Refine search
Actions for selected content:
53194 results in Statistics and Probability
JPR volume 60 issue 1 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 09 February 2023, pp. f1-f2
- Print publication:
- March 2023
-
- Article
-
- You have access
- Export citation
JPR volume 60 issue 1 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 09 February 2023, pp. b1-b2
- Print publication:
- March 2023
-
- Article
-
- You have access
- Export citation
Sojourn functionals for spatiotemporal Gaussian random fields with long memory
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 09 February 2023, pp. 148-165
- Print publication:
- March 2023
-
- Article
-
- You have access
- HTML
- Export citation
-
This paper addresses the asymptotic analysis of sojourn functionals of spatiotemporal Gaussian random fields with long-range dependence (LRD) in time, also known as long memory. Specifically, reduction theorems are derived for local functionals of nonlinear transformation of such fields, with Hermite rank
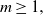 $m\geq 1,$ under general covariance structures. These results are proven to hold, in particular, for a family of nonseparable covariance structures belonging to the Gneiting class. For
$m\geq 1,$ under general covariance structures. These results are proven to hold, in particular, for a family of nonseparable covariance structures belonging to the Gneiting class. For 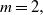 $m=2,$ under separability of the spatiotemporal covariance function in space and time, the properly normalized Minkowski functional, involving the modulus of a Gaussian random field, converges in distribution to the Rosenblatt-type limiting distribution for a suitable range of values of the long-memory parameter.
$m=2,$ under separability of the spatiotemporal covariance function in space and time, the properly normalized Minkowski functional, involving the modulus of a Gaussian random field, converges in distribution to the Rosenblatt-type limiting distribution for a suitable range of values of the long-memory parameter.
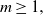
Epidemiology of herpes simplex virus type 1 and genital herpes in Australia and New Zealand: systematic review, meta-analyses and meta-regressions
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 08 February 2023, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Utilising abattoir sero-surveillance for high-impact and zoonotic pig diseases in Lao PDR
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 08 February 2023, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A dual risk model with additive and proportional gains: ruin probability and dividends
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 08 February 2023, pp. 549-580
- Print publication:
- June 2023
-
- Article
- Export citation
-
We consider a dual risk model with constant expense rate and i.i.d. exponentially distributed gains
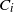 $C_i$ (
$C_i$ (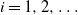 $i=1,2,\dots$) that arrive according to a renewal process with general interarrival times. We add to this classical dual risk model the proportional gain feature; that is, if the surplus process just before the ith arrival is at level u, then for
$i=1,2,\dots$) that arrive according to a renewal process with general interarrival times. We add to this classical dual risk model the proportional gain feature; that is, if the surplus process just before the ith arrival is at level u, then for 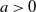 $a>0$ the capital jumps up to the level
$a>0$ the capital jumps up to the level 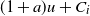 $(1+a)u+C_i$. The ruin probability and the distribution of the time to ruin are determined. We furthermore identify the value of discounted cumulative dividend payments, for the case of a Poisson arrival process of proportional gains. In the dividend calculations, we also consider a random perturbation of our basic risk process modeled by an independent Brownian motion with drift.
$(1+a)u+C_i$. The ruin probability and the distribution of the time to ruin are determined. We furthermore identify the value of discounted cumulative dividend payments, for the case of a Poisson arrival process of proportional gains. In the dividend calculations, we also consider a random perturbation of our basic risk process modeled by an independent Brownian motion with drift.
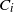
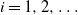
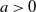
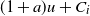
Synchronicity of viral shedding in molossid bat maternity colonies
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 08 February 2023, e47
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Tournaments and negative dependence
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 February 2023, pp. 945-954
- Print publication:
- September 2023
-
- Article
- Export citation
The number of K-tons in the coupon collector problem
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 February 2023, pp. 723-736
- Print publication:
- September 2023
-
- Article
- Export citation
-
Consider the coupon collector problem where each box of a brand of cereal contains a coupon and there are n different types of coupons. Suppose that the probability of a box containing a coupon of a specific type is
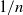 $1/n$, and that we keep buying boxes until we collect at least m coupons of each type. For
$1/n$, and that we keep buying boxes until we collect at least m coupons of each type. For 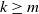 $k\geq m$ call a certain coupon a k-ton if we see it k times by the time we have seen m copies of all of the coupons. Here we determine the asymptotic distribution of the number of k-tons after we have collected m copies of each coupon for any k in a restricted range, given any fixed m. We also determine the asymptotic joint probability distribution over such values of k, and the total number of coupons collected.
$k\geq m$ call a certain coupon a k-ton if we see it k times by the time we have seen m copies of all of the coupons. Here we determine the asymptotic distribution of the number of k-tons after we have collected m copies of each coupon for any k in a restricted range, given any fixed m. We also determine the asymptotic joint probability distribution over such values of k, and the total number of coupons collected.
