers and as a consequence gives
$c(P)$. This gives the first non-marginal improvement of a lower bound on poset Ramsey numbers and as a consequence gives 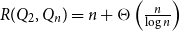 $R(Q_2, Q_n) = n + \Theta \left(\frac{n}{\log n}\right)$.
$R(Q_2, Q_n) = n + \Theta \left(\frac{n}{\log n}\right)$.
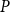
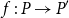
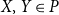
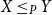
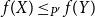
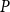
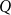
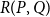
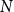
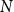
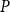
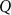
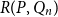
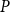

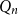


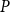
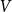
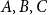
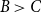
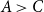
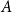
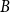
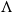
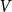
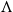
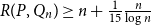
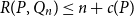
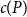
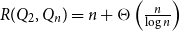
Method-of-moments estimators of a scale parameter based on samples from a coherent system
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 16 February 2023, pp. 150-167
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A simple European option pricing formula with a skew Brownian motion – ERRATUM
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 16 February 2023, p. 226
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Effectiveness of quadrivalent HPV vaccination in reducing vaccine-type and nonvaccine-type high risk HPV infection
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 February 2023, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating the share of SARS-CoV-2-immunologically naïve individuals in Germany up to June 2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 15 February 2023, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiple random walks on graphs: mixing few to cover many
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 15 February 2023, pp. 594-637
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Random walks on graphs are an essential primitive for many randomised algorithms and stochastic processes. It is natural to ask how much can be gained by running
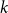 $k$ multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when
$k$ multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when 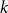 $k$ random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of
$k$ random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of 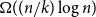 $\Omega ((n/k) \log n)$ on the stationary cover time, holding for any
$\Omega ((n/k) \log n)$ on the stationary cover time, holding for any  $n$-vertex graph
$n$-vertex graph 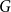 $G$ and any
$G$ and any 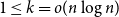 $1 \leq k =o(n\log n )$. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
$1 \leq k =o(n\log n )$. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
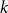
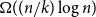

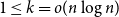
Public health interventions successfully mitigated multiple incursions of SARS-CoV-2 Delta variant in the Australian Capital Territory
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 14 February 2023, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ECT volume 39 issue 1 Cover and Back matter
-
- Journal:
- Econometric Theory / Volume 39 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Random feedback shift registers and the limit distribution for largest cycle lengths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. 559-593
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For a random binary noncoalescing feedback shift register of width
 $n$, with all
$n$, with all 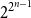 $2^{2^{n-1}}$ possible feedback functions
$2^{2^{n-1}}$ possible feedback functions 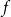 $f$ equally likely, the process of long cycle lengths, scaled by dividing by
$f$ equally likely, the process of long cycle lengths, scaled by dividing by 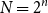 $N=2^n$, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in
$N=2^n$, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in 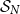 $\mathcal{S}_N$, with all
$\mathcal{S}_N$, with all 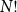 $N!$ possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.
$N!$ possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.

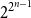
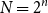
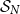
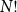
Exactly solvable urn models under random replacement schemes and their applications
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. 835-854
- Print publication:
- September 2023
-
- Article
- Export citation
ECT volume 39 issue 1 Cover and Front matter
-
- Journal:
- Econometric Theory / Volume 39 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. f1-f2
-
- Article
-
- You have access
- Export citation
APR volume 55 issue 1 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 13 February 2023, pp. b1-b2
- Print publication:
- March 2023
-
- Article
-
- You have access
- Export citation
Prevalence and persistence of Neisseria meningitidis carriage in Swedish university students
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 13 February 2023, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Searching for coherence in a fragmented field: Temporal and keywords network analysis in political science
-
- Journal:
- Network Science / Volume 11 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 13 February 2023, pp. 113-142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
APR volume 55 issue 1 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 13 February 2023, pp. f1-f2
- Print publication:
- March 2023
-
- Article
-
- You have access
- Export citation
Random multi-hooking networks
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 13 February 2023, pp. 100-114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The effectiveness of an extra-curricular lecture for STI prevention and sexual education
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 10 February 2023, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Potential analytical interferences when measuring Tmax during temperature programmed pyrolysis of hydrothermally altered volcanoclastic sediment
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 10 February 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Applied Probability Trust prizes 2022
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 09 February 2023, p. 366
- Print publication:
- March 2023
-
- Article
- Export citation
Identifying spatial and temporal suicide clusters in a Californian county
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 09 February 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
