Refine search
Actions for selected content:
53194 results in Statistics and Probability
Measuring non-exchangeable tail dependence using tail copulas
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 466-487
- Print publication:
- May 2023
-
- Article
- Export citation
The conundrum in smart city governance: Interoperability and compatibility in an ever-growing ecosystem of digital twins
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 28 February 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A new lifetime distribution by maximizing entropy: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 28 February 2023, pp. 189-206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Robustness of iterated function systems of Lipschitz maps
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 921-944
- Print publication:
- September 2023
-
- Article
- Export citation
-
Let
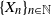 $\{X_n\}_{n\in{\mathbb{N}}}$ be an
$\{X_n\}_{n\in{\mathbb{N}}}$ be an 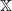 ${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as
${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as 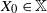 $X_0 \in {\mathbb{X}}$ and for
$X_0 \in {\mathbb{X}}$ and for 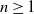 $n\geq 1$,
$n\geq 1$, 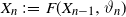 $X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where
$X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where 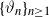 $\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution
$\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution 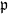 $\mathfrak{p}$,
$\mathfrak{p}$, 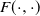 $F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and
$F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and 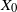 $X_0$ is independent of
$X_0$ is independent of 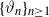 $\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and
$\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and 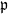 $\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of
$\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of 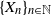 $\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of
$\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of 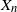 $X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
$X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
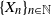
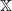
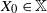
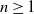
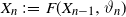
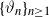
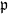
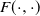
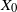
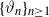
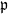
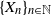
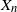
Usefulness of linked data for infectious disease events: a systematic review
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 February 2023, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Obtaining molecular hydrogen from water radiolysis in the nano-SiO2(d = 20 nm)/H2O system under the influence of γ-quanta
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 27 February 2023, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transporting monovalent rotavirus vaccine efficacy estimates to an external target population: a secondary analysis of data from a randomised controlled trial in Malawi
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 February 2023, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
First checklist triggering the inventory of marine fish ectoparasites in the Syrian coast (Eastern Mediterranean)
-
- Journal:
- Experimental Results / Accepted manuscript
- Published online by Cambridge University Press:
- 27 February 2023, pp. 1-17
-
- Article
-
- You have access
- Open access
- Export citation
Epidemiological characteristics and spatiotemporal analysis of mumps at township level in Wuhan, China, 2005–2019
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 27 February 2023, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Overlap times in the infinite server queue
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 23 February 2023, pp. 21-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Imagine, you enter a grocery store to buy food. How many people do you overlap with in this store? How much time do you overlap with each person in the store? In this paper, we answer these questions by studying the overlap times between customers in the infinite server queue. We compute in closed form the steady-state distribution of the overlap time between a pair of customers and the distribution of the number of customers that an arriving customer will overlap with. Finally, we define a residual process that counts the number of overlapping customers that overlap in the queue for at least
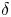 $\delta$ time units and compute its distribution.
$\delta$ time units and compute its distribution.
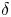
On the cumulant transforms for Hawkes processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 23 February 2023, pp. 528-541
- Print publication:
- June 2023
-
- Article
- Export citation
Tail index partition-based rules extraction with application to tornado damage insurance
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 22 February 2023, pp. 258-284
- Print publication:
- May 2023
-
- Article
- Export citation
A calendar year mortality model in continuous time
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 53 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 22 February 2023, pp. 351-376
- Print publication:
- May 2023
-
- Article
- Export citation
Is early time to positivity of blood culture associated with clinical prognosis in patients with Klebsiella pneumoniae bloodstream infection?
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 21 February 2023, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal proportional reinsurance to maximize an insurer’s exponential utility under unobservable drift
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 21 February 2023, pp. 874-894
- Print publication:
- September 2023
-
- Article
- Export citation
Demographic and clinical characteristics of children and adolescents hospitalised with laboratory-confirmed COVID-19 in the Tel-Aviv District, Israel, 2020–2022
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 21 February 2023, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Explainable machine learning for public policy: Use cases, gaps, and research directions
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 20 February 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A closed-form approximation for pricing spread options on futures under a mean-reverting spot price model with multiscale stochastic volatility
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 20 February 2023, pp. 168-188
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transmission trends of the global COVID-19 pandemic with combined effects of adaptive behaviours and vaccination
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 20 February 2023, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Characteristics of patients with SARS-COV-2 PCR re-positivity after recovering from COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 17 February 2023, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