Coevolutionary strategies at the collective level for improved generalism
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 06 February 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random effects in dynamic network actor models
-
- Journal:
- Network Science / Volume 11 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 06 February 2023, pp. 249-266
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CONSISTENT NON-GAUSSIAN PSEUDO MAXIMUM LIKELIHOOD ESTIMATORS OF SPATIAL AUTOREGRESSIVE MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 5 / October 2024
- Published online by Cambridge University Press:
- 06 February 2023, pp. 1120-1158
-
- Article
- Export citation
-
This paper studies the non-Gaussian pseudo maximum likelihood (PML) estimation of a spatial autoregressive (SAR) model with SAR disturbances. If the spatial weights matrix
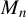 $M_{n}$ for the SAR disturbances is normalized to have row sums equal to 1 or the model reduces to a SAR model with no SAR process of disturbances, the non-Gaussian PML estimator (NGPMLE) for model parameters except the intercept term and the variance
$M_{n}$ for the SAR disturbances is normalized to have row sums equal to 1 or the model reduces to a SAR model with no SAR process of disturbances, the non-Gaussian PML estimator (NGPMLE) for model parameters except the intercept term and the variance 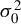 $\sigma _{0}^{2}$ of independent and identically distributed (i.i.d.) innovations in the model is consistent. Without row normalization of
$\sigma _{0}^{2}$ of independent and identically distributed (i.i.d.) innovations in the model is consistent. Without row normalization of 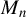 $M_{n}$, the symmetry of i.i.d. innovations leads to consistent NGPMLE for model parameters except
$M_{n}$, the symmetry of i.i.d. innovations leads to consistent NGPMLE for model parameters except 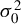 $\sigma _{0}^{2}$. With neither row normalization of
$\sigma _{0}^{2}$. With neither row normalization of 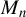 $M_{n}$ nor the symmetry of innovations, a location parameter can be added to the non-Gaussian pseudo likelihood function to achieve consistent estimation of model parameters except
$M_{n}$ nor the symmetry of innovations, a location parameter can be added to the non-Gaussian pseudo likelihood function to achieve consistent estimation of model parameters except 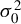 $\sigma _{0}^{2}$. The NGPMLE with no added parameter can have a significant efficiency improvement upon the Gaussian PML estimator and the generalized method of moments estimator based on linear and quadratic moments. We also propose a non-Gaussian score test for spatial dependence, which can be locally more powerful than the Gaussian score test. Monte Carlo results show that our NGPMLE with no added parameter and the score test based on it perform well in finite samples.
$\sigma _{0}^{2}$. The NGPMLE with no added parameter can have a significant efficiency improvement upon the Gaussian PML estimator and the generalized method of moments estimator based on linear and quadratic moments. We also propose a non-Gaussian score test for spatial dependence, which can be locally more powerful than the Gaussian score test. Monte Carlo results show that our NGPMLE with no added parameter and the score test based on it perform well in finite samples.
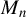
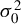
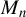
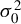
Pareto-optimal reinsurance with default risk and solvency regulation
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 03 February 2023, pp. 518-545
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A SARS-CoV-2 outbreak associated with five air force bases and a nightclub following the lifting of COVID-19-related social restrictions, United Kingdom, July-to-September 2021
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 03 February 2023, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bipartite-ness under smooth conditions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 03 February 2023, pp. 546-558
-
- Article
- Export citation
-
Given a family
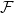 $\mathcal{F}$ of bipartite graphs, the Zarankiewicz number
$\mathcal{F}$ of bipartite graphs, the Zarankiewicz number 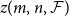 $z(m,n,\mathcal{F})$ is the maximum number of edges in an
$z(m,n,\mathcal{F})$ is the maximum number of edges in an 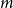 $m$ by
$m$ by  $n$ bipartite graph
$n$ bipartite graph 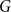 $G$ that does not contain any member of
$G$ that does not contain any member of 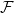 $\mathcal{F}$ as a subgraph (such
$\mathcal{F}$ as a subgraph (such 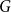 $G$ is called
$G$ is called 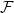 $\mathcal{F}$-free). For
$\mathcal{F}$-free). For 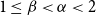 $1\leq \beta \lt \alpha \lt 2$, a family
$1\leq \beta \lt \alpha \lt 2$, a family 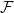 $\mathcal{F}$ of bipartite graphs is
$\mathcal{F}$ of bipartite graphs is 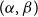 $(\alpha,\beta )$-smooth if for some
$(\alpha,\beta )$-smooth if for some 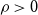 $\rho \gt 0$ and every
$\rho \gt 0$ and every 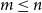 $m\leq n$,
$m\leq n$, 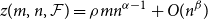 $z(m,n,\mathcal{F})=\rho m n^{\alpha -1}+O(n^\beta )$. Motivated by their work on a conjecture of Erdős and Simonovits on compactness and a classic result of Andrásfai, Erdős and Sós, Allen, Keevash, Sudakov and Verstraëte proved that for any
$z(m,n,\mathcal{F})=\rho m n^{\alpha -1}+O(n^\beta )$. Motivated by their work on a conjecture of Erdős and Simonovits on compactness and a classic result of Andrásfai, Erdős and Sós, Allen, Keevash, Sudakov and Verstraëte proved that for any 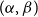 $(\alpha,\beta )$-smooth family
$(\alpha,\beta )$-smooth family 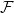 $\mathcal{F}$, there exists
