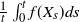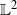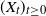Refine search
Actions for selected content:
53194 results in Statistics and Probability
Part V - Conclusion
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 207-208
-
- Chapter
-
- You have access
- Open access
- Export citation
Part I - Introduction
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 1-2
-
- Chapter
-
- You have access
- Open access
- Export citation
Dedication
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp v-vi
-
- Chapter
- Export citation
1 - Motivation
- from Part I - Introduction
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 3-13
-
- Chapter
-
- You have access
- Open access
- Export citation
Appendix B: - Mergers and Acquisition list
- from 15 - Validation of Risk Aggregation in Economic Capital Models
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 419-421
-
- Chapter
- Export citation
Index
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 327-330
-
- Chapter
- Export citation
Appendix B - An Example on Maturation Effect and CECL Loss Computations
- from 12 - Validation of Models Used by Banks to Estimate Their Allowance for Loan and Lease Losses
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 324-327
-
- Chapter
- Export citation
Figures
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp xii-xiii
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp i-iv
-
- Chapter
- Export citation
3 - Distributional Extensions and Generalities
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 71-123
-
- Chapter
- Export citation
7 - COM–Poisson Models for Serially Dependent Count Data
-
- Book:
- The Conway–Maxwell–Poisson Distribution
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 251-283
-
- Chapter
- Export citation
10 - Issues in the Validation of Wholesale Credit Risk Models
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 232-262
-
- Chapter
- Export citation
16 - Model Validation of Interest Rate Risk (Banking Book) Models
-
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp 422-438
-
- Chapter
- Export citation
Figures
-
- Book:
- Validation of Risk Management Models for Financial Institutions
- Published online:
- 02 March 2023
- Print publication:
- 09 March 2023, pp vii-ix
-
- Chapter
- Export citation
11 - Spatial Data
- from Part IV - Special Types of Data
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 147-165
-
- Chapter
-
- You have access
- Open access
- Export citation
5 - Managing Data in Spreadsheets
- from Part II - Data in Files
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp 59-73
-
- Chapter
-
- You have access
- Open access
- Export citation
Frontmatter
-
- Book:
- Data Management for Social Scientists
- Published online:
- 03 March 2023
- Print publication:
- 09 March 2023, pp i-iv
-
- Chapter
-
- You have access
- Open access
- Export citation
Covid-19 and the effectiveness of ERM frameworks
-
- Journal:
- British Actuarial Journal / Volume 28 / 2023
- Published online by Cambridge University Press:
- 08 March 2023, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sandwiched SDEs with unbounded drift driven by Hölder noises
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 08 March 2023, pp. 927-964
- Print publication:
- September 2023
-
- Article
- Export citation
-
We study a stochastic differential equation with an unbounded drift and general Hölder continuous noise of order
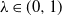 $\lambda \in (0,1)$. The corresponding equation turns out to have a unique solution that, depending on a particular shape of the drift, either stays above some continuous function or has continuous upper and lower bounds. Under some mild assumptions on the noise, we prove that the solution has moments of all orders. In addition, we provide its connection to the solution of some Skorokhod reflection problem. As an illustration of our results and motivation for applications, we also suggest two stochastic volatility models which we regard as generalizations of the CIR and CEV processes. We complete the study by providing a numerical scheme for the solution.
$\lambda \in (0,1)$. The corresponding equation turns out to have a unique solution that, depending on a particular shape of the drift, either stays above some continuous function or has continuous upper and lower bounds. Under some mild assumptions on the noise, we prove that the solution has moments of all orders. In addition, we provide its connection to the solution of some Skorokhod reflection problem. As an illustration of our results and motivation for applications, we also suggest two stochastic volatility models which we regard as generalizations of the CIR and CEV processes. We complete the study by providing a numerical scheme for the solution.
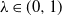
An ergodic theorem for asymptotically periodic time-inhomogeneous Markov processes, with application to quasi-stationarity with moving boundaries
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 08 March 2023, pp. 672-700
- Print publication:
- June 2023
-
- Article
- Export citation
-
This paper deals with ergodic theorems for particular time-inhomogeneous Markov processes, whose time-inhomogeneity is asymptotically periodic. Under a Lyapunov/minorization condition, it is shown that, for any measurable bounded function f, the time average
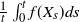 $\frac{1}{t} \int_0^t f(X_s)ds$ converges in
$\frac{1}{t} \int_0^t f(X_s)ds$ converges in 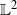 $\mathbb{L}^2$ towards a limiting distribution, starting from any initial distribution for the process
$\mathbb{L}^2$ towards a limiting distribution, starting from any initial distribution for the process 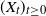 $(X_t)_{t \geq 0}$. This convergence can be improved to an almost sure convergence under an additional assumption on the initial measure. This result is then applied to show the existence of a quasi-ergodic distribution for processes absorbed by an asymptotically periodic moving boundary, satisfying a conditional Doeblin condition.
$(X_t)_{t \geq 0}$. This convergence can be improved to an almost sure convergence under an additional assumption on the initial measure. This result is then applied to show the existence of a quasi-ergodic distribution for processes absorbed by an asymptotically periodic moving boundary, satisfying a conditional Doeblin condition.