Refine search
Actions for selected content:
53194 results in Statistics and Probability
Cumulative and undiagnosed SARS-CoV-2 infection among the staff of a medical research centre in Tokyo after the emergence of variants
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 08 March 2023, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On hybrid tree-based methods for short-term insurance claims
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 08 March 2023, pp. 597-620
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An efficient method for generating a discrete uniform distribution using a biased random source
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 March 2023, pp. 1069-1078
- Print publication:
- September 2023
-
- Article
- Export citation
-
We present an efficient algorithm to generate a discrete uniform distribution on a set of p elements using a biased random source for p prime. The algorithm generalizes Von Neumann’s method and improves the computational efficiency of Dijkstra’s method. In addition, the algorithm is extended to generate a discrete uniform distribution on any finite set based on the prime factorization of integers. The average running time of the proposed algorithm is overall sublinear:
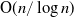 $\operatorname{O}\!(n/\log n)$.
$\operatorname{O}\!(n/\log n)$.
A network community detection method with integration of data from multiple layers and node attributes
-
- Journal:
- Network Science / Volume 11 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 March 2023, pp. 374-396
-
- Article
- Export citation
Degree distributions in recursive trees with fitnesses
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 06 March 2023, pp. 407-443
- Print publication:
- June 2023
-
- Article
- Export citation
-
We study a general model of recursive trees where vertices are equipped with independent weights and at each time-step a vertex is sampled with probability proportional to its fitness function, which is a function of its weight and degree, and connects to
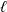 $\ell$ new-coming vertices. Under a certain technical assumption, applying the theory of Crump–Mode–Jagers branching processes, we derive formulas for the limiting distributions of the proportion of vertices with a given degree and weight, and proportion of edges with endpoint having a certain weight. As an application of this theorem, we rigorously prove observations of Bianconi related to the evolving Cayley tree (Phys. Rev. E 66, paper no. 036116, 2002). We also study the process in depth when the technical condition can fail in the particular case when the fitness function is affine, a model we call ‘generalised preferential attachment with fitness’. We show that this model can exhibit condensation, where a positive proportion of edges accumulates around vertices with maximal weight, or, more drastically, can have a degenerate limiting degree distribution, where the entire proportion of edges accumulates around these vertices. Finally, we prove stochastic convergence for the degree distribution under a different assumption of a strong law of large numbers for the partition function associated with the process.
$\ell$ new-coming vertices. Under a certain technical assumption, applying the theory of Crump–Mode–Jagers branching processes, we derive formulas for the limiting distributions of the proportion of vertices with a given degree and weight, and proportion of edges with endpoint having a certain weight. As an application of this theorem, we rigorously prove observations of Bianconi related to the evolving Cayley tree (Phys. Rev. E 66, paper no. 036116, 2002). We also study the process in depth when the technical condition can fail in the particular case when the fitness function is affine, a model we call ‘generalised preferential attachment with fitness’. We show that this model can exhibit condensation, where a positive proportion of edges accumulates around vertices with maximal weight, or, more drastically, can have a degenerate limiting degree distribution, where the entire proportion of edges accumulates around these vertices. Finally, we prove stochastic convergence for the degree distribution under a different assumption of a strong law of large numbers for the partition function associated with the process.
Epidemiology of invasive meningococcal disease worldwide from 2010–2019: a literature review
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 06 March 2023, e57
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Data Management for Social Scientists
- From Files to Databases
-
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023
-
- Book
-
- You have access
- Open access
- Export citation
Validating the behavioral Defining Issues Test across different genders, political, and religious affiliations
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 March 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A model for an epidemic with contact tracing and cluster isolation, and a detection paradox
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 03 March 2023, pp. 1079-1095
- Print publication:
- September 2023
-
- Article
- Export citation
Chinese oats in temperate Bhutan: Results of field experiments
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 March 2023, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Validation of Risk Management Models for Financial Institutions
- Theory and Practice
-
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023

The Conway–Maxwell–Poisson Distribution
-
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023
Characteristics, treatment and care of pregnant women living with hepatitis B in England: findings from a national audit
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 02 March 2023, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the probability of rumour survival among sceptics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 02 March 2023, pp. 1096-1111
- Print publication:
- September 2023
-
- Article
- Export citation
Is remote measurement a better assessment of internet censorship than expert analysis? Analyzing tradeoffs for international donors and advocacy organizations of current data and methodologies
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 02 March 2023, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An iterative regulatory process for robot governance
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 01 March 2023, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fiscal data in text: Information extraction from audit reports using Natural Language Processing
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 28 February 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Making the invisible visible: using national surveillance data to identify people experiencing homelessness in England with COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 28 February 2023, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An attribution analysis of investment risk sharing in collective defined contribution schemes
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 2 / July 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 385-414
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On ordered system signature and its dynamic version for coherent systems with applications
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 982-1002
- Print publication:
- September 2023
-
- Article
- Export citation