$\mathcal{F}$, there exists 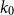 $k_0$ such that for all odd
$k_0$ such that for all odd 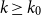 $k\geq k_0$ and sufficiently large
$k\geq k_0$ and sufficiently large  $n$, any
$n$, any  $n$-vertex
$n$-vertex 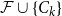 $\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least
$\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least 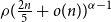 $\rho (\frac{2n}{5}+o(n))^{\alpha -1}$ is bipartite. In this paper, we strengthen their result by showing that for every real
$\rho (\frac{2n}{5}+o(n))^{\alpha -1}$ is bipartite. In this paper, we strengthen their result by showing that for every real 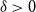 $\delta \gt 0$, there exists
$\delta \gt 0$, there exists 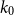 $k_0$ such that for all odd
$k_0$ such that for all odd 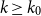 $k\geq k_0$ and sufficiently large
$k\geq k_0$ and sufficiently large  $n$, any
$n$, any  $n$-vertex
$n$-vertex 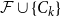 $\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least
$\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least 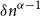 $\delta n^{\alpha -1}$ is bipartite. Furthermore, our result holds under a more relaxed notion of smoothness, which include the families
$\delta n^{\alpha -1}$ is bipartite. Furthermore, our result holds under a more relaxed notion of smoothness, which include the families 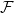 $\mathcal{F}$ consisting of the single graph
$\mathcal{F}$ consisting of the single graph 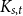 $K_{s,t}$ when
$K_{s,t}$ when 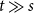 $t\gg s$. We also prove an analogous result for
$t\gg s$. We also prove an analogous result for 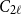 $C_{2\ell }$-free graphs for every
$C_{2\ell }$-free graphs for every 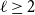 $\ell \geq 2$, which complements a result of Keevash, Sudakov and Verstraëte.
$\ell \geq 2$, which complements a result of Keevash, Sudakov and Verstraëte.
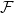
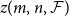
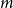

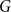
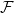
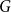
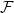
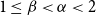
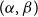
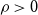
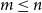
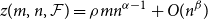
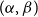
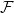
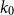
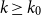


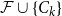
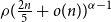
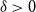
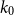
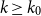


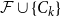
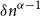
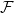
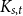
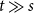
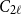
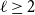
Multiphase segmentation of digital material images
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 02 February 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Multiphase segmentation of pore-scale features and identification of mineralogy from digital images of materials is critical for many applications in the natural resources sector. However, the materials involved (rocks, catalyst pellets, and synthetic alloys) have complex and unpredictable composition. Algorithms that can be extended for multiphase segmentation of images of these materials are relatively few and very human-intensive. Challenges lie in designing algorithms that are context free, can function with less training data, and can handle the unpredictability of material composition. Semisupervised algorithms have shown success in classification in situations characterized by limited training data; they use unlabeled data in addition to labeled data to produce classification. The segmentation obtained can be more accurate than fully supervised learning approaches. This work proposes using a semisupervised clustering algorithm named Continuous Iterative Guided Spectral Class Rejection (CIGSCR) toward multiphase segmentation of digital scans of materials. CIGSCR harnesses spectral cohesion, splitting the intensity histogram of the input image down into clusters. This splitting provides the foundation for classification strategies that can be implemented as postprocessing steps to get the final segmentation. One classification strategy is presented. Micro-computed tomography scans of rocks are used to present the results. It is demonstrated that CIGSCR successfully enables distinguishing features up to the uniqueness of grayscale values, and extracting features present in full image stacks (3D), including features not presented in the training data. Results including instances of success and limitations are presented. Scalability to data sizes
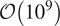 $ \mathcal{O}\left({10}^9\right) $ voxels is briefly discussed.
$ \mathcal{O}\left({10}^9\right) $ voxels is briefly discussed.
Monotonicity in undirected networks
-
- Journal:
- Network Science / Volume 11 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 02 February 2023, pp. 351-373
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Molecular epidemiology of Streptococcus pneumoniae isolated from children with community-acquired pneumonia under 5 years in Chengdu, China – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 02 February 2023, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ability of epidemiological studies to monitor HPV post-vaccination dynamics: a simulation study
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 02 February 2023, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Socioeconomic and ethnic inequalities in incidence and severity of enteric fever in England 2015–2019: analysis of a national enhanced surveillance system
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 01 February 2023, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
